Criar uma execução de treinamento usando a API de Otimização do Modelo Básico (obsoleto)
Otimização do modelo básico está obsoleta e está programada para remoção em 14 de agosto de 2026. As execuções de ajuste fino existentes continuam a funcionar e podem ser retreinadas, mas novas instalações do pacote databricks_genai e da IU de Ajuste Fino de Modelo Base serão bloqueadas após essa data.
A Databricks recomenda migrar para AI Runtime, que fornece um ambiente serverless com suporte a GPU para treinamento e ajuste fino de modelos básicos.
Visualização
Esse recurso está em Public Preview em us-east-1 e us-west-2.
Este artigo descreve como criar e configurar uma execução de treinamento usando a API do Foundation Model Fine-tuning (agora parte do Databricks Model Training) e descreve todos os parâmetros usados na chamada da API. Você também pode criar uma execução usando a interface do usuário. Para obter instruções, consulte Criar uma execução de treinamento usando a interface de usuário de ajuste fino de Modelo de Fundação (descontinuado).
Requisitos
Consulte os requisitos.
Criar um treinamento execução
Para criar o treinamento execução de forma programática, use a função create(). Essa função treina um modelo no site dataset fornecido e salva o modelo treinado para inferência.
As entradas necessárias são o modelo que o senhor deseja treinar, o local do seu treinamento dataset e onde registrar o modelo. Há também parâmetros opcionais que permitem que o senhor faça avaliações e altere os hiperparâmetros da sua execução.
Após a conclusão da execução, a execução concluída e o ponto de verificação final são salvos, o modelo é clonado e esse clone é registrado no Unity Catalog como uma versão do modelo para inferência.
O modelo da execução concluída, e não a versão clonada do modelo no Unity Catalog, é salvo no MLflow. Os pontos de controle podem ser usados para o ajuste fino contínuo da tarefa.
Consulte Configurar uma execução de treinamento para obter detalhes sobre os argumentos da função create().
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Configurar uma execução de treinamento
A tabela a seguir resume os parâmetros da função foundation_model.create().
Parâmetro | Obrigatório | Tipo | Descrição |
|---|---|---|---|
| x | str | O nome do modelo a ser usado. Consulte Modelos compatíveis. |
| x | str | O local dos seus dados de treinamento. Pode ser um local no Unity Catalog ( |
| x | str | O catálogo e o esquema do Unity Catalog ( |
| str | O ID de clustering do clustering a ser usado para o processamento de dados do site Spark. Isso é necessário para a instrução de treinamento tarefa em que os dados de treinamento estão em uma tabela Delta. Para obter informações sobre como encontrar a ID de clustering, consulte Obter ID de clustering. | |
| str | O caminho para o experimento do MLflow onde a saída da execução de treinamento (métricas e pontos de verificação) é salva. padrão para o nome da execução no site pessoal do usuário workspace (ou seja, o | |
| str | O tipo de tarefa a ser executada. Pode ser | |
| str | A localização remota dos seus dados de avaliação (se houver). Deve seguir o mesmo formato de | |
| Lista [str] | Uma lista de strings de instrução para gerar respostas durante a avaliação. O padrão é | |
| str | A localização remota de um ponto de verificação de modelo personalizado para treinamento. O padrão é | |
| str | A duração total da sua execução. O default é uma época ou | |
| str | A taxa de aprendizado para o treinamento do modelo. Todos os modelos são treinados usando o otimizador AdamW, com aquecimento da taxa de aprendizado. A taxa de aprendizado do default pode variar de acordo com o modelo. Sugerimos que o senhor execute uma varredura de hiperparâmetros, experimentando diferentes taxas de aprendizado e duração do treinamento para obter modelos da mais alta qualidade. | |
| str | O comprimento máximo da sequência da amostra de dados. É usado para truncar quaisquer dados muito longos e para empacotar sequências mais curtas para eficiência. O endereço default é 8192 tokens ou o comprimento máximo do contexto para o modelo fornecido, o que for menor. Você pode usar esse parâmetro para configurar o tamanho do contexto, mas a configuração além do tamanho máximo do contexto de cada modelo não é suportada. Consulte Modelos compatíveis para saber o tamanho máximo de contexto suportado de cada modelo. | |
| Booleana | Se deve validar o acesso aos caminhos de entrada antes de enviar o Job de treinamento. O default é |
Use pesos de modelo personalizados
NOTA: Se você treinou um modelo antes de 26/03/2025, não poderá mais treinar continuamente a partir desses pontos de verificação do modelo. Qualquer treinamento executado anteriormente ainda pode ser servido com o provisionamento Taxa de transferência sem problemas.
O ajuste fino do Foundation Model suporta a adição de pesos personalizados usando o parâmetro opcional custom_weights_path para treinar e personalizar um modelo.
Para começar, defina custom_weights_path como o caminho do ponto de verificação de uma execução anterior de treinamento da API de ajuste fino. Os caminhos dos pontos de controle podem ser encontrados em Artifacts tab de uma execução anterior do MLflow. O nome da pasta do ponto de verificação corresponde aos lotes e à época de um determinado Snapshot, como ep29-ba30/.

- Para fornecer o ponto de verificação mais recente de uma execução anterior, defina
custom_weights_pathcomo o ponto de verificação produzido pela API de ajuste fino. Por exemplo,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Para fornecer um ponto de verificação anterior, defina
custom_weights_pathcomo um caminho para uma pasta contendo.distcparquivos correspondentes ao ponto de verificação desejado, comocustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Em seguida, atualize o parâmetro model para corresponder ao modelo básico do ponto de verificação que você passou para custom_weights_path.
No exemplo a seguir, ift-meta-llama-3-1-70b-instruct-ohugkq é uma execução anterior que faz o ajuste fino de meta-llama/Meta-Llama-3.1-70B. Para ajustar o ponto de verificação mais recente de ift-meta-llama-3-1-70b-instruct-ohugkq, defina as variáveis model e custom_weights_path da seguinte forma:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Consulte Configurar uma execução de treinamento para configurar outros parâmetros em sua execução de ajuste fino.
Obter ID de clustering
Para recuperar o ID do cluster:
-
Na barra de navegação esquerda do workspace do Databricks, clique em Computação .
-
Na tabela, clique no nome do cluster.
-
Clique em
 no canto superior direito e selecione Ver JSON no menu suspenso.
no canto superior direito e selecione Ver JSON no menu suspenso. -
O arquivo JSON do cluster é exibido. Copie a ID do cluster, que é a primeira linha no arquivo.
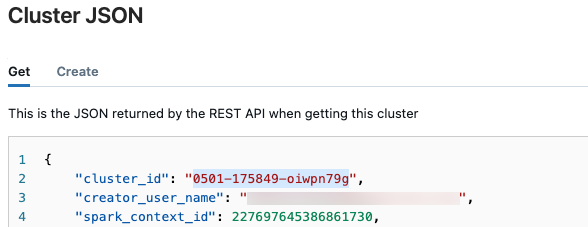
Obter o status de uma execução
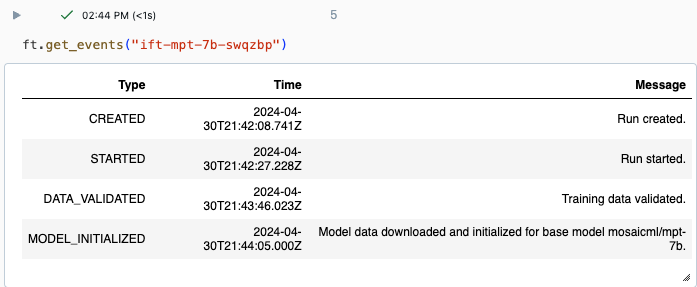
Você pode acompanhar o progresso de uma execução usando a página Experimento na interface do usuário do Databricks ou usando o comando get_events() da API. Para obter detalhes, consulte Visualização, gerenciamento e análise de execuções de otimização de modelo básico (obsoleto).
Exemplo de saída de get_events():
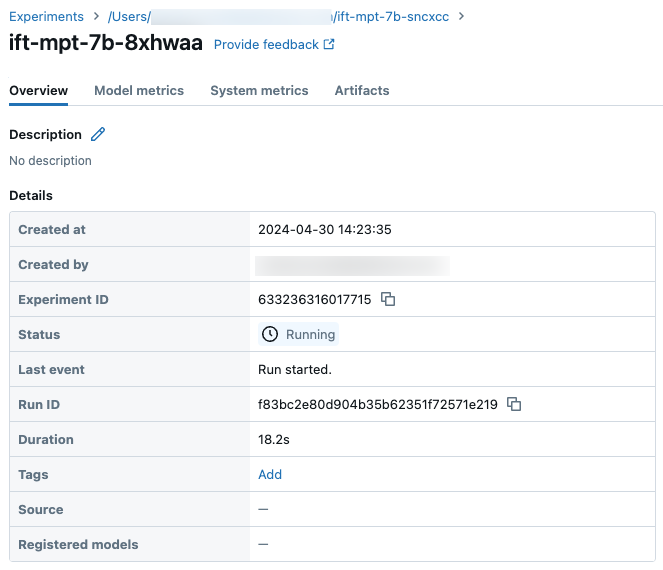
Detalhes da execução de exemplo na página Experimento:
Próximas etapas
Após a conclusão da execução do treinamento, é possível revisar as métricas no MLflow e implantar o modelo para inferência. Veja os passos 5 a 7 de Tutorial: criação e implantação de uma execução de otimização de modelo básico (obsoleto).
Consulte o notebook de demonstração Ajuste fino de instruções: reconhecimento de entidade nomeada para ver um exemplo de ajuste fino de instruções que descreve a preparação de dados, a configuração e a implantação da execução de treinamento de ajuste fino.
Notebook exemplo
O Notebook a seguir mostra um exemplo de como gerar o uso sintético de dados do modelo Meta Llama 3.1 405B Instruct e usar esses dados para ajustar um modelo:
Gerar uso sintético de dados Llama 3.1 405B Instruct Notebook
Recurso adicional
- Ajuste fino do modelo de base (obsoleto)
- Tutorial: criação e implantação de uma execução de otimização do modelo básico (descontinuado)
- Criação de uma execução de treinamento usando a IU de Otimização do modelo básico (obsoleto)
- Visualizar, gerenciar e analisar execuções de Otimização do modelo básico (obsoleto)
- Prepare dados para ajuste fino do modelo básico (obsoleto)