log, carga e registro MLflow models
Um MLflow modelo é um formato padrão para empacotar modelos de aprendizado de máquina que podem ser usados em várias ferramentas downstream - por exemplo, inferência de lotes em Apache Spark ou tempo real servindo por meio de um REST API. O formato define uma convenção que permite que o senhor salve um modelo em diferentes sabores (Python-function, PyTorch, sklearn, e assim por diante), que podem ser compreendidos por diferentes plataformas de inferência e de fornecimento de modelos.
Para saber como log e pontuar um modelo de transmissão, consulte Como salvar e carregar um modelo de transmissão.
O MLflow 3 introduz aprimoramentos significativos nos modelos do MLflow com a introdução de um novo objeto dedicado LoggedModel com seus próprios metadados, como métricas e parâmetros. Para obter mais detalhes, consulte Rastrear e comparar modelos usando MLflow modelos logged.
modelos de registro e carga
Quando o senhor acessa log um modelo, MLflow automaticamente logs requirements.txt e conda.yaml arquivos. Você pode usar esses arquivos para recriar o ambiente de desenvolvimento do modelo e reinstalar dependências usando virtualenv (recomendado) ou conda.
A Anaconda Inc. atualizou seus termos de serviço para o canal anaconda.org. Com base nos novos termos de serviço, o senhor pode precisar de uma licença comercial se depender do empacotamento e da distribuição do Anaconda. Para obter mais informações, consulte as Perguntas frequentes sobre o Anaconda Commercial Edition. Seu uso de qualquer canal da Anaconda é regido pelos respectivos termos de serviço.
MLflow Os registros de modelos anteriores à v1.18 (Databricks Runtime 8.3 ML ou anterior) eram por registros default com o canal conda defaults (https://repo.anaconda.com/pkgs/) como uma dependência. Devido a essa alteração de licença, o site Databricks interrompeu o uso do canal defaults para registros de modelos que usam MLflow v1.18 e acima. Os registros do canal default agora são conda-forge, que apontam para a comunidade gerenciar https://conda-forge.org/.
Se o senhor fizer o logon de um modelo antes de MLflow v1.18 sem excluir o canal defaults do ambiente conda para o modelo, esse modelo poderá ter uma dependência do canal defaults que o senhor talvez não tenha pretendido.
Para confirmar manualmente se um modelo tem essa dependência, o senhor pode examinar o valor channel no arquivo conda.yaml que é empacotado com os modelos registrados. Por exemplo, o site conda.yaml de um modelo com uma dependência de canal defaults pode ter a seguinte aparência:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Como a Databricks não pode determinar se o uso do repositório do Anaconda para interagir com seus modelos é permitido em seu relacionamento com o Anaconda, a Databricks não está forçando seus clientes a fazer alterações. Se o seu uso do repositório Anaconda.com por meio do uso do Databricks for permitido de acordo com os termos do Anaconda, o senhor não precisará tomar nenhuma medida.
Se quiser alterar o canal usado no ambiente de um modelo, o senhor pode registrar novamente o modelo no registro de modelo com um novo conda.yaml. O senhor pode fazer isso especificando o canal no parâmetro conda_env de log_model().
Para obter mais informações sobre log_model() API, consulte a documentação MLflow da variante de modelo com a qual o senhor está trabalhando, por exemplo, os logs de scikit-learn.
Para obter mais informações sobre arquivos conda.yaml, consulte a documentaçãoMLflow.
API comando
Para log um modelo para o MLflow servidor de acompanhamento,mlflow.<model-type>.log_model(model, ...) use.
Para carregar um modelo registrado anteriormente para inferência ou desenvolvimento adicional, use mlflow.<model-type>.load_model(modelpath), em que modelpath é um dos seguintes:
- um caminho de modelo (como)(
models:/{model_id}somenteMLflow 3 ) - um caminho relativo à execução (como
runs:/{run_id}/{model-path}) - um caminho de volumes do Unity Catalog (como
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - um caminho de armazenamento de artefatos do MLflow-gerenciar que começa com
dbfs:/databricks/mlflow-tracking/ - um caminho de modelo registrado (como
models:/{model_name}/{model_stage}).
Para obter uma lista completa das opções de carregamento de modelos do MLflow, consulte Referência a artefatos na documentação do MLflow.
Para modelos Python MLflow, uma opção adicional é usar mlflow.pyfunc.load_model() para carregar o modelo como uma função Python genérica.
O senhor pode usar o seguinte trecho de código para carregar o modelo e pontuar os pontos de dados.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Como alternativa, o senhor pode exportar o modelo como um Apache Spark UDF para usar na pontuação de um clustering Spark, seja como um trabalho em lote ou como um trabalho de streamingSpark de tempo real.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
modelos de dependências registradas
Para carregar um modelo com precisão, o senhor deve se certificar de que as dependências do modelo sejam carregadas com as versões corretas no ambiente do Notebook. Em Databricks Runtime 10.5 ML e acima, MLflow avisa o senhor se for detectada uma incompatibilidade entre o ambiente atual e as dependências do modelo.
A funcionalidade adicional para simplificar a restauração de dependências de modelo está incluída no Databricks Runtime 11,0 MLe acima. No Databricks Runtime 11.0 MLe acima, para modelos de tipo pyfunc, você pode chamar mlflow.pyfunc.get_model_dependencies para recuperar e downloads as dependências do modelo. Esta função retorna um caminho para o arquivo de dependências que você pode instalar usando %pip install <file-path>. Ao carregar um modelo como um PySpark UDF, especifique env_manager="virtualenv" na chamada mlflow.pyfunc.spark_udf . Isso restaura as dependências do modelo no contexto do PySpark UDF e não afeta o ambiente externo.
Você também pode usar essa funcionalidade no Databricks Runtime 10.5 ou abaixo instalando manualmente o MLflow versão 1.25.0 ouacima:
%pip install "mlflow>=1.25.0"
Para obter informações adicionais sobre como modelar dependências registradas em log(Python e nãoPython) e artefatos, consulte modelos de dependências registradas.
Saiba como criar modelos logcom dependências e artefatos personalizados para o modelo servindo:
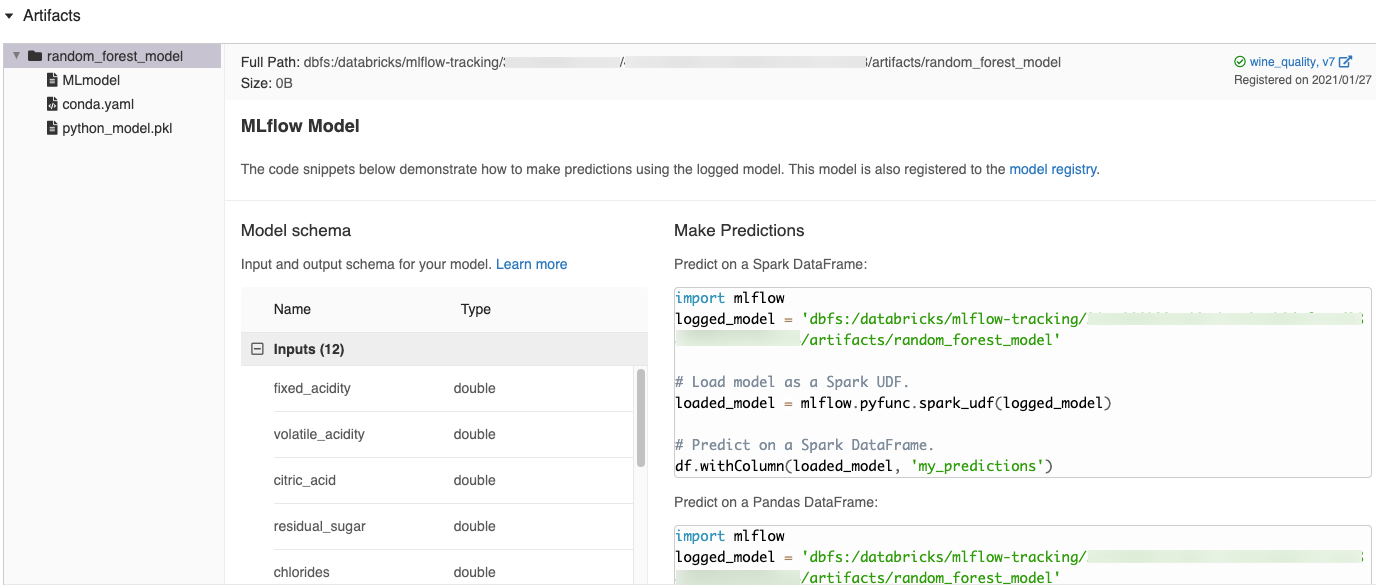
Trechos de código gerados automaticamente na interface do usuário do MLflow
Quando o senhor log um modelo em um Databricks Notebook, o Databricks gera automaticamente trechos de código que podem ser copiados e usados para carregar e executar o modelo. Para view esses trechos de código:
- Navegue até a tela de execução da execução que gerou o modelo. (Consulte a experiência de visualização do Notebook para saber como exibir a tela de execução).
- Role até a seção Artefatos .
- Clique no nome dos modelos registrados. Um painel é aberto à direita mostrando o código que o senhor pode usar para carregar os modelos registrados e fazer previsões em Spark ou Pandas DataFrames.
Exemplos
Para obter exemplos de modelos de registro, consulte os exemplos em Track machine learning treinamento execution examples.
modelos de registro no Model Registry
O senhor pode registrar modelos no MLflow Model Registry, um armazenamento de modelos centralizado que fornece uma interface de usuário e um conjunto de APIs para gerenciar todo o ciclo de vida dos modelos MLflow. Para obter instruções sobre como usar o site Model Registry para gerenciar modelos em Databricks Unity Catalog, consulte gerenciar o ciclo de vida do modelo em Unity Catalog. Para usar o Workspace Model Registry, consulte gerenciar o ciclo de vida do modelo usando o Workspace Model Registry (legado).
Quando os modelos criados com o MLflow 3 são registrados no Unity Catalog registro de modelo, o senhor pode view dados como parâmetros e métricas em um local central, em todos os experimentos e espaços de trabalho. Para obter informações, consulte Model Registry improvements with MLflow 3.
Para registrar um modelo usando o site API, use o seguinte comando:
- MLflow 3
- MLflow 2.x
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Salvar modelos em volumes do Unity Catalog
Para salvar um modelo localmente, use mlflow.<model-type>.save_model(model, modelpath). modelpath deve ser um caminho de volumes do Unity Catalog. Por exemplo, se o senhor usar um local de volumes do Unity Catalog dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models para armazenar o trabalho do projeto, deverá usar o caminho do modelo /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Para modelos MLlib, use o pipelineML.
download de modelos de artefatos
O senhor pode download os artefatos de modelos registrados (como arquivos de modelo, gráficos e métricas) para um modelo registrado com vários APIs.
Exemplo de API Python:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Exemplo de API Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Exemplo de comando da CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
modelos implantados para atendimento on-line
Antes de implantar seu modelo, é bom verificar se o modelo pode ser servido. Consulte a documentação do MLflow para saber como o senhor pode usar mlflow.models.predict para validar modelos antes da implementação.
Use Mosaic AI Model Serving para hospedar o modelo de aprendizado de máquina registrado em Unity Catalog registro de modelo como endpoint REST. Esses pontos de extremidade são atualizados automaticamente com base na disponibilidade de versões de modelos.