Junção de recurso point-in-time
Este artigo descreve como usar a correção point-in-time para criar um treinamento dataset que reflita com precisão os valores do recurso no momento em que uma observação de rótulo foi registrada. Isso é importante para evitar o vazamento de dados , que ocorre quando o senhor usa valores de recurso para treinamento de modelos que não estavam disponíveis no momento em que o rótulo foi registrado. Esse tipo de erro pode ser difícil de detectar e pode afetar negativamente o desempenho do modelo.
As tabelas de recurso de série temporal incluem uma coluna de carimbo de data/hora key que garante que cada linha do treinamento dataset represente os últimos valores de recurso conhecidos a partir do carimbo de data/hora da linha. O senhor deve usar tabelas de recurso de série temporal sempre que os valores de recurso mudarem ao longo do tempo, por exemplo, com dados de série temporal, dados baseados em eventos ou dados agregados no tempo.
O diagrama a seguir mostra como o carimbo de data/hora key é usado. O valor do recurso registrado para cada registro de data e hora é o valor mais recente antes desse registro de data e hora, indicado pelo círculo laranja contornado. Se nenhum valor tiver sido registrado, o valor do recurso será nulo. Para obter mais detalhes, consulte Como funcionam as tabelas de recurso de séries temporais.
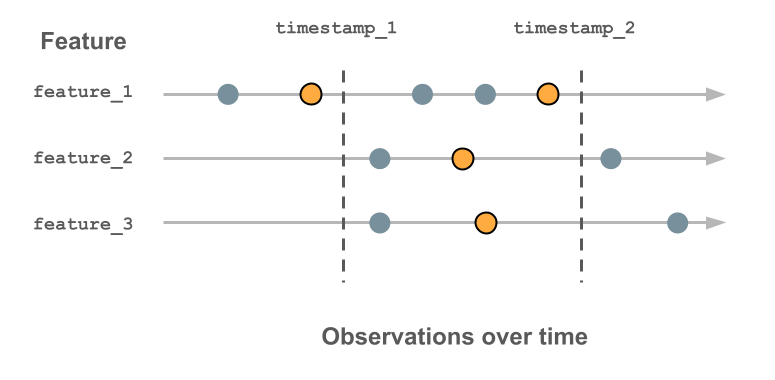
- Com Databricks Runtime 13.3 LTS e acima, qualquer tabela Delta em Unity Catalog com chave primária e chave de registro de data e hora pode ser usada como uma tabela de recurso de série temporal.
- Para obter melhor desempenho em pesquisas pontuais, o site Databricks recomenda que o senhor aplique o Liquid clustering (para
databricks-feature-engineering0.6.0 e acima) ou Z-ordering (paradatabricks-feature-engineering0.6.0 e abaixo) em tabelas de séries temporais. - A funcionalidade de pesquisa point-in-time às vezes é chamada de "viagem do tempo". A funcionalidade point-in-time do Databricks recurso Store não está relacionada ao Delta Lake viagem do tempo.
Como funcionam as tabelas de recurso de séries temporais
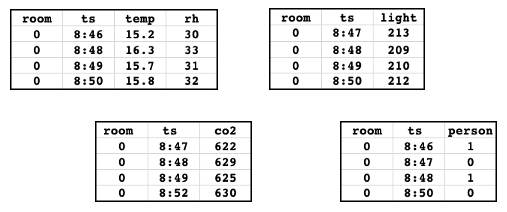
Suponha que o senhor tenha as seguintes tabelas de recursos. Esses dados foram extraídos do Notebook de exemplo.
As tabelas contêm dados de sensores que medem a temperatura, umidade relativa, luz ambiente e dióxido de carbono em uma sala. A tabela de fatos básicos indica se uma pessoa estava presente na sala. Cada uma das tabelas tem um key primário ("room") e um registro de data e hora key ("ts"). Para simplificar, são mostrados apenas os dados de um único valor do key primário ('0').
A figura a seguir ilustra como o carimbo de data/hora key é usado para garantir a correção pontual em um treinamento dataset. Os valores de recurso são combinados com base no key primário (não mostrado no diagrama) e no registro de data e hora key, usando um AS OF join. O AS OF join garante que o valor mais recente do recurso no momento do registro de data e hora seja usado no conjunto de treinamento.
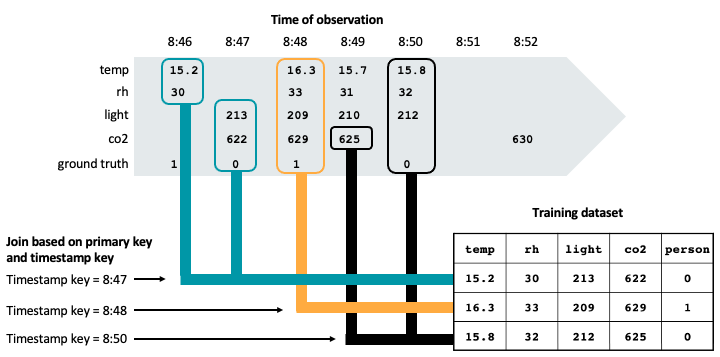
Conforme mostrado na figura, o treinamento dataset inclui os valores de recurso mais recentes para cada sensor antes do registro de data e hora na verdade terrestre observada.
Se o senhor criar um treinamento dataset sem levar em conta account o carimbo de data/hora key, poderá ter uma linha com esses valores de recurso e a verdade básica observada:
| temp | rh | luz | co2 | ground truth | | ---- | -- | ----- | --- | ------------ | | 15.8 | 32 | 212 | 630 | 0 |
No entanto, essa não é uma observação válida para o treinamento, pois a leitura de co2 de 630 foi feita às 8:52, após a observação da verdade terrestre às 8:50. Os dados futuros estão "vazando" para o conjunto de treinamento, o que prejudicará o desempenho do modelo.
Requisitos
- Para recurso engenharia em Unity Catalog: recurso engenharia em Unity Catalog cliente (qualquer versão).
- Para o espaço de trabalho recurso Store (legado): cliente recurso Store v0.3.7 e acima.
Como especificar a chave relacionada ao tempo
Para usar a funcionalidade point-in-time, o senhor deve especificar a chave relacionada ao tempo usando o argumento timeseries_columns (para recurso engenharia em Unity Catalog) ou o argumento timestamp_keys (para recurso workspace Store). Isso indica que as linhas da tabela de recurso devem ser unidas por meio da correspondência do valor mais recente de um key primário específico que não seja posterior ao valor da coluna timestamps_keys, em vez de serem unidas com base em uma correspondência de tempo exata.
Se o senhor não usar timeseries_columns ou timestamp_keys e apenas designar uma coluna de série temporal como uma coluna primária key, o repositório de recursos não aplicará a lógica point-in-time à coluna de série temporal durante a união. Em vez disso, ele corresponde apenas às linhas com uma correspondência de hora exata, em vez de corresponder a todas as linhas antes do carimbo de data/hora.
Criar uma tabela de recurso de série temporal em Unity Catalog
Em Unity Catalog, qualquer tabela com um TIMESERIES primária key é uma tabela de recurso de série temporal. Para criar uma tabela de recurso de série temporal, consulte Criar uma tabela de recurso em Unity Catalog. Os exemplos a seguir ilustram os diferentes tipos de tabelas de séries temporais.
Publique tabelas de séries temporais em lojas on-line
Ao trabalhar com tabelas de recurso que contêm dados de carimbo de data/hora, o senhor precisa considerar se deve designar a coluna de carimbo de data/hora como timeseries_column ou tratá-la como uma coluna normal, dependendo dos requisitos de veiculação on-line.
Colunas de carimbo de data/hora marcadas com designação de série temporal
Use o site timeseries_column quando precisar de correção pontual para o conjunto de dados de treinamento e quiser procurar os valores de recurso mais recentes a partir de um carimbo de data/hora específico em aplicativos on-line. Uma tabela de recurso de série temporal deve ter um registro de data e hora key e não pode ter nenhuma coluna de partição. A coluna de carimbo de data/hora key deve ser de TimestampType ou DateType.
Databricks recomenda que as tabelas de recurso de série temporal não tenham mais de duas colunas primárias key para garantir gravações e pesquisas de alto desempenho.
- FeatureEngineeringClient API
- SQL API
fe = FeatureEngineeringClient()
# Create a time series table for point-in-time joins
fe.create_table(
name="catalog.schema.user_behavior_features",
primary_keys=["user_id", "event_timestamp"],
timeseries_columns="event_timestamp", # Enables point-in-time logic
df=features_df # DataFrame must contain primary keys and time series columns
)
-- Create table with time series constraint for point-in-time joins
CREATE TABLE catalog.schema.user_behavior_features (
user_id STRING NOT NULL,
event_timestamp TIMESTAMP NOT NULL, -- part of primary key and designated as TIMESERIES
purchase_amount DOUBLE,
page_views_last_hour INT,
CONSTRAINT pk_user_behavior PRIMARY KEY (user_id, event_timestamp TIMESERIES)
) USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true'
);
Colunas de carimbo de data/hora sem designação de série temporal
Para publicar todos os valores de séries temporais no armazenamento on-line (não apenas os valores mais recentes), inclua as colunas de carimbo de data/hora como parte do site primário key, mas não as designe como timeseries_column.
- FeatureEngineeringClient API
- SQL API
fe = FeatureEngineeringClient()
# Create a regular table with timestamp column (no point-in-time logic)
fe.create_table(
name="catalog.schema.user_current_features",
primary_keys=["user_id", "event_timestamp"],
# Note: event_timestamp is not marked as a time series column
df=features_df # DataFrame must contain primary keys columns
)
-- Create table with timestamp column but no time series constraint
CREATE TABLE catalog.schema.user_current_features (
user_id STRING NOT NULL,
event_timestamp TIMESTAMP NOT NULL, -- part of primary key, but NOT designated as TIMESERIES
current_balance DOUBLE,
subscription_status STRING,
last_login_days_ago INT,
CONSTRAINT pk_user_current PRIMARY KEY (user_id, event_timestamp)
) USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true'
);
Atualizar uma tabela de recurso de série temporal
Ao escrever recurso nas tabelas de recurso de série temporal, o site DataFrame deve fornecer valores para todos os recursos da tabela de recurso, diferentemente das tabelas de recurso regulares. Essa restrição reduz a esparsidade dos valores de recurso entre os registros de data e hora na tabela de recurso da série temporal.
- Feature Engineering in Unity Catalog
- Workspace Feature Store client v0.13.4 and above
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
Há suporte para gravações de transmissão em tabelas de recursos de séries temporais.
Criar um conjunto de treinamento com uma tabela de recursos de série temporal
Para realizar uma pesquisa pontual de valores de recurso em uma tabela de recurso de série temporal, o senhor deve especificar um timestamp_lookup_key no FeatureLookup do recurso, que indica o nome da coluna DataFrame que contém carimbos de data/hora para a pesquisa de recurso de série temporal. Databricks recurso Store recupera os valores de recurso mais recentes anteriores aos carimbos de data/hora especificados na coluna DataFrame's timestamp_lookup_key e cuja chave primária (excluindo a chave de carimbo de data/hora) corresponde aos valores nas colunas DataFrame's lookup_key, ou null se não houver nenhum valor de recurso.
- Feature Engineering in Unity Catalog
- Workspace Feature Store
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Para obter um desempenho de pesquisa mais rápido quando o Photon estiver ativado, passe use_spark_native_join=True para FeatureEngineeringClient.create_training_set. Isso requer o site databricks-feature-engineering versão 0.6.0 ou acima.
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Qualquer FeatureLookup em uma tabela de recurso de série temporal deve ser uma pesquisa point-in-time, portanto, deve especificar uma coluna timestamp_lookup_key para ser usada em DataFrame. A pesquisa point-in-time não ignora linhas com valores de recurso null armazenados na tabela de recursos de série temporal.
Definir um limite de tempo para os valores históricos do recurso
Com o recurso Store client v0.13.0 ou superior, ou qualquer versão do recurso engenharia no Unity Catalog client, o senhor pode excluir do conjunto de treinamento os valores de recurso com registros de data e hora mais antigos. Para fazer isso, use o parâmetro lookback_window no FeatureLookup.
O tipo de dados de lookback_window deve ser datetime.timedelta e o valor de default é None (todos os valores de recurso são usados, independentemente da idade).
Por exemplo, o código a seguir exclui qualquer valor de recurso que tenha mais de 7 dias:
- Feature Engineering in Unity Catalog
- Workspace Feature Store
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
Quando o senhor chama create_training_set com o acima FeatureLookup, ele executa automaticamente o point-in-time join e exclui os valores de recurso com mais de 7 dias.
A janela de lookback é aplicada durante o treinamento e a inferência de lotes. Durante a inferência on-line, o valor mais recente do recurso é sempre usado, independentemente da janela de lookback.
Modelos de pontuação com tabelas de recursos de séries temporais
Quando o senhor pontua um modelo treinado com recurso de tabelas de recurso de séries temporais, o Databricks recurso Store recupera o recurso apropriado usando pesquisas pontuais com pacote de metadados com o modelo durante o treinamento. O DataFrame que o senhor fornece para FeatureEngineeringClient.score_batch (para recurso engenharia em Unity Catalog) ou FeatureStoreClient.score_batch (para recurso workspace Store) deve conter uma coluna de carimbo de data/hora com o mesmo nome e DataType que o timestamp_lookup_key do FeatureLookup fornecido para FeatureEngineeringClient.create_training_set ou FeatureStoreClient.create_training_set.
Para obter um desempenho de pesquisa mais rápido quando o Photon estiver ativado, passe use_spark_native_join=True para FeatureEngineeringClient.score_batch. Isso requer o site databricks-feature-engineering versão 0.6.0 ou acima.
Publicar recurso de série temporal em um armazenamento on-line
O senhor pode usar FeatureEngineeringClient.publish_table (para recurso engenharia in Unity Catalog) ou FeatureStoreClient.publish_table (para recurso workspace Store) para publicar tabelas de recurso de séries temporais em lojas on-line. Databricks O recurso Store oferece a funcionalidade de publicar um Snapshot ou uma janela de dados de séries temporais no armazenamento on-line, dependendo do provedor de armazenamento on-line. A tabela a seguir mostra os modos suportados por cada provedor.
armazenamento online provider | Snapshot modo | Modo de janela |
|---|---|---|
Amazon DynamoDB (v0.3.8e acima) | X | X |
Amazon Aurora (compatível com MySQL) | X | |
Amazon RDS MySQL | X |
Publicar uma série temporal Snapshot
No modo Snapshot, publish_table publica os valores de recurso mais recentes para cada key primário na tabela de recursos. O armazenamento on-line suporta a pesquisa primária key, mas não suporta a pesquisa point-in-time.
Para lojas on-line que não suportam o time to live, o Databricks recurso Store suporta apenas o modo de publicação Snapshot. Para lojas on-line que suportam o tempo de vida, o modo de publicação default é Snapshot, a menos que o tempo de vida (ttl) seja especificado no OnlineStoreSpec no momento da criação.
Publicar uma janela de séries temporais
No modo janela, o site publish_table publica todos os valores de recurso para cada key primário na tabela de recurso para o armazenamento on-line e remove automaticamente os registros expirados. Um registro é considerado expirado se o carimbo de data e hora do registro (em UTC) for maior que o tempo especificado para a duração da vida no passado. Consulte a documentação específica da nuvem para obter detalhes sobre o tempo de vida útil.
O armazenamento on-line suporta a pesquisa primária em key e recupera automaticamente o valor do recurso com o último registro de data e hora.
No modo janela, o senhor deve fornecer um valor para o tempo de vida (ttl) no OnlineStoreSpec quando criar o armazenamento on-line. O ttl não pode ser alterado depois de definido. Todas as chamadas de publicação subsequentes herdam o ttl e não precisam defini-lo explicitamente no OnlineStoreSpec.
Notebook exemplo: Tabela de recurso de série temporal
Estes exemplos do Notebook ilustram pesquisas pontuais em tabelas de recurso de séries temporais.
Use este Notebook em um espaço de trabalho habilitado para Unity Catalog.
Exemplo de tabela de recurso de série temporal Notebook (Unity Catalog)
O Notebook a seguir foi projetado para espaços de trabalho que não estão habilitados para Unity Catalog. Ele usa o espaço de trabalho recurso Store.