Orquestrar o Notebook e modularizar o código no Notebook
Saiba como orquestrar o Notebook e modularizar o código no Notebook. Veja exemplos e entenda quando usar métodos alternativos para a orquestração do Notebook.
Métodos de orquestração e modularização de código
A tabela a seguir compara os métodos disponíveis para orquestrar o Notebook e modularizar o código no Notebook.
Método | Caso de uso | Notas |
|---|---|---|
Notebook orquestração (recomendado) | Método recomendado para orquestrar o Notebook. Suporta fluxos de trabalho complexos com dependências de tarefas, programar e acionadores. Fornece uma abordagem robusta e escalável para cargas de trabalho de produção, mas requer instalação e configuração. | |
Notebook orquestração | Use começar um novo Job efêmero para cada chamada, o que pode aumentar a sobrecarga e carece de recurso avançado de programação. | |
Modularização de código (recomendada) | Método recomendado para modularizar o código. Modularize o código em arquivos de código reutilizáveis armazenados no site workspace. Oferece suporte ao controle de versão com repositórios e integração com IDEs para melhorar a depuração e os testes de unidade. Requer configuração adicional para gerenciar caminhos de arquivos e dependências. | |
Modularização de código | Use Basta importar funções ou variáveis de outro Notebook, executando-as em linha. Útil para prototipagem, mas pode levar a um código fortemente acoplado que é mais difícil de manter. Não suporta passagem de parâmetros ou controle de versão. |
%run vs. dbutils.notebook.run()
O comando %run permite que o senhor inclua outro Notebook dentro de um Notebook. O senhor pode usar %run para modularizar o código, colocando as funções de suporte em um Notebook separado. O senhor também pode usá-lo para concatenar o Notebook que implementa as etapas de uma análise. Quando o senhor usa %run, o Notebook chamado é imediatamente executado e as funções e variáveis nele definidas ficam disponíveis no Notebook de chamada.
O dbutils.notebook API complementa o %run porque permite que o senhor passe parâmetros e retorne valores de um Notebook. Isso permite que o senhor crie fluxos de trabalho complexos e pipelines com dependências. Por exemplo, o senhor pode obter uma lista de arquivos em um diretório e passar os nomes para outro Notebook, o que é impossível com %run. O senhor também pode criar fluxos de trabalho if-then-else com base em valores de retorno.
Ao contrário do %run, o método dbutils.notebook.run() inicia um novo trabalho para executar o notebook.
Como todas as APIs dbutils, esses métodos estão disponíveis apenas em Python e Scala. No entanto, o senhor pode usar dbutils.notebook.run() para chamar um R Notebook.
Use o site %run para importar um Notebook
Neste exemplo, o primeiro notebook define uma função, reverse, que fica disponível no segundo notebook depois que você usa mágica %run para executar shared-code-notebook.
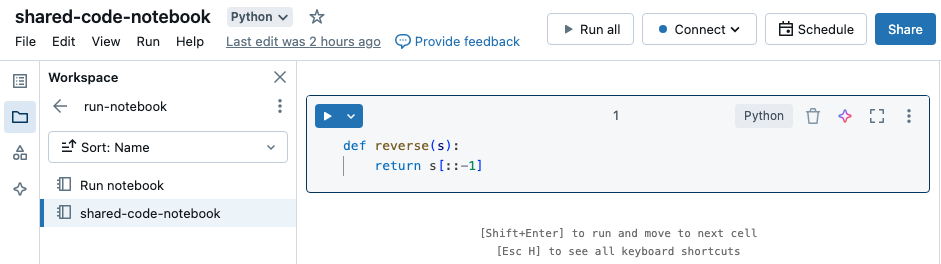
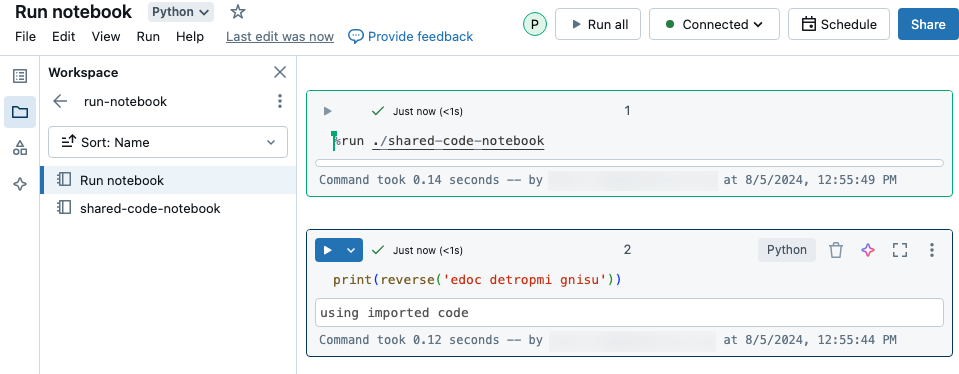
Como ambos os Notebooks estão no mesmo diretório em workspace, use o prefixo ./ em ./shared-code-notebook para indicar que o caminho deve ser resolvido em relação ao Notebook em execução no momento. O senhor pode organizar o Notebook em diretórios, como %run ./dir/notebook, ou usar um caminho absoluto, como %run /Users/username@organization.com/directory/notebook.
%rundeve estar em uma célula própria , pois executa todo o notebook em linha.- O senhor não pode usar
%runpara executar um arquivo Python eimportas entidades definidas nesse arquivo em um Notebook. Para importar de um arquivo Python, consulte Modularize seu código usando arquivos. Ou então, pacote o arquivo em uma Python biblioteca, crie uma Databricks biblioteca a partir dessa Python biblioteca e instale a biblioteca no clustering que o senhor usa para executar o Notebook. - Quando o senhor usa
%runpara executar um Notebook que contém widgets, default a execução do Notebook especificado com os valores default do widget. O senhor também pode passar valores para os widgets; consulte Use Databricks widgets with %run.
Use dbutils.notebook.run para começar um novo trabalho
Executa um notebook e retorna seu valor de saída. O método inicia um trabalho curto que é executado imediatamente.
Os métodos disponíveis na API do dbutils.notebook são run e exit. Ambos os parâmetros e valores de retorno devem ser strings.
run(path: String, timeout_seconds: int, arguments: Map): String
O parâmetro timeout_seconds controla o tempo limite da execução (0 significa que não há tempo limite). A chamada para
run lança uma exceção se ela não terminar dentro do tempo especificado. Se o site Databricks ficar inativo por mais de 10 minutos,
a execução do Notebook falhará independentemente do timeout_seconds.
O parâmetro arguments define os valores de widget do Notebook de destino. Especificamente, se o Notebook que o senhor estiver executando tiver um widget chamado A e o senhor passar um par key-value ("A": "B") como parte do parâmetro de argumentos para a chamada run(), a recuperação do valor do widget A retornará "B". O senhor pode encontrar as instruções para criar e trabalhar com widgets nos artigos Databricks widgets.
- O parâmetro
argumentsaceita apenas caracteres latinos (conjunto de caracteres ASCII). Usar caracteres não ASCII retorna um erro. - Os trabalhos criados usando a API
dbutils.notebookdevem ser concluídos em 30 dias ou menos.
run Uso
- Python
- Scala
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Passar dados estruturados entre o Notebook
Esta seção ilustra como passar dados estruturados entre notebooks.
- Python
- Scala
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Lidar com erros
Esta seção ilustra como lidar com erros.
- Python
- Scala
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
execução de vários Notebooks ao mesmo tempo
O senhor pode executar vários Notebooks ao mesmo tempo usando os construtores padrão Scala e Python, como Threads (Scala, Python) e Futuros (Scala, Python). O exemplo do Notebook demonstra como usar essas construções.
- Faça o download dos quatro Notebooks a seguir. O Notebook está escrito em Scala.
- Importe os cadernos em uma única pasta no workspace.
- Execute o notebook Executar simultaneamente .