Forecasting (serverless) com AutoML
Visualização
Esse recurso está em Public Preview.
Este artigo mostra como executar um experimento de previsão serverless usando a UI de treinamento do modelo Mosaic AI.
Mosaic AI O Model Treinamento - forecasting simplifica a previsão de dados de séries temporais, selecionando automaticamente o melhor algoritmo e os melhores hiperparâmetros, tudo isso enquanto é executado em um recurso totalmente gerenciado compute.
Para entender a diferença entre a previsão serverless e a previsão clássica compute, consulte previsão sem servidor vs. previsão clássica compute.
Requisitos
-
Dados de treinamento com uma coluna de série temporal, salvos como uma tabela do Unity Catalog.
-
Se o workspace tiver o Secure Egress Gateway (SEG) ativado, o
pypi.orgdeverá ser adicionado à lista de domínios permitidos . Consulte gerenciar políticas de rede para serverless controle de saída.
Crie um experimento de previsão com a interface do usuário
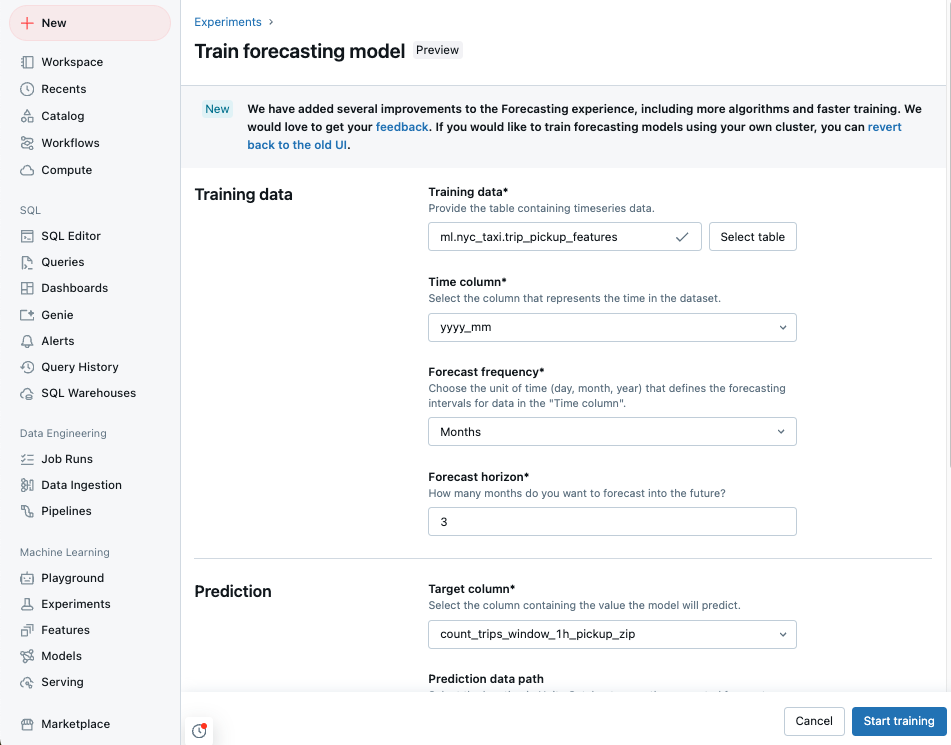
Acesse o site Databricks páginas de aterrissagem e clique em Experiments (Experimentos ) na barra lateral.
-
Na caixa Forecasting (Previsão ), selecione começar treinamento .
-
Selecione os dados de treinamento em uma lista de tabelas do Unity Catalog que o senhor pode acessar.
- Coluna de tempo : selecione a coluna que contém os períodos da série temporal. As colunas devem ser do tipo
timestampoudate. - Frequência de previsão : selecione a unidade de tempo que representa a frequência dos dados de entrada. Por exemplo, minutos, horas, dias, meses. Isso determina a granularidade da sua série temporal.
- Horizonte de previsão : especifique quantas unidades da frequência selecionada devem ser previstas no futuro. Junto com a frequência da previsão, isso define as unidades de tempo e o número de unidades de tempo a serem previstas.
- Coluna de tempo : selecione a coluna que contém os períodos da série temporal. As colunas devem ser do tipo
Para usar o algoritmo Auto-ARIMA, a série temporal deve ter uma frequência regular, em que o intervalo entre dois pontos quaisquer deve ser o mesmo em toda a série temporal. O AutoML lida com as etapas de tempo ausentes preenchendo esses valores com o valor anterior.
-
Selecione a coluna Alvo de previsão que o senhor deseja que o modelo preveja.
-
Opcionalmente, especifique um caminho de dados Prediction da tabela do Unity Catalog para armazenar as previsões de saída.
-
Selecione um registro de modelo Unity Catalog local e nome.
-
Opcionalmente, defina as opções avançadas:
- Nome do experimento: Forneça um nome de experimento do MLflow.
- Colunas identificadoras de séries temporais - Para previsões de várias séries, selecione as colunas que identificam as séries temporais individuais. O Databricks agrupa os dados por essas colunas como séries temporais diferentes e treina um modelo para cada série de forma independente.
- Métricas primárias : Escolha as principais métricas usadas para avaliar e selecionar o melhor modelo.
- Estrutura de treinamento : Escolha as estruturas a serem exploradas pelo AutoML.
- Coluna dividida : selecione a coluna que contém a divisão de dados personalizada. Os valores devem ser “treinar”, “validar”, “testar”
- Coluna de peso : especifique a coluna a ser usada para ponderar séries temporais. Todas as amostras de uma determinada série temporal devem ter o mesmo peso. O peso deve estar na faixa [0, 10000].
- Região de feriados : Selecione a região do feriado a ser usada como covariável no treinamento do modelo.
- Tempo limite : Defina uma duração máxima para o experimento AutoML.
executar o experimento e monitorar os resultados
Para começar o experimento AutoML, clique em começar treinamento . Na página de treinamento de experimentos, o senhor pode fazer o seguinte:
- Pare o experimento a qualquer momento.
- Monitorar a execução.
- Navegue até a página de execução de qualquer execução.
Além disso, você pode verificar o status do experimento à medida que ele passa pelas seguintes etapas:
- Pré-processamento: Validar e preparar a tabela de entrada imputando valores ausentes e dividindo os dados em conjuntos de treinamento, validação e teste. O processamento automático de geração de recurso, como a codificação de um único disparo para recurso categórico, também ocorre durante esse estágio.
- Ajuste: explore diferentes algoritmos de previsão e ajuste hiperparâmetros.
- treinamento: Treinar e avaliar o modelo final com as melhores configurações selecionadas. registra o modelo em Unity Catalog se um caminho for especificado.
visualizar resultados ou usar o melhor modelo
Após a conclusão do treinamento, os resultados da previsão são armazenados na tabela Delta especificada e o melhor modelo é registrado no Unity Catalog.
Na página de experimentos, você escolhe entre as próximas etapas a seguir:
- Selecione visualizar previsões para ver a tabela de resultados da previsão.
- Selecione lotes inference Notebook para abrir um Notebook gerado automaticamente para a inferência de lotes usando o melhor modelo.
- Selecione Create serving endpoint para implantar o melhor modelo em um modelo servindo endpoint.
previsão sem servidor vs. previsão clássica compute
A tabela a seguir resume as diferenças entre a serverless previsão do computee a previsão com o clássico
Recurso | previsão sem servidor | Clássico compute forecasting |
|---|---|---|
infraestrutura de computação | Databricks gerenciar compute configuração e otimiza automaticamente o custo e o desempenho. | Configurado pelo usuário compute |
Governança | Modelos e artefatos registrados no Unity Catalog | Armazenamento de arquivos workspace configurado pelo usuário |
Seleção de algoritmo | Modelos estatísticos mais o algoritmo de rede neural de aprendizagem profunda DeepAR | |
integração da loja de recursos | Não suportado | |
Notebook gerado automaticamente | Lotes inference Notebook | Código-fonte para todos os testes |
Implantação de modelo de serviço com um clique | Suportado | Sem compatibilidade |
Divisões personalizadas de treinamento/validação/teste | Suportado | Não suportado |
Pesos personalizados para séries temporais individuais | Suportado | Não suportado |