Ingerir dados do SQL Server
Esta página descreve como importar dados do SQL Server e carregá-los no Databricks usando LakeFlow Connect. O conector SQL Server oferece suporte aos bancos de dados SQL Azure , à Instância de Gerenciamento Azure SQL e aos bancos de dados SQL Amazon RDS. Isso inclui o SQL Server executado em máquinas virtuais (VMs) do Azure e no Amazon EC2. O conector também oferece suporte SQL Server on-premises usando as redes Azure ExpressRoute e AWS Direct Connect.
Antes de começar
Para criar um gateway de ingestão e um pipeline de ingestão, você deve atender aos seguintes requisitos:
-
Seu workspace está habilitado para Unity Catalog.
-
O compute sem servidor está habilitado para o seu workspace. Consulte os requisitos do compute sem servidor.
-
Se você planeja criar uma conexão: Você tem privilégios
CREATE CONNECTIONna metastore.Se o seu conector for compatível com a criação de pipeline com base na interface do usuário, o senhor poderá criar a conexão e o pipeline ao mesmo tempo, concluindo as etapas desta página. No entanto, se o senhor usar a criação de pipeline baseada em API, deverá criar a conexão no Catalog Explorer antes de concluir as etapas desta página. Consulte Conectar-se a fontes de ingestão de gerenciar.
-
Se você planeja usar uma conexão existente: Você tem privilégios
USE CONNECTIONouALL PRIVILEGESna conexão. -
Você tem privilégios
USE CATALOGno catálogo de destino. -
Você tem privilégios
USE SCHEMA,CREATE TABLEeCREATE VOLUMEem um esquema existente ou privilégiosCREATE SCHEMAno catálogo de destino. -
O senhor tem acesso a uma instância primária do SQL Server. Os recursos de acompanhamento de alterações e captura de dados de alterações (CDC) não são suportados em réplicas de leitura ou instâncias secundárias.
-
Permissões irrestritas para criar clusters ou uma política personalizada (somente API). Uma política personalizada para o gateway deve atender aos seguintes requisitos:
-
Família: Job compute
-
A família de políticas substitui:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
} -
Databricks recomenda especificar o menor número possível de nós worker para gateways de ingestão porque eles não afetam o desempenho do gateway. A política compute a seguir permite que o Databricks dimensione o gateway de ingestão para atender às necessidades de sua carga de trabalho. O requisito mínimo é de 8 núcleos para permitir a extração eficiente e eficiente de dados do seu banco de dados de origem.
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "r5n.16xlarge"
},
"node_type_id": {
"type": "fixed",
"value": "m5n.large"
}
}
Para obter mais informações sobre a política de cluster, consulte Selecionar uma política de compute.
-
Para ingerir a partir do SQL Server, o senhor também deve concluir a configuração da fonte.
Opção 1: UI da Databricks
Os usuários administradores podem criar uma conexão e um pipeline ao mesmo tempo na interface do usuário. Essa é a maneira mais simples de criar um pipeline de ingestão gerencial.
-
Na barra lateral do site Databricks workspace, clique em ingestão de dados .
-
Na página Adicionar dados , em Conectores do Databricks , clique em SQL Server .
O assistente de ingestão é aberto.
-
Na página Ingestion Gateway do assistente, insira um nome exclusivo para o gateway.
-
Selecione um catálogo e um esquema para os dados de ingestão intermediária e clique em Avançar.
-
Na página Ingestion pipeline (Pipeline de ingestão ), digite um nome exclusivo para o pipeline.
-
Em Catálogo de destino , selecione um catálogo para armazenar os dados ingeridos.
-
Selecione a conexão do Unity Catalog que armazena as credenciais necessárias para acessar os dados de origem.
Se não houver conexões existentes com a origem, clique em Criar conexão e insira os detalhes de autenticação obtidos na configuração da fonte. Você deve ter privilégios
CREATE CONNECTIONna metastore. -
Clique em Create pipeline (Criar pipeline) e continue .
-
Na página Origem , selecione as tabelas a serem ingeridas.
-
Opcionalmente, altere a configuração default história acompanhamento. Para obter mais informações, consulte Enable história acompanhamento (SCD type 2).
-
Clique em Avançar .
-
Na página Destination (Destino ), selecione o catálogo e o esquema do Unity Catalog para gravar.
Se você não quiser usar um esquema existente, clique em Criar esquema . Você deve ter privilégios
USE CATALOGeCREATE SCHEMAno catálogo principal. -
Clique em Salvar e continuar .
-
(Opcional) Na página Settings (Configurações ), clique em Create programar (Criar programa ). Defina a frequência para refresh as tabelas de destino.
-
(Opcional) Defina as notificações do site email para o sucesso ou fracasso das operações do pipeline.
-
Clique em Save e execute pipeline .
Opção 2: Outras interfaces
Antes de fazer a ingestão usando Databricks ativo Bundles, Databricks APIs, Databricks SDKs ou o Databricks CLI, o senhor deve ter acesso a uma conexão Unity Catalog existente. Para obter instruções, consulte Conectar-se a fontes de ingestão de gerenciar.
Crie o catálogo e o esquema de preparação
O catálogo de teste e o esquema podem ser iguais aos do catálogo e do esquema de destino. O catálogo de teste não pode ser um catálogo estrangeiro.
- CLI
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
Criar o gateway e o pipeline de ingestão
O gateway de ingestão extrai o Snapshot e altera os dados do banco de dados de origem e os armazena no volume de preparação Unity Catalog. O senhor deve executar o gateway como um pipeline contínuo. Isso ajuda a acomodar quaisquer políticas de retenção de log de alterações que o senhor tenha no banco de dados de origem.
A ingestão pipeline aplica o Snapshot e altera os dados do volume de preparação nas tabelas de transmissão de destino.
- Databricks Asset Bundles
- Notebook
- CLI
Este tab descreve como implantar uma ingestão pipeline usando Databricks ativo Bundles. Os bundles podem conter definições YAML de Job e tarefa, são gerenciados usando o Databricks CLI e podem ser compartilhados e executados em diferentes espaços de trabalho de destino (como desenvolvimento, preparação e produção). Para obter mais informações, consulte Databricks ativo Bundles.
-
Crie um novo pacote usando a CLI do Databricks:
Bashdatabricks bundle init -
Adicione dois novos arquivos de recurso ao pacote:
- Um arquivo de definição de pipeline (
resources/sqlserver_pipeline.yml). - Um arquivo de fluxo de trabalho que controla a frequência da ingestão de dados (
resources/sqlserver.yml).
Veja a seguir um exemplo de arquivo
resources/sqlserver_pipeline.yml:YAMLvariables:
# Common variables used multiple places in the DAB definition.
gateway_name:
default: sqlserver-gateway
dest_catalog:
default: main
dest_schema:
default: ingest-destination-schema
resources:
pipelines:
gateway:
name: ${var.gateway_name}
gateway_definition:
connection_name: <sqlserver-connection>
gateway_storage_catalog: main
gateway_storage_schema: ${var.dest_schema}
gateway_storage_name: ${var.gateway_name}
target: ${var.dest_schema}
catalog: ${var.dest_catalog}
pipeline_sqlserver:
name: sqlserver-ingestion-pipeline
ingestion_definition:
ingestion_gateway_id: ${resources.pipelines.gateway.id}
objects:
# Modify this with your tables!
- table:
# Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item.
source_catalog: test
source_schema: ingestion_demo
source_table: lineitem
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
- schema:
# Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination
# table name will be the same as it is on the source.
source_catalog: test
source_schema: ingestion_whole_schema
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
target: ${var.dest_schema}
catalog: ${var.dest_catalog}Veja a seguir um exemplo de arquivo
resources/sqlserver_job.yml:YAMLresources:
jobs:
sqlserver_dab_job:
name: sqlserver_dab_job
trigger:
# Run this job every day, exactly one day from the last run
# See https://docs.databricks.com/api/workspace/jobs/create#trigger
periodic:
interval: 1
unit: DAYS
email_notifications:
on_failure:
- <email-address>
tasks:
- task_key: refresh_pipeline
pipeline_task:
pipeline_id: ${resources.pipelines.pipeline_sqlserver.id} - Um arquivo de definição de pipeline (
-
implantado o pipeline usando o Databricks CLI:
Bashdatabricks bundle deploy
Atualize a célula Configuration no Notebook a seguir com a conexão de origem, o catálogo de destino, o esquema de destino e as tabelas a serem ingeridas da origem.
Criar gateway e pipeline de ingestão
Para criar o gateway:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
Para criar o pipeline de ingestão:
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
começar, programar e definir alertas em seu pipeline
O senhor pode criar um programa para o pipeline na página de detalhes do pipeline.
-
Depois que o pipeline tiver sido criado, acesse novamente o Databricks workspace e clique em pipeline .
O novo pipeline aparece na lista pipeline.
-
Para acessar view os detalhes de pipeline, clique no nome pipeline.
-
Na página de detalhes do pipeline, o senhor pode programar o pipeline clicando em programar .
-
Para definir notificações no pipeline, clique em Settings (Configurações ) e, em seguida, adicione uma notificação.
Para cada programa que o senhor adicionar a um pipeline, o LakeFlow Connect cria automaticamente um Job para ele. A ingestão pipeline é uma tarefa dentro do trabalho. Opcionalmente, o senhor pode adicionar mais tarefas ao trabalho.
Verificar se a ingestão de dados foi bem-sucedida
A lista view na página de detalhes pipeline mostra o número de registros processados à medida que os dados são ingeridos. Esses números refresh automaticamente.
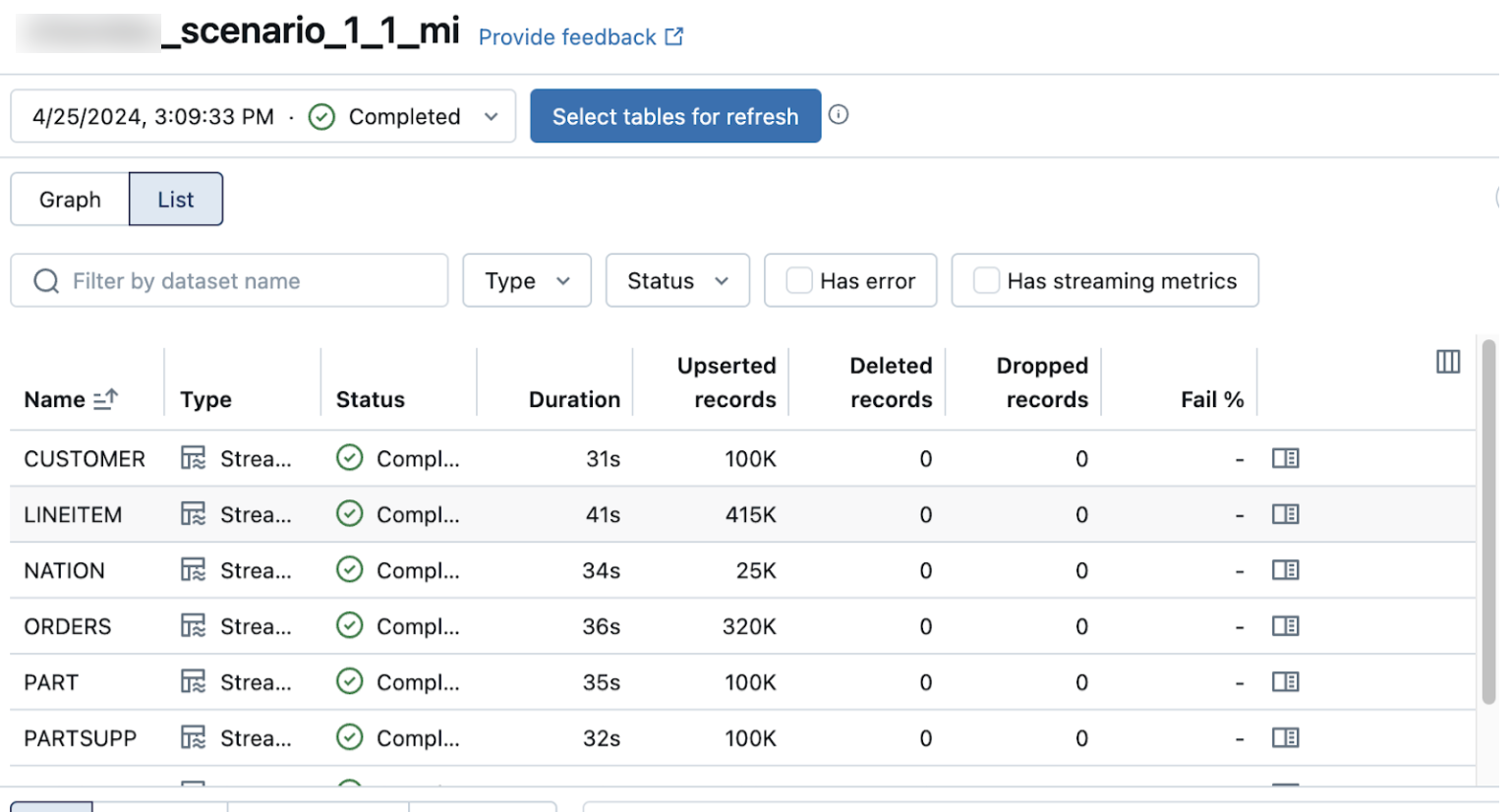
As colunas Upserted records e Deleted records não são exibidas por default. Você pode ativá-las clicando no ![]() botão de configuração das colunas e selecionando-as.
botão de configuração das colunas e selecionando-as.