gerenciar conectores em LakeFlow Connect
Os conectores gerenciar em LakeFlow Connect estão em vários estados de liberação.
Esta página fornece uma visão geral dos conectores gerenciados no Databricks Lakeflow Connect para ingestão de dados de aplicativos SaaS e bancos de dados. O pipeline de ingestão resultante é governado pelo Unity Catalog e é alimentado por compute serverless e LakeFlow Pipelines. Conectores gerenciados aproveitam leituras e gravações incrementais eficientes para tornar a ingestão de dados mais rápida, escalável e econômica, enquanto seus dados permanecem atualizados para consumo downstream.
Tipos de conectores
-
- conectores comunitários
- Ingerir uso de dados código aberto, conectores construídos pela comunidade.
-
- Conectores de banco de dados (CDC)
- Ingira dados de bancos de dados relacionais, incluindo MySQL, PostgreSQL e SQL Server usando captura de dados de alterações (CDC).
-
- Conectores de fonte de arquivo
- Ingerir arquivos não estruturados e estruturados de serviços de armazenamento de arquivos corporativos, incluindo Google Drive e SharePoint.
-
- Conectores baseados em consultas
- Ingerir dados de bancos de dados consultando a origem diretamente, sem exigir a configuração de captura de dados de alterações (CDC).
-
- Conectores SaaS
- Ingerir dados de aplicativos SaaS corporativos, incluindo Salesforce, HubSpot, Jira, Workday e muito mais.
-
- Conectores de transmissão
- Ingerir continuamente dados de barramentos de mensagens e fontes de transmissão de eventos, incluindo RabbitMQ.
Arquitetura
Cada tipo de conector tem um conjunto distinto de componentes. Conectores SaaS usam uma conexão, um pipeline de ingestão e tabelas de destino. Conectores de banco de dados também incluem um gateway de ingestão e armazenamento de preparação para oferecer suporte à captura contínua de alterações. Para detalhes, consulte Conectores SaaS Gerenciados e Conectores de Banco de Dados Gerenciados.
Componentes de conexão baseados em consulta
Um conector baseado em consultas consulta o banco de dados de origem diretamente em um programador, sem um gateway ou armazenamento temporário. Para uma visão geral de como funcionam os conectores baseados em consultas, consulte Conectores baseados em consultas.
Componente | Descrição |
|---|---|
Conexão | Um objeto protegível do Unity Catalog que armazena detalhes de autenticação para o banco de dados de origem. Pode ser uma conexão direta Unity Catalog (para ingestão de conexões externas) ou um catálogo externo Unity Catalog (para ingestão de catálogos externos usando o Lakehouse Federation). |
Ingestão pipeline | Um pipeline que consulta diretamente o banco de dados de origem e grava os resultados em tabelas de transmissão. A execução pipeline em compute serverless é feita por default. |
Tabelas de destino | As tabelas de transmissão são onde o pipeline de ingestão grava os dados. |
Componentes do conector de transmissão
Um conector de transmissão lê mensagens continuamente de um barramento de mensagens ou de uma fonte de transmissão de eventos e as grava em tabelas de transmissão. Para uma visão geral de como os conectores de transmissão funcionam, veja Conectores de transmissão gerenciados.
Componente | Descrição |
|---|---|
Conexão | Um objeto protegível do Unity Catalog que armazena o endpoint de origem e as credenciais de autenticação para sua origem de transmissão. O conector gerenciado usa esta conexão para autenticar sem exigir credenciais na configuração do pipeline. |
Ingestão pipeline | Um pipeline que lê continuamente mensagens da fonte de transmissão e grava os resultados em tabelas de transmissão. O pipeline executa em compute serverless. |
Tabelas de destino | As tabelas de transmissão são onde o pipeline de ingestão grava os dados. |
orquestração
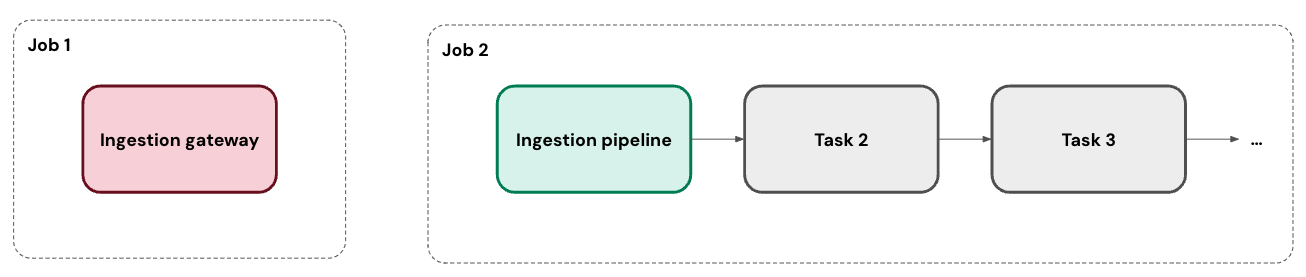
O senhor pode executar sua ingestão pipeline em um ou mais programas personalizados. Para cada programa que o senhor adicionar a um pipeline, o LakeFlow Connect cria automaticamente um Job para ele. A ingestão pipeline é uma tarefa dentro do trabalho. Opcionalmente, o senhor pode adicionar mais tarefas ao trabalho.
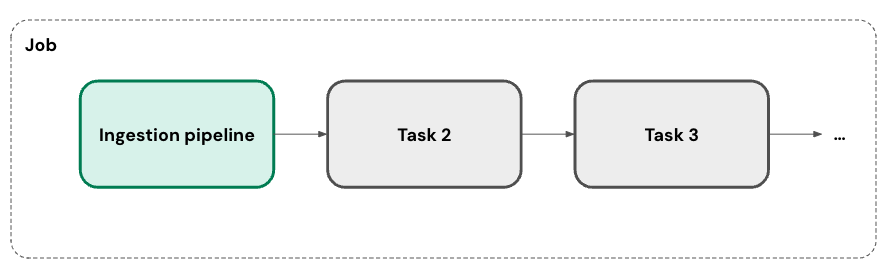
Para conectores de banco de dados, o gateway de ingestão é executado em seu próprio Job como uma tarefa contínua.
Ingestão incremental
LakeFlow Connect usa a ingestão incremental para melhorar a eficiência do pipeline. Na primeira execução de seu pipeline, ele ingere todos os dados selecionados da fonte. Paralelamente, ele rastreia as alterações nos dados de origem. Em cada execução subsequente do pipeline, ele usa esse acompanhamento de alterações para ingerir apenas os dados que foram alterados em relação à execução anterior, quando possível.
A abordagem exata depende do que está disponível em sua fonte de dados. Por exemplo, o senhor pode usar tanto o acompanhamento de alterações quanto a captura de dados de alterações (CDC) (CDC) com SQL Server. Por outro lado, o conector Salesforce seleciona uma coluna de cursor em uma lista de opções.
Algumas fontes ou tabelas específicas não oferecem suporte à ingestão incremental no momento. A Databricks planeja expandir a cobertura para suporte incremental.
Trabalho em rede
Há várias opções para se conectar a um aplicativo ou banco de dados SaaS.
- Os conectores para aplicativos SaaS acessam as APIs da fonte. Eles também são automaticamente compatíveis com os controles de saída do site serverless.
- Os conectores para bancos de dados cloud podem se conectar à fonte por meio de um Link Privado. Alternativamente, se o seu workspace tiver uma Rede Virtual (VNet) ou uma Nuvem Privada Virtual (VPC) que esteja emparelhada com a VNet ou VPC que hospeda seu banco de dados, você poderá implantar o gateway dentro dela.
- Os conectores para bancos de dados locais podem se conectar usando serviços como AWS Direct Connect e Azure ExpressRoute.
Implantação
Você pode implantar um pipeline de ingestão usando Declarative Automation Bundles, que permitem a implementação de práticas recomendadas como controle de versão, revisão de código, testes e integração e entrega contínuas (CI/CD). Os bundles são gerenciados usando a CLI Databricks e podem ser executados em diferentes ambientes de trabalho de destino, como desenvolvimento, teste e produção.
Recuperação de falhas
Como um serviço totalmente gerenciado, o LakeFlow Connect visa à recuperação automática de problemas sempre que possível. Por exemplo, quando um conector falha, ele tenta novamente automaticamente com recuo exponencial.
No entanto, é possível que um erro exija sua intervenção (por exemplo, quando as credenciais expiram). Nesses casos, o conector tenta evitar a perda de dados armazenando a última posição do cursor. Ele pode, então, retomar a partir dessa posição na próxima execução do pipeline, quando possível.
monitoramento
LakeFlow Connect oferece alertas e monitoramento robustos para ajudar você a manter seu oleoduto em boas condições. Isso inclui logs de eventos, logs cluster , métricas de integridade pipeline e métricas de qualidade de dados. Você também pode usar a tabela system.billing.usage para rastrear custos e monitorar o uso do pipeline. Consulte Monitorar custo pipeline de ingestão.
Para conectores de banco de dados, você pode monitorar o progresso do gateway em tempo real usando logs de eventos. Consulte Monitorar o progresso do gateway de ingestão com logsde eventos.
conectores comunitários
Os conectores da comunidade estendem LakeFlow Connect a fontes sem suporte do conector gerenciador. Eles são construídos e mantidos pela comunidade. Você pode usar um conector existente ou criar o seu próprio. Consulte os conectores comunitários no LakeFlow Connect.
Dependência de serviços externos
Databricks SaaS Os conectores de aplicativos, bancos de dados e outros conectores totalmente gerenciados dependem da acessibilidade, da compatibilidade e da estabilidade do aplicativo, do banco de dados ou do serviço externo ao qual se conectam. Databricks não controla esses serviços externos e, portanto, tem influência limitada (se houver) sobre suas alterações, atualizações e manutenção.
Se alterações, interrupções ou circunstâncias relacionadas a um serviço externo impedirem ou tornarem impraticáveis as operações de um conector, o site Databricks poderá descontinuar ou deixar de manter esse conector. A Databricks envidará esforços razoáveis para notificar os clientes sobre a descontinuação ou interrupção da manutenção, incluindo atualizações da documentação aplicável.