tutorial: implantar e consultar um modelo personalizado
Este artigo fornece as etapas básicas para implantar e consultar um modelo personalizado, que é um modelo ML tradicional, usando Mosaic AI Model Serving. O modelo deve ser registrado em Unity Catalog ou no workspace registro de modelo.
Para saber mais sobre como servir e implantar modelos generativos AI, consulte os artigos a seguir:
Etapa 1: registrar o modelo
Há diferentes maneiras de log seu modelo de servindo modelo:
Técnica de registro | Descrição |
|---|---|
Registro automático | Isso é ativado automaticamente quando o senhor usa o Databricks Runtime para aprendizado de máquina. É a maneira mais fácil, mas oferece menos controle. |
Registro de logs usando os sabores integrados do MLflow | O senhor pode log manualmente o modelo com os sabores de modelo integrado doMLflow. |
Registro personalizado com | Use isso se você tiver um modelo personalizado ou se precisar de etapas extras antes ou depois da inferência. |
O exemplo a seguir mostra como log o modelo MLflow usando a variante transformer e especificando os parâmetros necessários para o modelo.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Depois que o modelo for registrado, certifique-se de verificar se ele está registrado em Unity Catalog ou no site MLflow Model Registry.
Etapa 2: Criar endpoint usando a UI de serviço
Depois que o modelo registrado for registrado e o senhor estiver pronto para servi-lo, poderá criar um modelo de serviço endpoint usando a Serving UI.
-
Clique em Serving na barra lateral para exibir a Serving UI.
-
Clique em Criar endpoint de serviço .
-
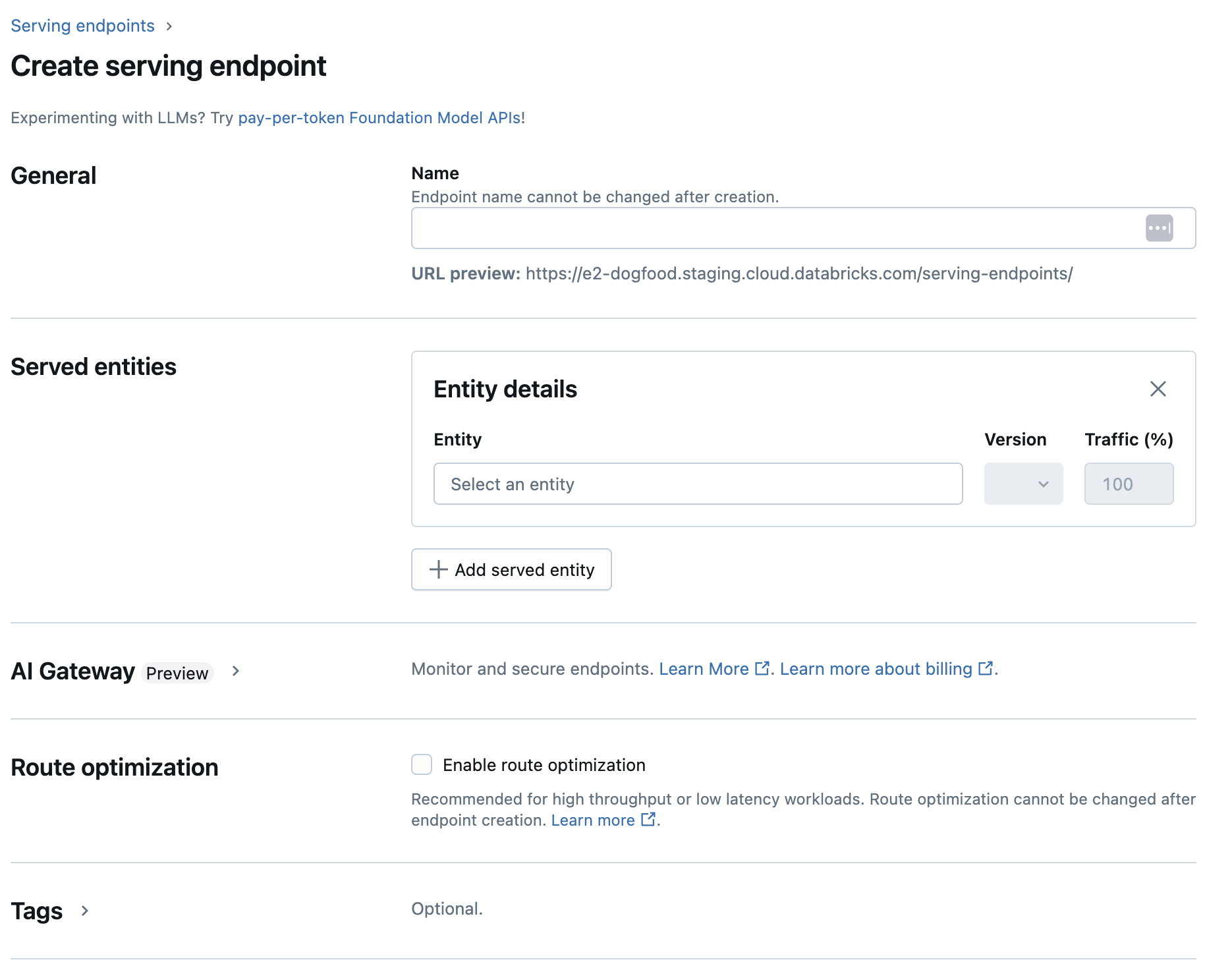
No campo Nome , informe um nome para o seu endpoint.
-
Na seção Entidades atendidas
-
Clique no campo Entidade para abrir o formulário Selecionar entidade servida .
-
Selecione o tipo de modelo que você deseja servir. O formulário é atualizado dinamicamente com base na sua seleção.
-
Selecione qual modelo e versão do modelo você deseja servir.
-
Selecione a porcentagem de tráfego a ser direcionada para seu modelo atendido.
-
Selecione o tamanho do site compute a ser usado.
-
Em compute escala-out , selecione o tamanho do compute escala out que corresponde ao número de solicitações que esse modelo atendido pode processar ao mesmo tempo. Esse número deve ser aproximadamente igual ao tempo de execução do modelo QPS x.
- Os tamanhos disponíveis são pequeno para 0 a 4 solicitações, médio para 8 a 16 solicitações e grande para 16 a 64 solicitações.
-
Especifique se o site endpoint deve ser escalonado para zero quando não estiver em uso.
-
-
Clique em Criar . A página Serving endpoint é exibida com o estado Serving endpoint mostrado como Not Ready.
endpoint Se o Databricks senhor preferir criar um de forma programática com o Servindo,API consulte Criar endpoint de modelo de serviço personalizado.
Etapa 3: Consultar o endpoint
A maneira mais fácil e rápida de testar e enviar solicitações de pontuação para seu modelo atendido é usar a Serving UI.
-
Na página Serving endpoint (Ponto de extremidade de serviço), selecione Query endpoint (Ponto de extremidade de consulta).
-
Insira os dados de entrada do modelo no formato JSON e clique em Send Request (Enviar solicitação ). Se o modelo tiver sido registrado com um exemplo de entrada, clique em Show Example (Mostrar exemplo ) para carregar o exemplo de entrada.
Python{
"inputs" : ["Hello, I'm a language model,"],
"params" : {"max_new_tokens": 10, "temperature": 1}
}
Para enviar solicitações de pontuação, construa um JSON com uma das chaves compatíveis e um objeto JSON correspondente ao formato de entrada. Consulte Ponto de extremidade de serviço de consulta para modelos personalizados para obter os formatos compatíveis e orientações sobre como enviar solicitações de pontuação usando o site API.
Se o senhor planeja acessar o endpoint de serviço fora da interface do usuário do Databricks Serving, precisará de um DATABRICKS_API_TOKEN.
Como prática recomendada de segurança para cenários de produção, a Databricks recomenda que o senhor use tokens OAuth máquina a máquina para autenticação durante a produção.
Para testes e desenvolvimento, o site Databricks recomenda o uso de tokens de acesso pessoal pertencentes à entidade de serviço em vez de usuários do site workspace. Para criar tokens o site para uma entidade de serviço, consulte gerenciar tokens para uma entidade de serviço.
Exemplo de notebook
Veja o seguinte Notebook para servir um modelo MLflow transformers com servindo modelo.
implantado a Hugging Face transformers model Notebook
Veja o Notebook a seguir para servir um modelo MLflow pyfunc com servindo modelo. Para obter mais detalhes sobre a personalização de suas implantações de modelo, consulte implantado Python code with servindo modelo.