MLflow on Databricks
This article describes how MLflow on Databricks is used to develop high-quality generative AI agents and machine learning models.
If you're just getting started with Databricks, consider trying MLflow on Databricks Free Edition.
What is MLflow?
MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize production-quality AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence.
MLflow's comprehensive feature set for agents and LLM applications includes production-grade observability, evaluation, prompt management, an AI Gateway for managing costs and model access, and more.
For machine learning (ML) model development, MLflow provides experiment tracking, model evaluation capabilities, a production model registry, and model deployment tools.
MLflow supports any LLM provider, agent framework, ML library, and programming language. MLflow provides native SDKs for Python, TypeScript/JavaScript, Java, and R.
MLflow 3
MLflow 3 on Databricks delivers state-of-the-art observability, evaluation, and prompt management for agents and LLM applications. For ML model development, MLflow 3 provides experiment tracking, model evaluation, a production model registry, and model deployment tools. Using MLflow 3 on Databricks, you can:
-
Centrally track and analyze the performance of your models, AI applications, and agents across all environments, from interactive queries in a development notebook through production batch or real-time serving deployments.
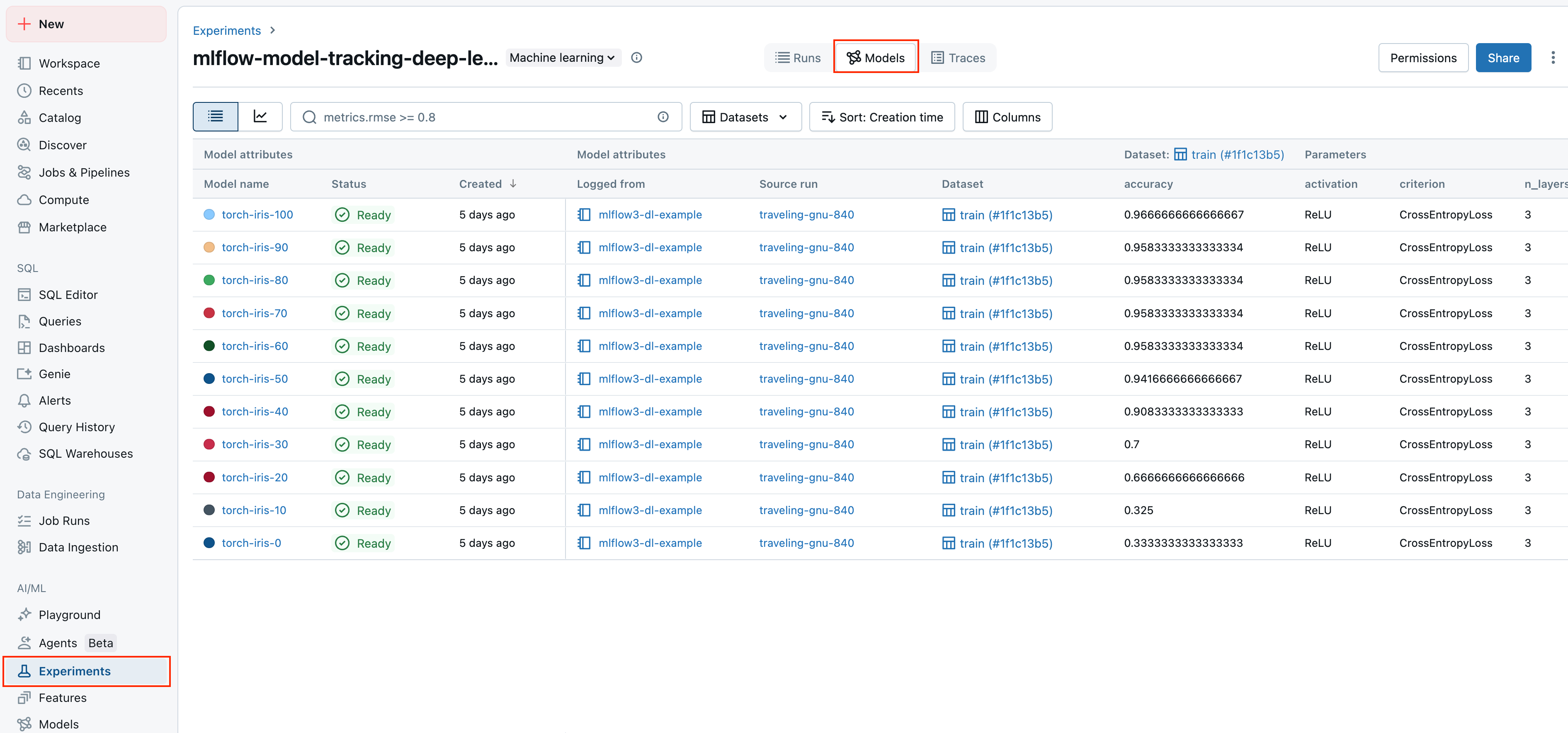
-
Orchestrate evaluation and deployment workflows using Unity Catalog and access comprehensive status logs for each version of your model, AI application, or agent.
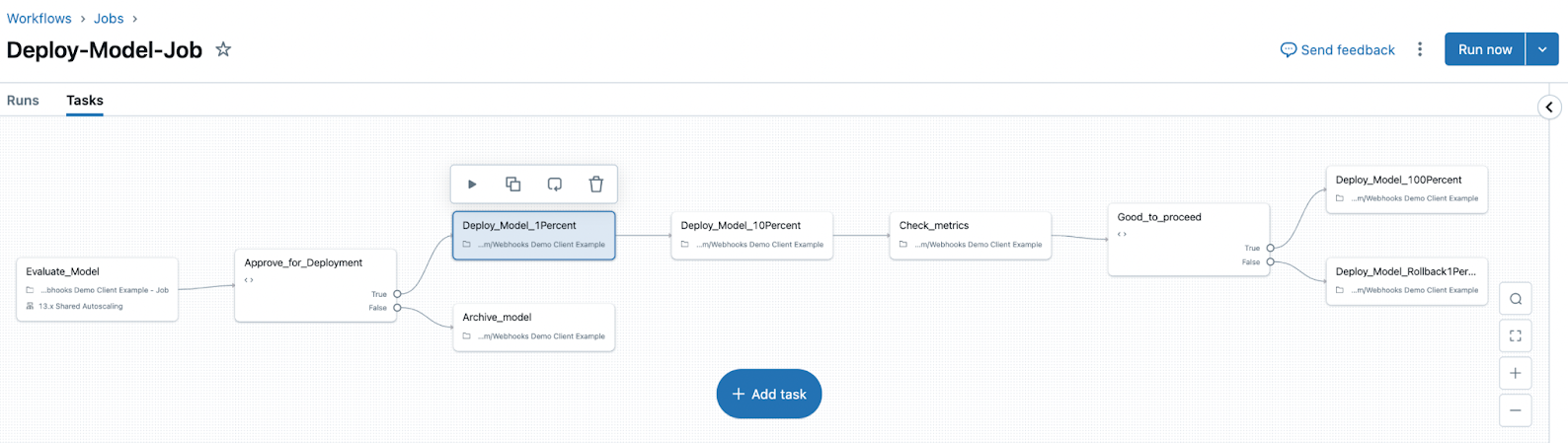
-
View and access model metrics and parameters from the model version page in Unity Catalog and from the REST API.
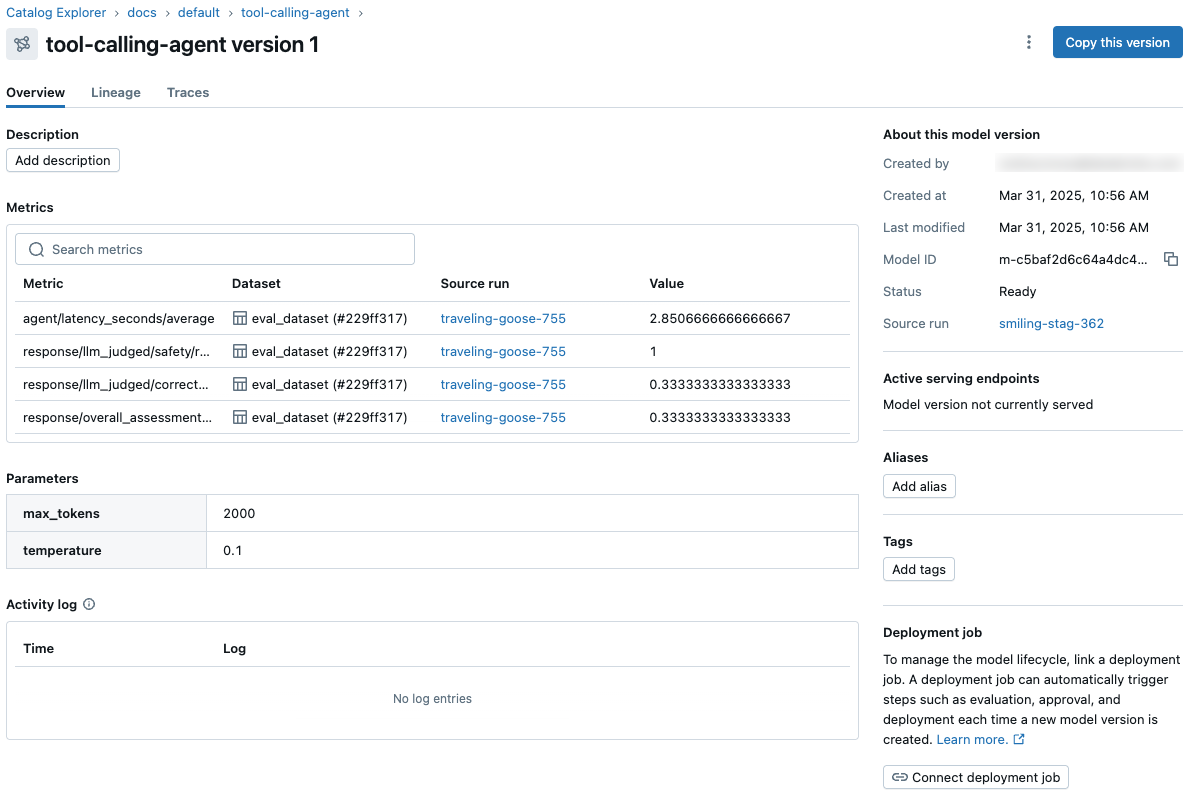
-
Annotate requests and responses (traces) for all of your gen AI applications and agents, enabling human experts and automated techniques (such as LLM-as-a-judge) to provide rich feedback. You can leverage this feedback to assess and compare the performance of application versions and to build datasets for improving quality.
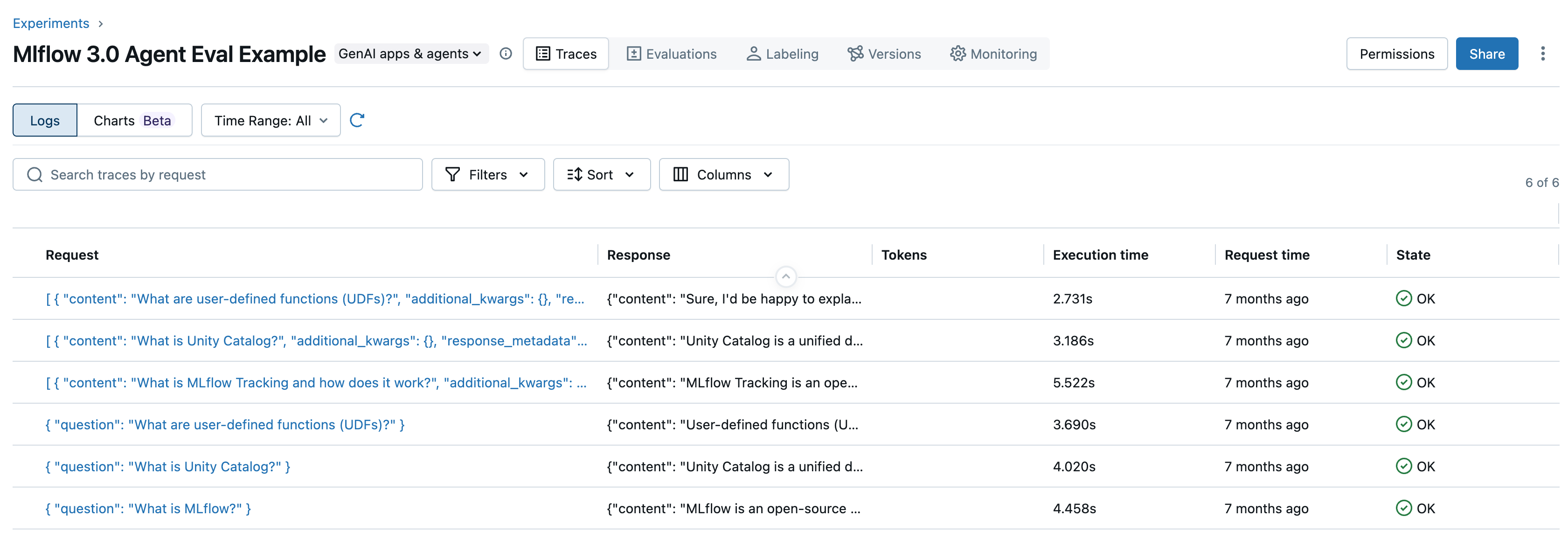
These capabilities simplify and streamline evaluation, deployment, debugging, and monitoring for all of your AI initiatives.
MLflow 3 also introduces the concepts of Logged Models and Deployment Jobs.
- Logged Models help you track a model's progress throughout its lifecycle. When you log a model using
log_model(), aLoggedModelis created that persists throughout the model's lifecycle, across different environments and runs, and contains links to artifacts such as metadata, metrics, parameters, and the code used to generate the model. You can use the Logged Model to compare models against each other, find the most performant model, and track down information during debugging. - Deployment jobs can be used to manage the model lifecycle, including steps like evaluation, approval, and deployment. These model workflows are governed by Unity Catalog, and all events are saved to an activity log that is available on the model version page in Unity Catalog.
See the following articles to install and get started using MLflow 3.
- Get started with MLflow 3 for models.
- Track and compare models using MLflow Logged Models.
- Model Registry improvements with MLflow 3.
- MLflow 3 deployment jobs.
Databricks-managed MLflow
Databricks provides a fully managed and hosted version of MLflow, building on the open source experience to make it more robust and scalable for enterprise use.
Agents and LLM applications
MLflow on Databricks provides a complete platform for developing, evaluating, and monitoring agents and LLM applications.
- Observability: MLflow Tracing records the inputs, outputs, and metadata associated with each intermediate step of a request, letting you quickly find the source of unexpected behavior in agents.
- Evaluation: Use Agent Evaluation to measure and improve agent quality, powered by MLflow evaluation.
- Prompt management: Version, manage, and iterate on prompt templates used across your AI applications.
- Agent development: Use Custom Agents to create agents, which rely on MLflow to track agent code, performance metrics, and traces.
- Interactive debugging: Use Genie Code for agent observability and evaluation for natural language access to traces, evaluation runs, scorers, and more within your MLflow experiment.
ML model development
MLflow on Databricks provides experiment tracking, model evaluation, a production model registry, and model deployment tools for ML model development.
The following diagram shows how Databricks integrates with MLflow to train and deploy machine learning models.
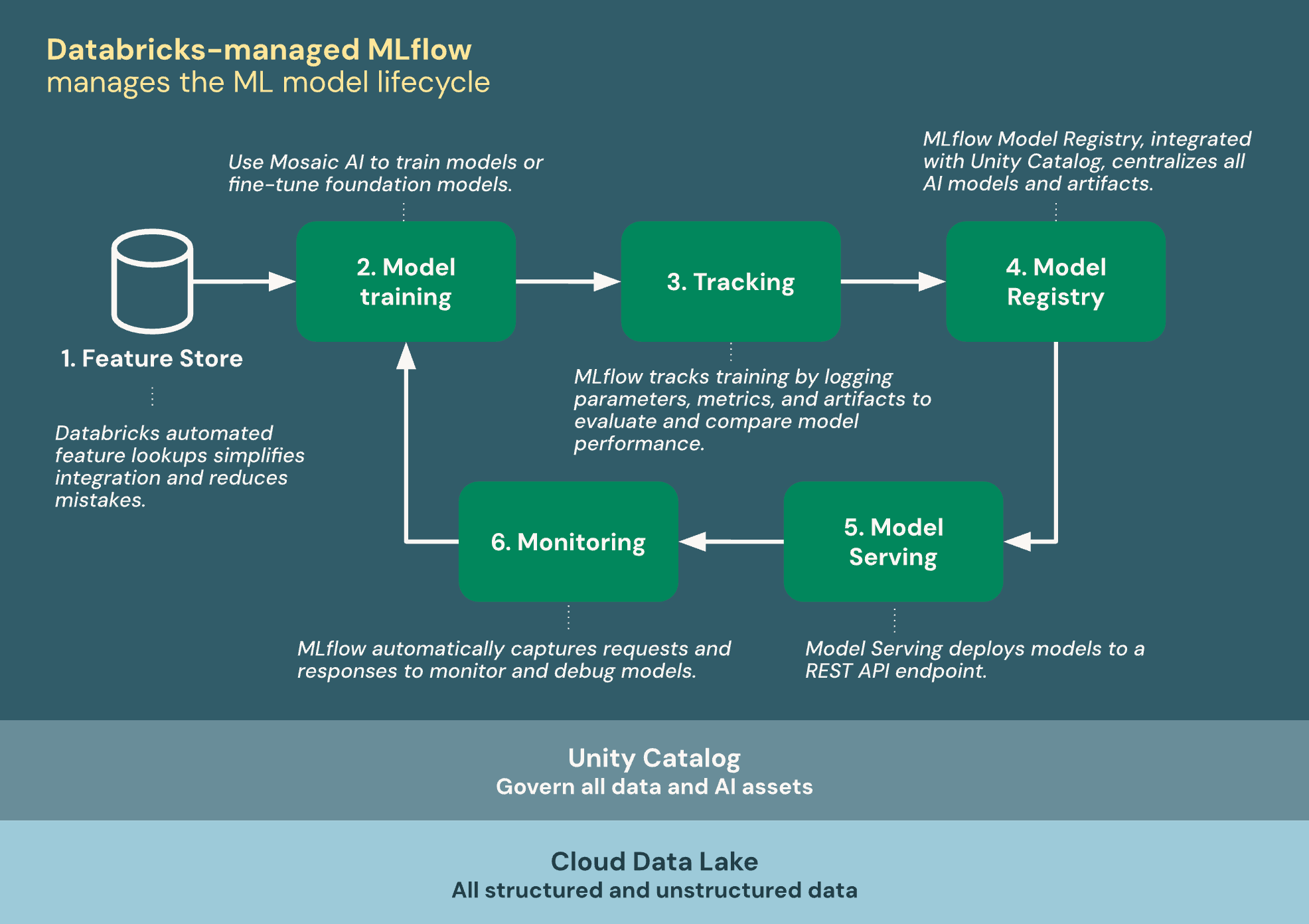
Databricks-managed MLflow is built on Unity Catalog and the Cloud Data Lake to unify all your data and AI assets in the ML lifecycle:
- Feature Store: Databricks automated feature lookups simplifies integration and reduces mistakes.
- Train models: Use Databricks AI features to train models or fine-tune foundation models.
- Tracking: MLflow tracks training by logging parameters, metrics, and artifacts to evaluate and compare model performance.
- Model Registry: MLflow Model Registry, integrated with Unity Catalog centralizes AI models and artifacts.
- Model Serving: Model Serving deploys models to a REST API endpoint.
- Monitoring: Model Serving automatically captures requests and responses to monitor and debug models. MLflow augments this data with trace data for each request.
Model training
MLflow Models are at the core of AI and ML development on Databricks. MLflow Models are a standardized format for packaging machine learning models and generative AI agents. The standardized format ensures that models and agents can be used by downstream tools and workflows on Databricks.
- MLflow documentation - Models.
Databricks provides features to help you train different kinds of ML models.
Experiment tracking
Databricks uses MLflow experiments as organizational units to track your work while developing models.
Experiment tracking lets you log and manage parameters, metrics, artifacts, and code versions during machine learning training and agent development. Organizing logs into experiments and runs allows you to compare models, analyze performance, and iterate more easily.
- Experiment tracking using Databricks.
- See MLflow documentation for general information on runs and experiment tracking.
Model Registry with Unity Catalog
MLflow Model Registry is a centralized model repository, UI, and set of APIs for managing the model deployment process.
Databricks integrates Model Registry with Unity Catalog to provide centralized governance for models. Unity Catalog integration allows you to access models across workspaces, track model lineage, and discover models for reuse.
- Manage models using Databricks Unity Catalog.
- See MLflow documentation for general information on Model Registry.
Model Serving
Databricks Model Serving is tightly integrated with MLflow Model Registry and provides a unified, scalable interface for deploying, governing, and querying AI models. Each model you serve is available as a REST API that you can integrate into web or client applications.
While they are distinct components, Model Serving heavily relies on MLflow Model Registry to handle model versioning, dependency management, validation, and governance.
Open source vs. Databricks-managed MLflow features
For general MLflow concepts, APIs, and features shared between open source and Databricks-managed versions, refer to MLflow documentation. For features exclusive to Databricks-managed MLflow, see Databricks documentation.
The following table highlights the key differences between open source MLflow and Databricks-managed MLflow and provides documentation links to help you learn more:
Feature | Availability on open source MLflow | Availability on Databricks-managed MLflow |
|---|---|---|
Security | User must provide their own security governance layer | |
Disaster recovery | Unavailable | |
Experiment tracking | MLflow Tracking API integrated with Databricks advanced experiment tracking | |
Model Registry | MLflow Model Registry integrated with Databricks Unity Catalog | |
Unity Catalog integration | Open source integration with Unity Catalog | |
Model deployment | User-configured integrations with external serving solutions (SageMaker, Kubernetes, container services, and so on) | Databricks Model Serving and external serving solutions |
AI agents | MLflow LLM development integrated with Custom Agents and Agent Evaluation | |
Encryption | Unavailable | Encryption using customer-managed keys |
Open source telemetry collection was introduced in MLflow 3.2.0, and is disabled on Databricks by default. For more details, refer to the MLflow usage tracking documentation.