Solucionar problemas de ingestão do SQL Server
Esta página descreve problemas comuns com o conector Microsoft SQL Server em Databricks LakeFlow Connect e como resolvê-los.
Solução de problemas gerais de pipeline
As etapas de solução de problemas nesta seção se aplicam a todos os pipelines de ingestão em LakeFlow Connect.
Se um pipeline falhar durante a execução, clique na etapa que falhou e confirme se a mensagem de erro fornece informações suficientes sobre a natureza do erro.
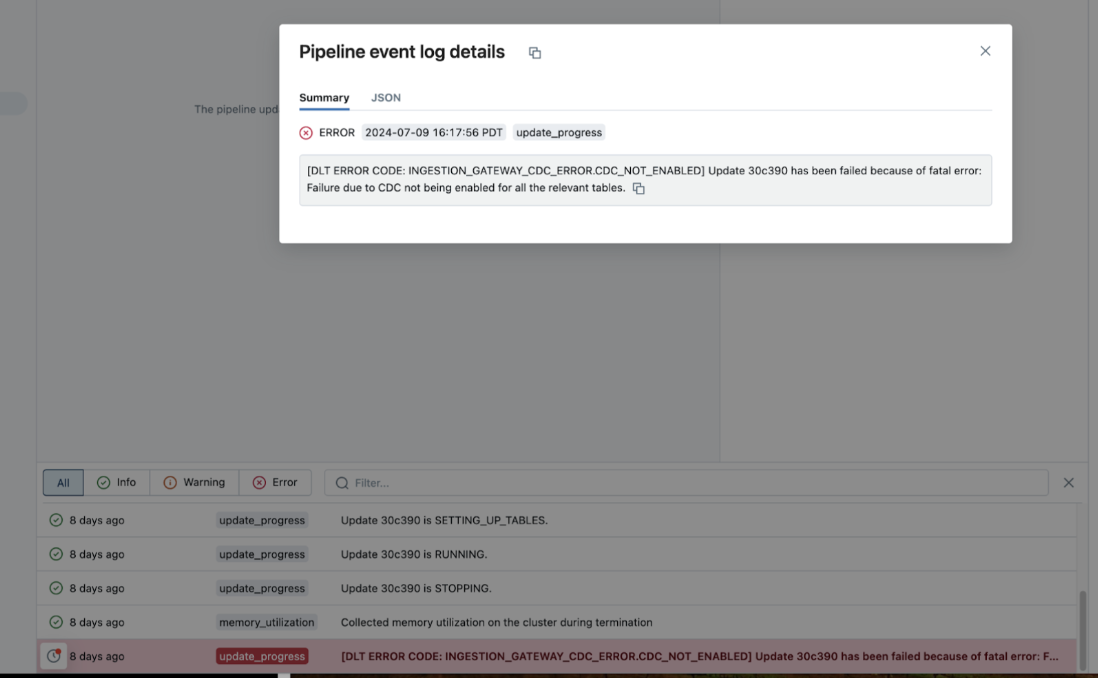
O senhor também pode verificar e download o clustering logs na página de detalhes pipeline clicando em Update details (Atualizar detalhes) no painel direito e, em seguida, em logs. Examine o site logs em busca de erros ou exceções.
Verificar se o CDC está ativado para um banco de dados ou uma tabela
Para verificar se o CDC está ativado para o banco de dados <database-name>:
select is_cdc_enabled from sys.databases where name='<database-name>';
Para verificar se o CDC está ativado para a tabela <schema-name>.<table-name>:
select t.is_tracked_by_cdc
from sys.tables t join sys.schemas s on t.schema_id = s.schema_id
where s.name='<schema-name>' and t.name='<table-name>';
Verificar se o acompanhamento de alterações está ativado para um banco de dados ou uma tabela
Para verificar se o acompanhamento de alterações está habilitado para o banco de dados\<database-name\>:
select ctdb.*
from sys.change_tracking_databases ctdb join sys.databases db
on db.database_id = ctdb.database_id
where db.name = '<MyDatabaseName>'
Para verificar se o acompanhamento de alterações está habilitado para a tabela <schema-name>.<table-name>:
select s.name schema_name, t.name table_name, ct.*
from sys.change_tracking_tables ct join sys.tables t
on ct.object_id = t.object_id
join sys.schemas s on t.schema_id = s.schema_id
where s.name = '<MySchemaName>' and t.name = '<MyTableName>'
Tempo limite de espera por tokens de mesa
A ingestão pipeline pode ter um tempo limite enquanto aguarda o fornecimento de informações pelo gateway. Isso pode ser porque:
- Você está executando uma versão mais antiga do gateway.
- Ocorreu um erro ao gerar as informações necessárias. Verifique se há erros no driver do gateway logs.
O fluxo refresh completa reduz significativamente a ocorrência de erros de tempo limite durante as operações refresh completa. Consulte Comportamento refresh completo (CDC).
default auth: não é possível configurar as credenciais do default
Se você receber esse erro, há um problema com a descoberta das credenciais atuais do usuário. Tente substituir o seguinte:
w = WorkspaceClient()
com:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
Consulte Autenticação na documentação do Databricks SDK para Python.
tech.replicant.common.ExtractorException: com.microsoft.sqlserver.JDBC.SQLServerException: Nome de coluna inválido 'SERIAL_NUMBER'.
Você pode receber esse erro se estiver usando uma versão mais antiga de uma tabela interna. Execute o seguinte no banco de dados conectado:
drop table dbo.replicate_io_audit_ddl_trigger_1;
PERMISSION_DENIED: o senhor não está autorizado a criar clustering. Entre em contato com seu administrador.
Entre em contato com um administrador do Databricks account para que ele lhe conceda as permissões do Unrestricted cluster creation.
CÓDIGO DE ERRO DO DLT: INGESTION_GATEWAY_INTERNAL_ERROR
Verifique o(s) arquivo(s) stdout no driver logs.
Conflito de nomeação da tabela de origem
Ingestion pipeline error: “org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `XYZ_snapshot_load` for `XYZ`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
Isso indica que há um conflito de nomes devido a várias tabelas de origem denominadas XYZ em diferentes esquemas de origem que estão sendo ingeridas pelo mesmo pipeline de ingestão para o mesmo esquema de destino.
Crie vários pares gateway-pipeline gravando essas tabelas conflitantes em diferentes esquemas de destino.
Alterações de esquema incompatíveis
Uma alteração de esquema incompatível faz com que o pipeline de ingestão falhe com um erro INCOMPATIBLE_SCHEMA_CHANGE. Para continuar a replicação, acione um refresh completo das tabelas afetadas.
A Databricks não pode garantir que, no momento em que o pipeline de ingestão falhar devido a uma alteração de esquema incompatível, todas as linhas anteriores à alteração de esquema tenham sido ingeridas.