Tipos de visualização do editorNotebook e SQL
Esta página descreve os tipos de visualizações disponíveis para uso no Databricks Notebook e no editor SQL , e mostra como criar um exemplo de cada tipo de visualização.
Esta página aborda visualizações para Databricks Notebook e o editor SQL . Para visualizações em painéis de AI/BI , consulte Tipos de visualizaçãoAI/BI dashboard.
Gráfico de área
Os gráficos de área combinam o gráfico de linhas e barras para mostrar como os valores numéricos de um ou mais grupos mudam ao longo da progressão de uma segunda variável, normalmente a do tempo. Elas são frequentemente usadas para mostrar as mudanças no funnel ao longo do tempo.
Os gráficos de área suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
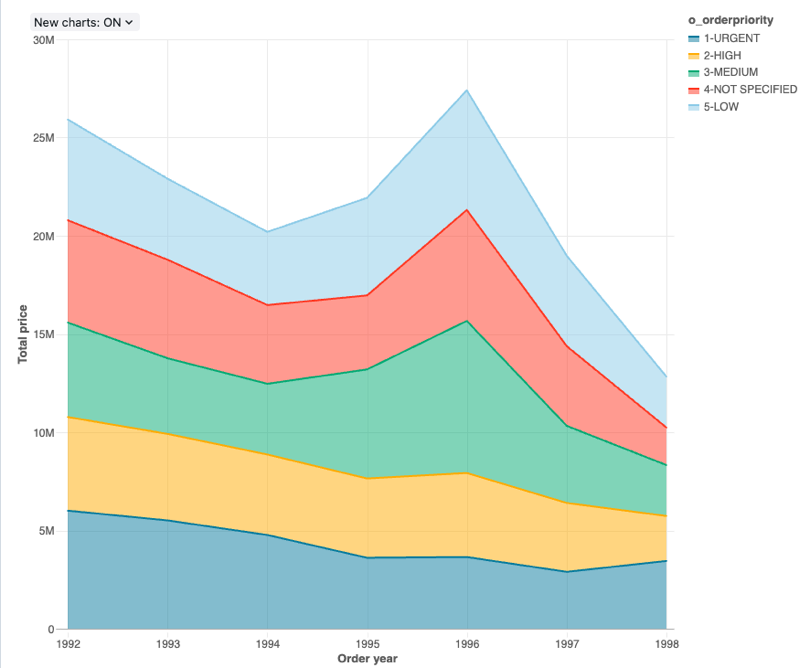
Valores de configuração : Para essa visualização do gráfico de área, os seguintes valores foram definidos:
-
Coluna X:
- coluna do conjunto de dados:
o_orderdate - Nível de data:
Years
- coluna do conjunto de dados:
-
Colunas Y:
- coluna do conjunto de dados:
o_totalprice - Tipo de agregação:
Sum
- coluna do conjunto de dados:
-
Group by (dataset coluna):
o_orderpriority -
Empilhamento:
Stack -
Nome do eixo X (substitui o valor de default ):
Order year -
Nome do eixo Y (substitui o valor de default ):
Total price
Opções de configuração : Para opções de configuração do gráfico de área, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico de área, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Gráfico de barras
Os gráficos de barras representam a mudança nas métricas ao longo do tempo ou para mostrar proporcionalidade, semelhante a um pie gráfico.
Os gráficos de barras suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
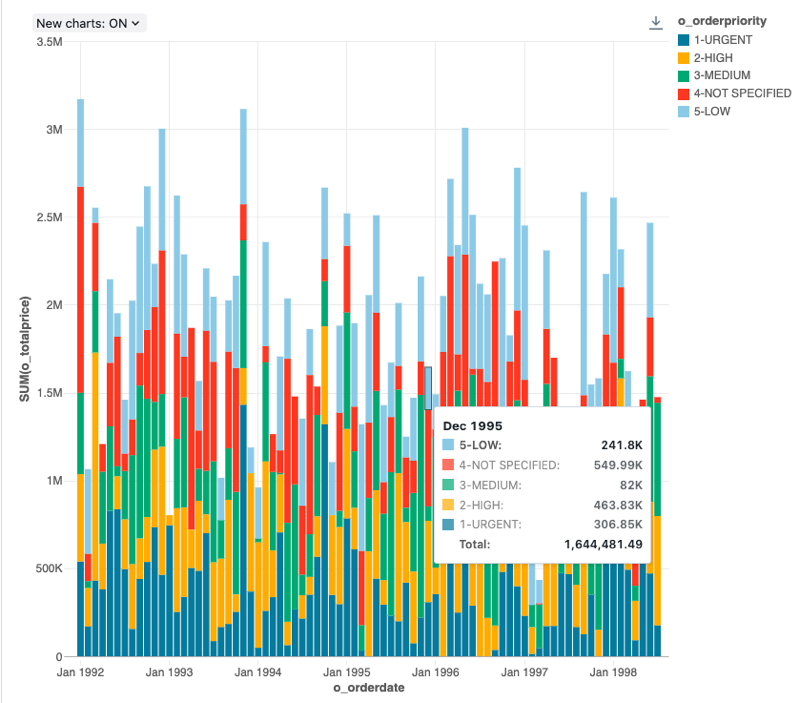
Valores de configuração : Para essa visualização do gráfico de barras, os seguintes valores foram definidos:
-
Coluna X:
- coluna do conjunto de dados:
o_orderdate - Nível de data:
Months
- coluna do conjunto de dados:
-
Colunas Y:
- coluna do conjunto de dados:
o_totalprice - Tipo de agregação:
Sum
- coluna do conjunto de dados:
-
Group by (dataset coluna):
o_orderpriority -
Empilhamento:
Stack -
Nome do eixo X (substitui o valor de default ):
Order month -
Nome do eixo Y (substitui o valor de default ):
Total price
Opções de configuração : Para opções de configuração do gráfico de barras, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico de barras, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Gráfico de bolhas
Os gráficos de bolhas são gráficos de dispersão em que o tamanho de cada marcador de ponto reflete uma métrica relevante.
Os gráficos de bolhas suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
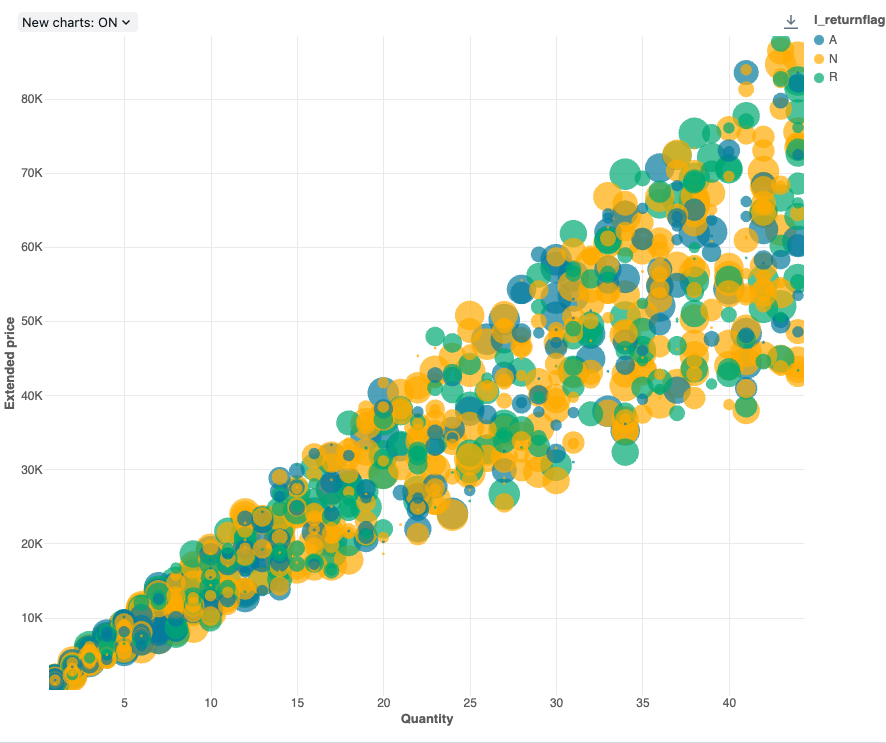
Valores de configuração : Para essa visualização do gráfico de bolhas, os seguintes valores foram definidos:
- X (colunadataset ):
l_quantity - Colunas Y (dataset column):
l_extendedprice - Group by (dataset coluna):
l_returnflag - Coluna de tamanho da bolha (dataset column):
l_tax - Coeficiente de tamanho da bolha: 20
- Tamanho da bolha proporcional a:
Area - Nome do eixo X (substitui o valor de default ):
Quantity - Nome do eixo Y (substitui o valor de default ):
Extended price
Opções de configuração : Para opções de configuração do gráfico de bolhas, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico de bolhas, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.lineitem where l_quantity < 45
Gráfico de caixas
A visualização do gráfico de caixas mostra o resumo da distribuição dos dados numéricos, opcionalmente agrupados por categoria. Usando uma visualização de gráfico de caixas, você pode comparar rapidamente os intervalos de valores entre as categorias e visualizar os grupos de localidade, dispersão e assimetria dos valores por meio de seus quartis. Em cada caixa, a linha mais escura mostra o intervalo interquartil. Para obter mais informações sobre como interpretar visualizações de gráficos de caixa, consulte os artigos sobre gráficos de caixa na Wikipedia.
Os gráficos de caixa só oferecem suporte à agregação de até 64.000 linhas. Se o site dataset tiver mais de 64.000 linhas, os dados serão truncados.
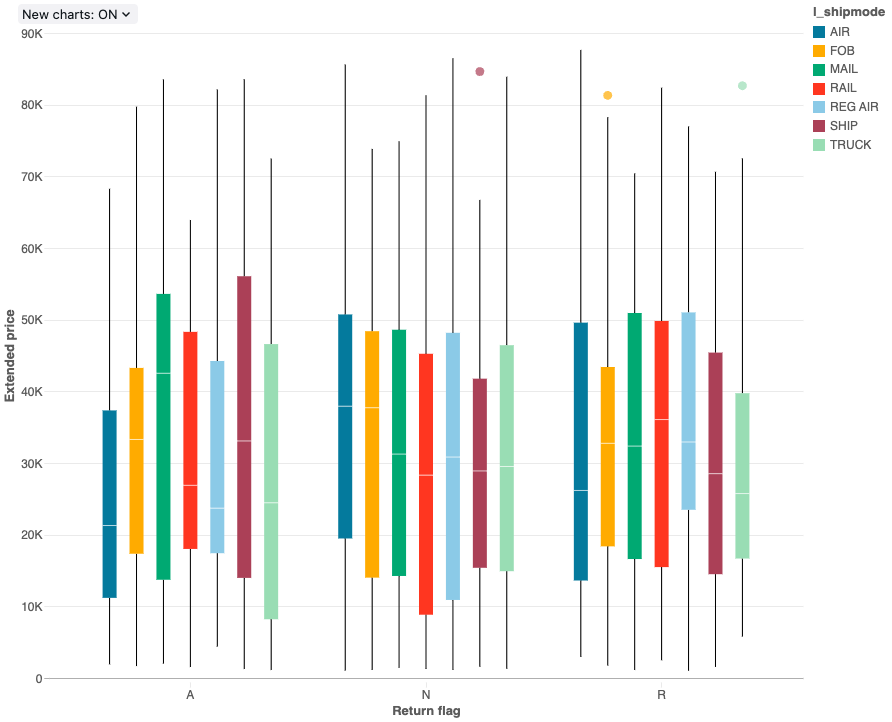
Valores de configuração : Para essa visualização do gráfico de caixa, os seguintes valores foram definidos:
- Coluna X (dataset column):
l_returnflag - Colunas Y (dataset column):
l_extendedprice - Group by (dataset coluna):
l_shipmode - Nome do eixo X (substitui o valor de default ):
Return flag - Nome do eixo Y (substitui o valor de default ):
Extended price
Opções de configuração : Para opções de configuração de gráfico de caixa, consulte opções de configuração de gráfico de caixa.
Consulta SQL : Para essa visualização de gráfico de caixa, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.lineitem
Análise de coorte
Uma análise de coorte examina os resultados de grupos predeterminados, chamados de coortes, à medida que avançam em um conjunto de estágios. A visualização de coorte só agrega mais de datas (ela permite agregações mensais). Ele não faz nenhuma outra agregação de dados no conjunto de resultados. Todas as outras agregações são feitas dentro da própria consulta.
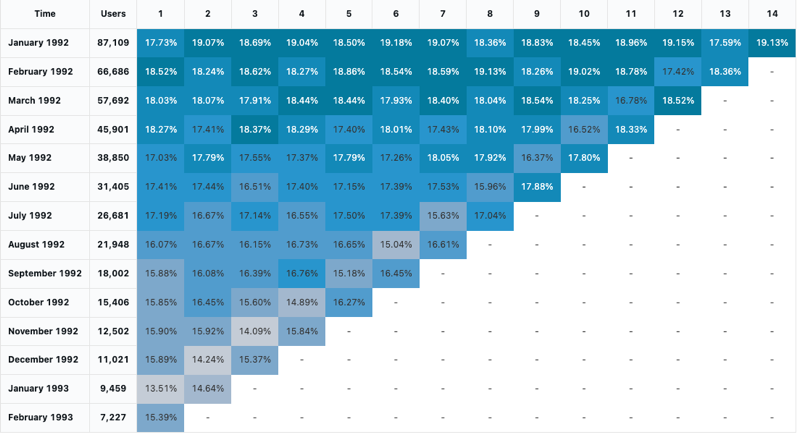
Valores de configuração : Para essa visualização de coorte, os seguintes valores foram definidos:
- Data (bucket) (coluna do banco de dados):
cohort_month - Estágio (coluna do banco de dados):
months - Tamanho da população do balde (coluna do banco de dados):
size - Valor do estágio (coluna do banco de dados):
active - Intervalo de tempo:
monthly
Opções de configuração: para opções de configuração de coorte, consulte opções de configuração de gráfico de coorte.
Consulta SQL : Para essa visualização de coorte, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Gráfico combinado
Os gráficos combinados combinam gráficos de linhas e barras para apresentar as mudanças ao longo do tempo com proporcionalidade.
Os gráficos combinados oferecem suporte a agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
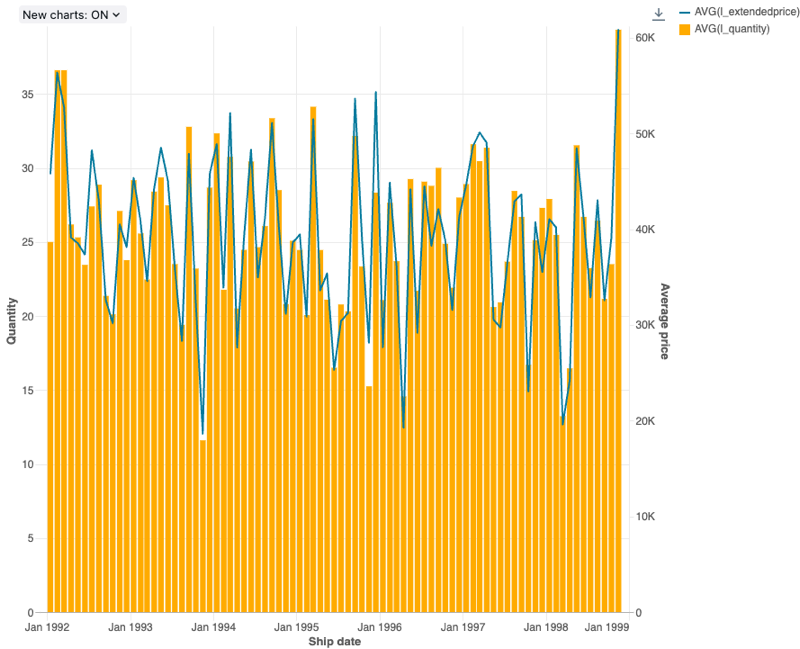
Valores de configuração : Para essa visualização do gráfico combinado, os seguintes valores foram definidos:
-
Coluna X:
- coluna do conjunto de dados:
l_shipdate - Nível de data:
Months
- coluna do conjunto de dados:
-
Colunas Y:
- Primeira coluna dataset:
l_extendedprice - Tipo de agregação: média
- Segunda coluna dataset:
l_quantity - Tipo de agregação: média
- Primeira coluna dataset:
-
Nome do eixo X (substitui o valor de default ):
Ship date -
Nome do eixo Y esquerdo (substitui o valor de default ):
Quantity -
Nome do eixo Y direito (substitui o valor de default ):
Average price -
Série:
- Order1 (colunadataset ):
AVG(l_extendedprice) - Eixo Y: direito
- Tipo: Linha
- Order2 (colunadataset ):
AVG(l_quantity) - Eixo Y: esquerdo
- Tipo: Bar
- Order1 (colunadataset ):
Opções de configuração : Para opções de configuração do gráfico combinado, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico combinado, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.lineitem
Display de balcão
Os contadores exibem um único valor de forma proeminente, com a opção de compará-los com um valor alvo. Para usar contadores, especifique qual linha de dados será exibida na visualização do contador para a coluna de valor e a coluna de destino .
O contador só oferece suporte à agregação de até 64.000 linhas. Se o site dataset tiver mais de 64.000 linhas, os dados serão truncados.

Valores de configuração : Para essa visualização do contador, os seguintes valores foram definidos:
-
Coluna Valor
- coluna do conjunto de dados:
avg(o_totalprice) - Fila: 1
- coluna do conjunto de dados:
-
Coluna-alvo:
- coluna do conjunto de dados:
avg(o_totalprice) - Fila: 2
- coluna do conjunto de dados:
-
Valor alvo do formato: Ativar
Consulta SQL : Para essa visualização de contador, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
visualização de funil
A visualização funnel ajuda a analisar a mudança em uma métrica em diferentes estágios. Para usar o funnel, especifique uma coluna step e uma value.
O funil suporta apenas a agregação de até 64.000 linhas. Se o site dataset tiver mais de 64.000 linhas, os dados serão truncados.
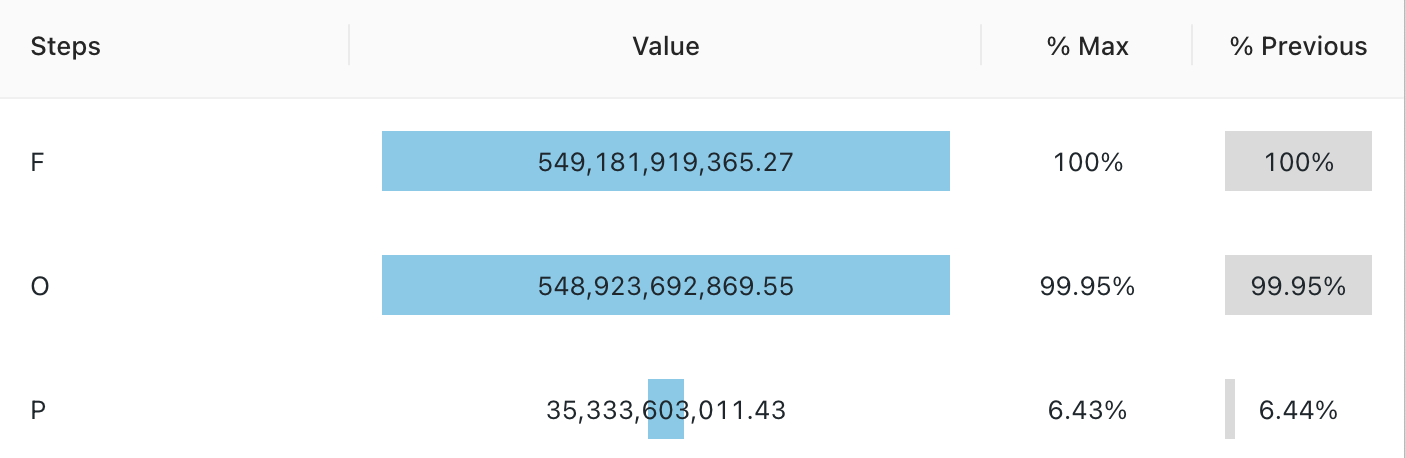
Valores de configuração : Para essa visualização do site funnel, foram definidos os seguintes valores:
- Coluna de passos (dataset column):
o_orderstatus - Coluna de valor (dataset column):
Revenue
SQL consulta : Para essa visualização funnel, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
Gráfico de mapa de calor
Os gráficos de mapa de calor misturam recursos de gráficos de barras, empilhamento e gráficos de bolhas, permitindo que o senhor visualize cores de uso numérico de dados. Uma paleta de cores comum para um mapa de calor mostra os valores mais altos usando cores mais quentes, como laranja ou vermelho, e os valores mais baixos usando cores mais frias, como azul ou roxo.
Por exemplo, considere o mapa de calor a seguir, que visualiza as distâncias mais frequentes das corridas de táxi em cada dia e agrupa os resultados por dia da semana, distância e tarifa total.
Os gráficos de mapa de calor suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
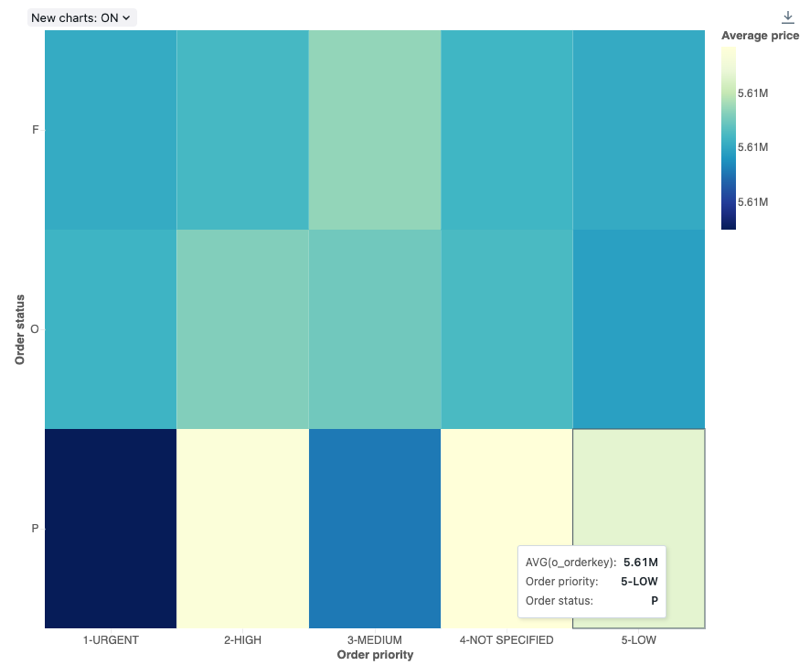
Valores de configuração : Para essa visualização do gráfico de mapa de calor, os seguintes valores foram definidos:
-
Coluna X (dataset column):
o_orderpriority -
Colunas Y (dataset column):
o_orderstatus -
Coluna de cores:
- coluna do conjunto de dados:
o_totalprice - Tipo de agregação:
Average
- coluna do conjunto de dados:
-
Nome do eixo X (substitui o valor de default ):
Order priority -
Nome do eixo Y (substitui o valor de default ):
Order status -
Nome da cor (substitui o valor de default ):
Average price -
Esquema de cores (substitui o valor de default ):
YIGnBu
Opções de configuração: Para opções de configuração do mapa de calor, consulte as opções de configuração do gráfico de mapa de calor.
Consulta SQL : Para essa visualização de gráfico de mapa de calor, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Gráficos de histograma
Um histograma mostra a frequência com que um determinado valor ocorre em um dataset. Um histograma ajuda o senhor a entender se um dataset tem valores que estão agrupados em torno de um pequeno número de intervalos ou se estão mais espalhados. Um histograma é exibido como um gráfico de barras no qual você controla o número de barras distintas (também chamadas de compartimentos).
Os gráficos de histograma suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
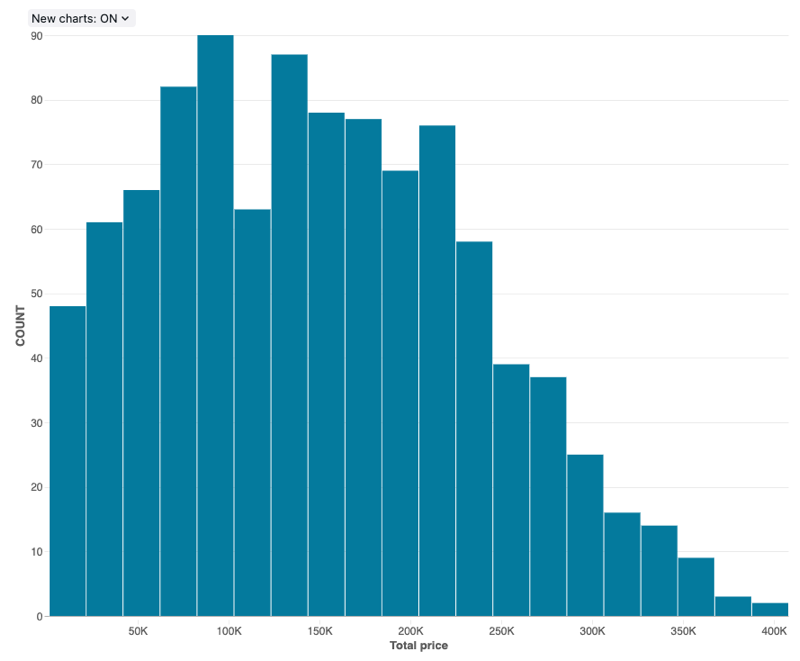
Valores de configuração : Para essa visualização do gráfico de histograma, os seguintes valores foram definidos:
- Coluna X (dataset column):
o_totalprice - Número de caixas: 20
- Nome do eixo X (substitui o valor de default ):
Total price
Opções de configuração: Para opções de configuração do gráfico de histograma, consulte as opções de configuração do gráfico de histograma.
Consulta SQL : Para essa visualização de gráfico de histograma, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Gráfico de linhas
Os gráficos de linhas apresentam a mudança em uma ou mais métricas ao longo do tempo.
Os gráficos de linhas suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
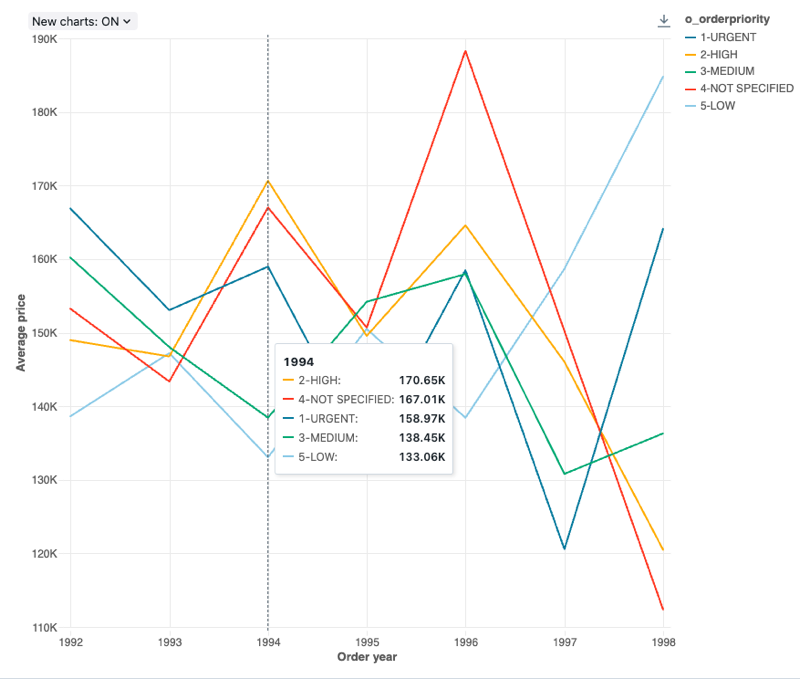
Valores de configuração : Para essa visualização do gráfico de linhas, os seguintes valores foram definidos:
-
Coluna X:
- coluna do conjunto de dados:
o_orderdate - Nível de data:
Years
- coluna do conjunto de dados:
-
Colunas Y:
- coluna do conjunto de dados:
o_totalprice - Tipo de agregação:
Average
- coluna do conjunto de dados:
-
Group by (dataset coluna):
o_orderpriority -
Nome do eixo X (substitui o valor de default ):
Order year -
Nome do eixo Y (substitui o valor de default ):
Average price
Opções de configuração : Para opções de configuração do gráfico de linha, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico de linhas, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Visualização do mapa (coroplético)
Nas visualizações coropléticas, as localidades geográficas, como países ou estados, são coloridas de acordo com os valores agregados de cada coluna do site key. A consulta deve retornar localizações geográficas pelo nome.
As visualizações coropléticas não fazem nenhuma agregação de dados no conjunto de resultados. Todas as agregações devem ser computadas na própria consulta.
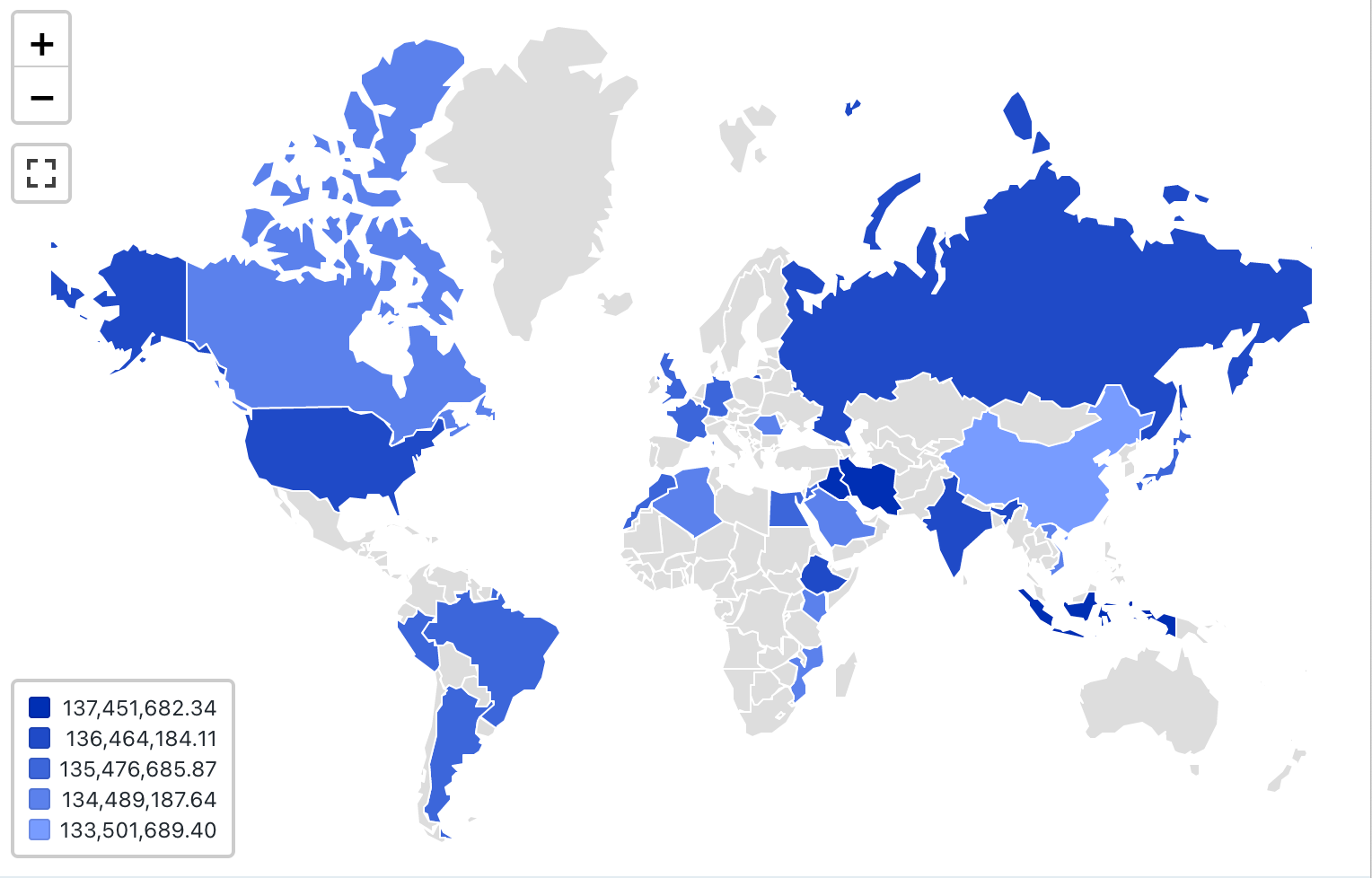
Valores de configuração : Para essa visualização coroplética, os seguintes valores foram definidos:
- Map (dataset column):
Countries - Coluna geográfica (dataset column):
Country - Tipo geográfico: Nome curto
- Coluna de valor (dataset column):
Revenue - modo de agrupamento: equidistante
Opções de configuração: Para opções de configuração do coroplético, consulte as opções de configuração do coroplético.
Consulta SQL : Para essa visualização coroplética, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Visualização de mapas (marcadores)
Nas visualizações de marcadores, um marcador é colocado em um conjunto de coordenadas no mapa. O resultado da consulta deve retornar pares de latitude e longitude.
O Marker não faz nenhuma agregação de dados no conjunto de resultados. Todas as agregações devem ser computadas na própria consulta.
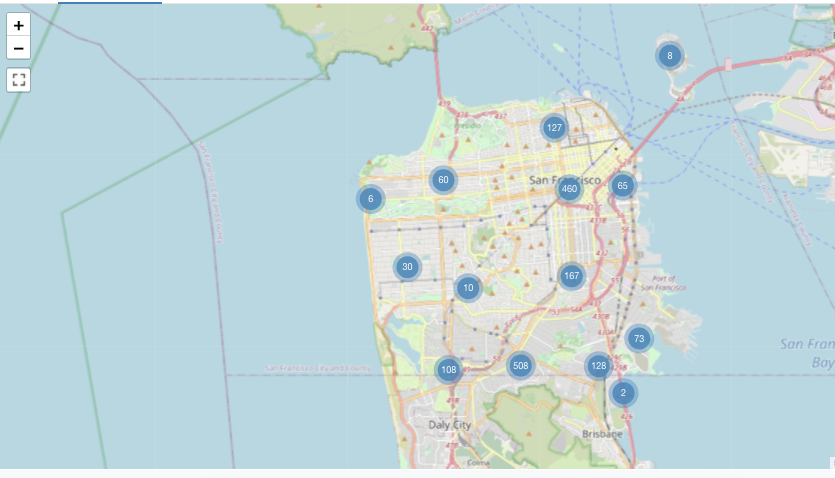
Esse exemplo de marcador é gerado a partir de um site dataset que inclui valores de latitude e longitude, que não estão disponíveis no conjunto de dados de amostra Databricks. Para opções de configuração do coroplético, consulte as opções de configuração do marcador.
gráficos de pizza
Os gráficos de pizza mostram a proporcionalidade entre as métricas. Eles não se destinam a transmitir dados de séries temporais.
Os gráficos de pizza suportam agregações de backend, oferecendo suporte a consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
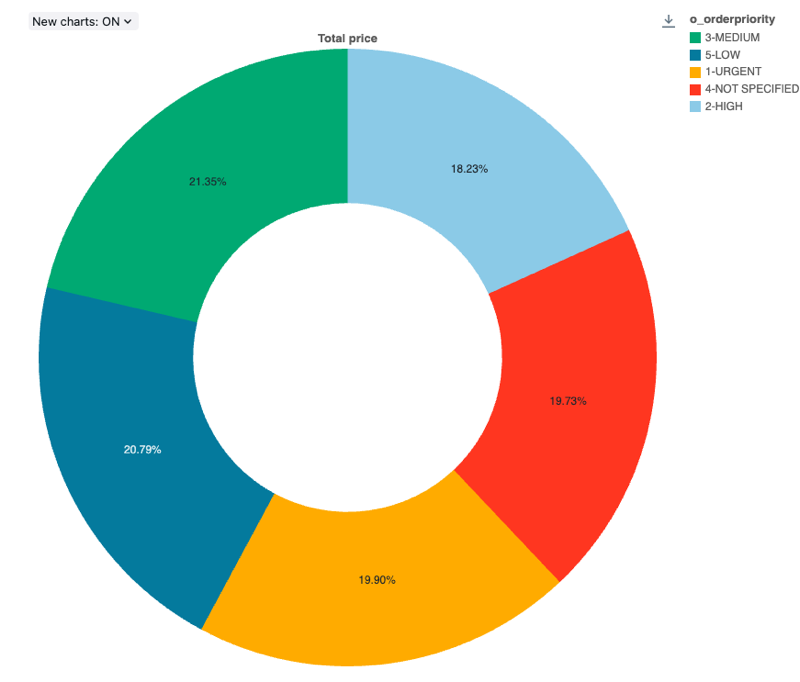
Valores de configuração : Para essa visualização do gráfico pie, foram definidos os seguintes valores:
-
Coluna X (dataset column):
o_orderpriority -
Colunas Y:
- coluna do conjunto de dados:
o_totalprice - Tipo de agregação:
Sum
- coluna do conjunto de dados:
-
rótulo (override default value):
Total price
Opções de configuração : Para conhecer as opções de configuração do gráfico pie, consulte opções de configuração do gráfico.
SQL consulta : Para essa visualização do gráfico pie, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders
Visualização da tabela dinâmica
Uma visualização de tabela dinâmica agrega registros do resultado de uma consulta em uma nova exibição tabular. É semelhante às declarações PIVOT ou GROUP BY no SQL. Você configura a visualização da tabela dinâmica com campos de arrastar e soltar.
As tabelas dinâmicas suportam agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados. No entanto, a tabela dinâmica (antiga) só oferece suporte à agregação de até 64.000 linhas. Se o site dataset tiver mais de 64.000 linhas, os dados serão truncados.
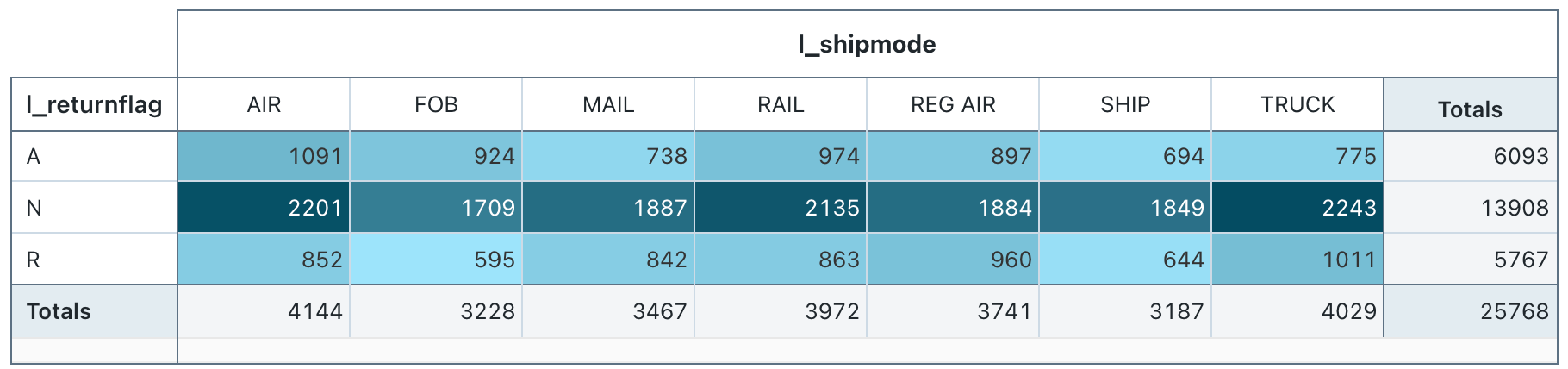
Valores de configuração : Para essa visualização de tabela dinâmica, os seguintes valores foram definidos:
- Selecione as linhas (colunadataset ):
l_returnflag - Selecione as colunas (dataset column):
l_shipmode - Célula
- coluna do conjunto de dados:
l_quantity - Tipo de agregação: Soma
- Células de cor por valor: Ativado
- coluna do conjunto de dados:
Consulta SQL : Para essa visualização de tabela dinâmica, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.lineitem
Sankey
Um diagrama de Sankey visualiza o fluxo de um conjunto de valores para outro.
As visualizações Sankey não fazem nenhuma agregação de dados no conjunto de resultados. Todas as agregações devem ser computadas na própria consulta.

Consulta SQL : Para essa visualização Sankey, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Gráfico de dispersão
As visualizações de dispersão são comumente usadas para mostrar a relação entre duas variáveis numéricas. Além disso, uma terceira dimensão pode ser codificada com cores para mostrar como as variáveis numéricas são diferentes entre os grupos.
Os gráficos de dispersão oferecem suporte a agregações de back-end, fornecendo suporte para consultas que retornam mais de 64 mil linhas de dados sem truncar o conjunto de resultados.
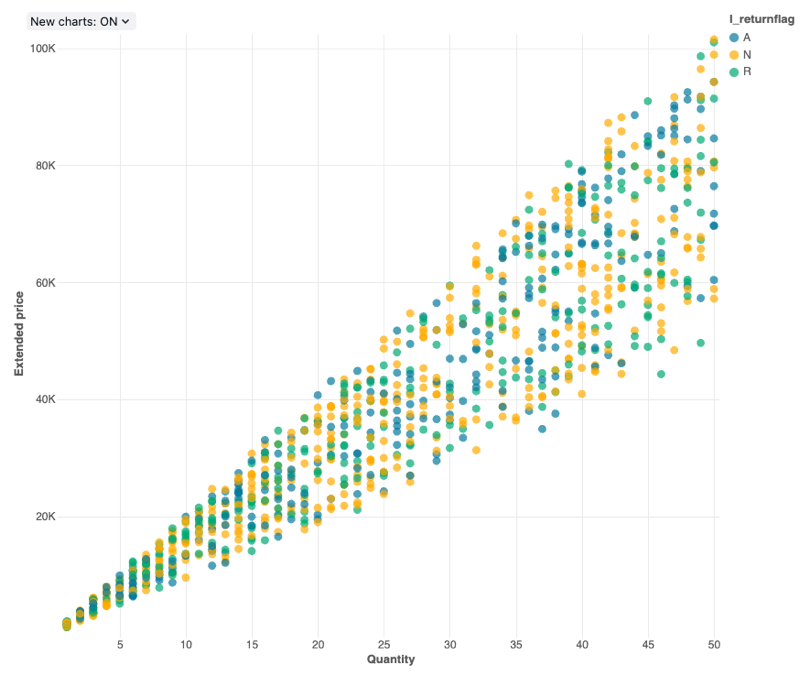
Valores de configuração : Para essa visualização do gráfico de dispersão, os seguintes valores foram definidos:
- Coluna X (dataset column):
l_quantity - Coluna Y (dataset column):
l_extendedprice - Group by (dataset coluna):
l_returnflag - Nome do eixo X (substitui o valor de default ):
Quantity - Nome do eixo Y (substitui o valor de default ):
Extended price
Opções de configuração : Para opções de configuração do gráfico de dispersão, consulte as opções de configuração do gráfico.
Consulta SQL : Para essa visualização de gráfico de dispersão, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.lineitem
Sequência Sunburst
Um diagrama sunburst ajuda a visualizar o uso hierárquico de dados em círculos concêntricos.
A sequência Sunburst não faz nenhuma agregação de dados no conjunto de resultados. Todas as agregações devem ser computadas na própria consulta.
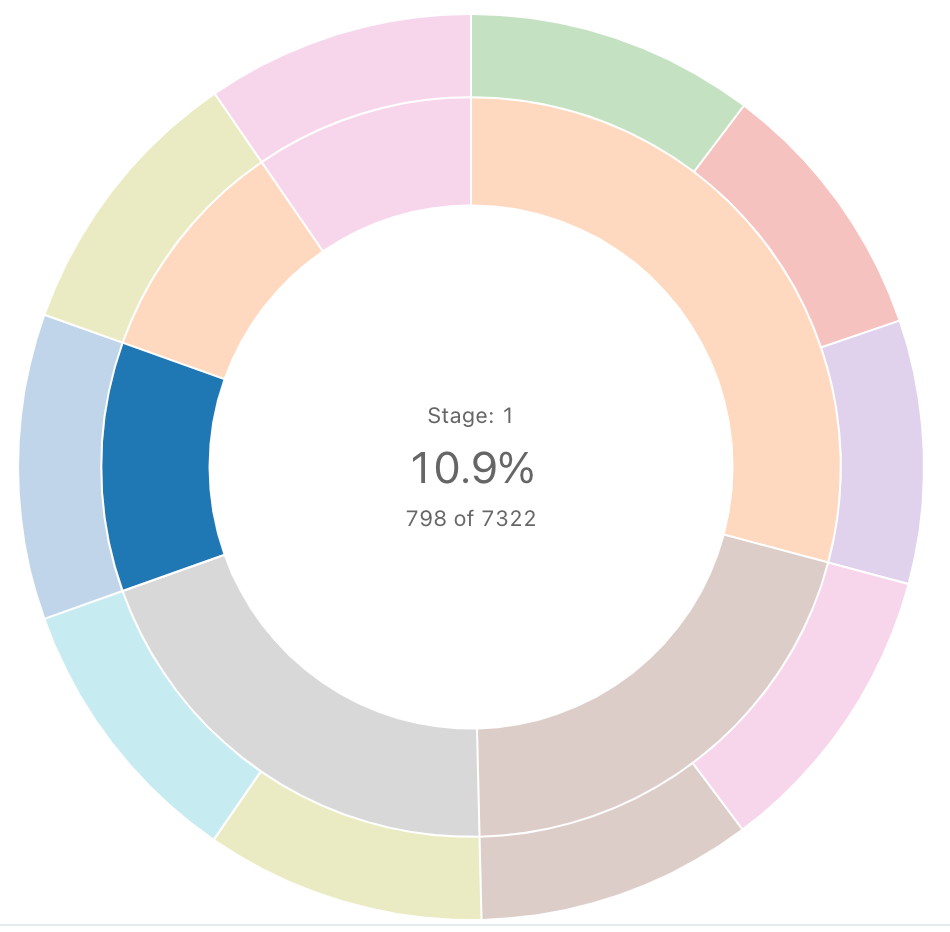
Consulta SQL : Para essa visualização de explosão solar, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Tabela
A visualização da tabela exibe dados em uma tabela padrão, mas com a capacidade de reordenar, ocultar e formatar manualmente os dados. As visualizações de tabela podem exibir até 100.000 linhas.
As visualizações de tabela não fazem nenhuma agregação de dados no conjunto de resultados. Todas as agregações devem ser computadas na própria consulta.
As configurações de formatação suportam tipos de dados especiais, como imagens, JSON e URLs. Para obter mais detalhes, consulte as opções de configuração da tabela.
Nuvem de palavras
Uma nuvem de palavras representa visualmente a frequência com que uma palavra ocorre nos dados.
A nuvem de palavras só oferece suporte à agregação de até 64.000 linhas. Se o site dataset tiver mais de 64.000 linhas, os dados serão truncados.
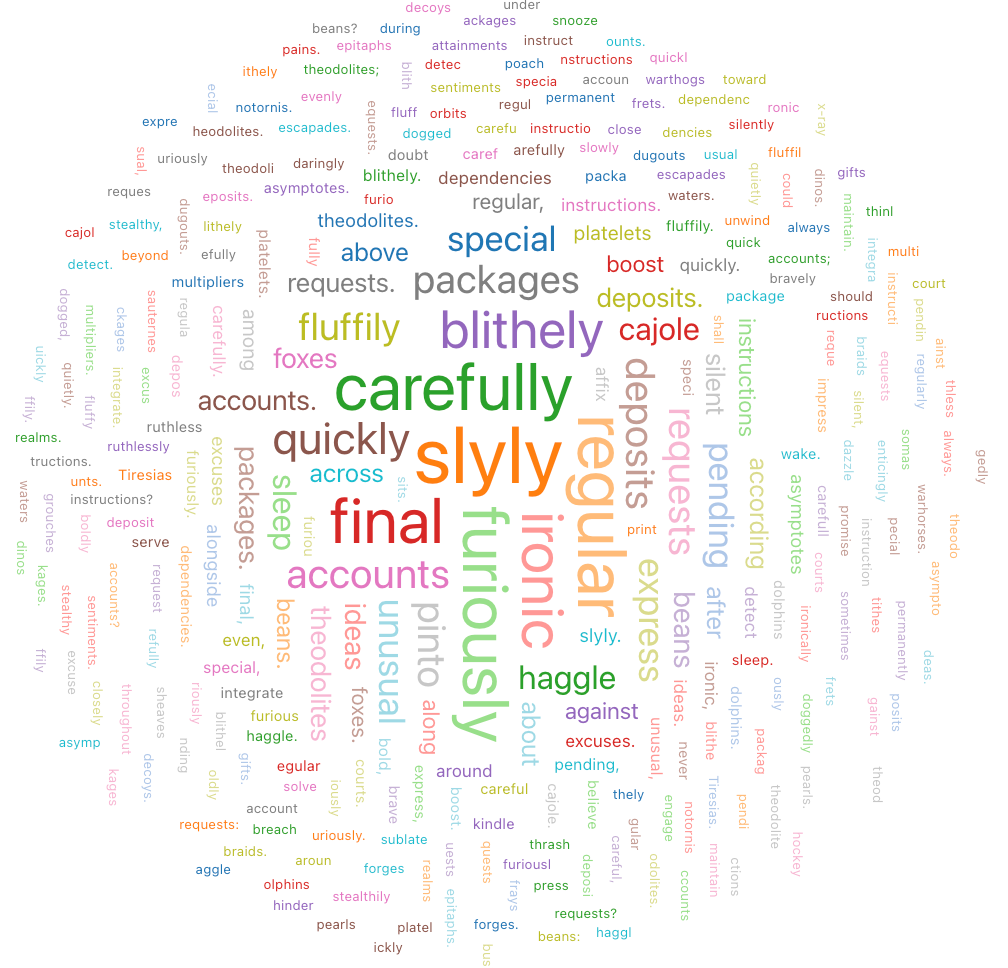
Valores de configuração : Para essa visualização de nuvem de palavras, os seguintes valores foram definidos: teste
- Coluna de palavras (dataset column):
o_comment - Limite de comprimento de palavras: Min = 5
- Limite de frequências: Min = 2
Consulta SQL : Para essa visualização de nuvem de palavras, a seguinte consulta SQL foi usada para gerar o conjunto de dados.
select * from samples.tpch.orders