Get started with MLflow 3 for models
This article focuses on MLflow 3 features for traditional machine learning and deep learning models. MLflow 3 also offers comprehensive features for GenAI application development including tracing, evaluation, and human feedback collection. See MLflow 3 for GenAI for details.
This article gets you started with MLflow 3 for developing machine learning models. It describes how to install MLflow 3 for models and includes several demo notebooks to get started. It also includes links to pages that cover the new features of MLflow 3 for models in more detail.
What is MLflow 3 for models?
MLflow 3 for models on Databricks delivers state-of-the-art experiment tracking, performance evaluation, and production management for machine learning models. MLflow 3 introduces significant new capabilities while preserving core tracking concepts, making migration from MLflow 2.x quick and simple.
What is MLflow 3 for GenAI?
Beyond MLflow 3 for Models, MLflow 3 for GenAI introduces a wide variety of new features and improvements for agent and GenAI application development. For a comprehensive overview, see MLflow 3 for GenAI.
Core features in MLflow 3 for GenAI include:
- Tracing and observability - End-to-end observability for GenAI applications with automatic instrumentation for 20+ frameworks including OpenAI, LangChain, LlamaIndex, and Anthropic
- Evaluation and monitoring - Comprehensive GenAI evaluation capabilities to measure and improve quality from development through production. Includes built-in LLM judges, customizable judges, evaluation dataset management, and real-time monitoring.
- Human feedback collection - Customizable Review UI for collecting domain expert feedback and interactively testing agents, with structured labeling sessions for organizing and tracking review progress
- Prompt Registry - Centralized prompt versioning, management, and A/B testing with Unity Catalog integration
How is MLflow 3 for models different from MLflow 2
MLflow 3 for models on Databricks enables you to:
- Centrally track and analyze the performance of your models across all environments, from interactive queries in a development notebook through production batch or real-time serving deployments.
![]()
- View and access model metrics and parameters from the model version page in Unity Catalog and from the REST API, across all workspaces and experiments.
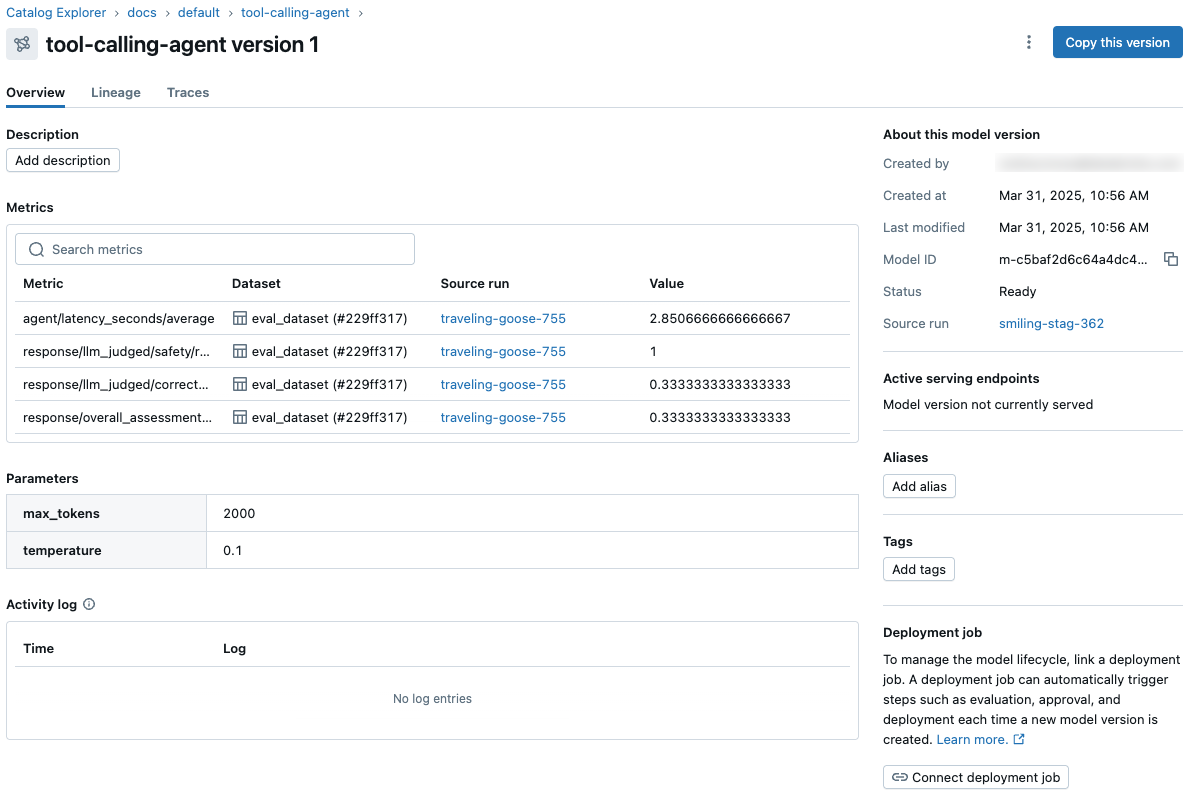
- Orchestrate evaluation and deployment workflows using Unity Catalog and access comprehensive status logs for each version of your model.
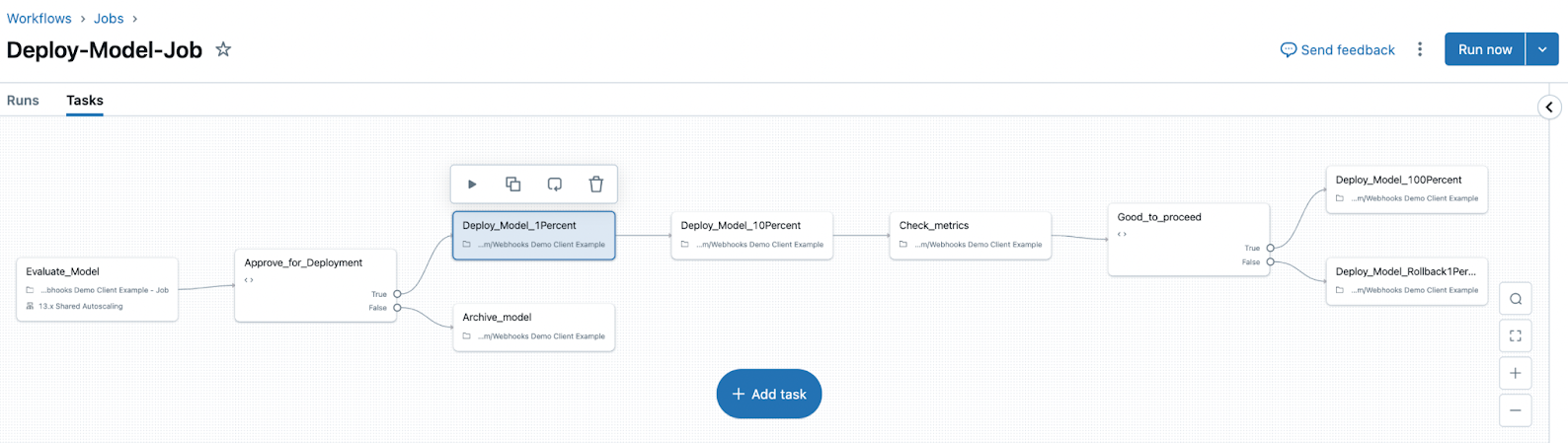
These capabilities simplify and streamline machine learning model development, evaluation, and production deployment.
Logged Models
Much of the new functionality of MLflow 3 derives from the new concept of a LoggedModel. For deep learning and traditional machine learning models, LoggedModels elevates the concept of a model produced by a training run, establishing it as a dedicated object to track the model lifecycle across different training and evaluation runs.
LoggedModels capture metrics, parameters, and traces across phases of development (training and evaluation) and across environments (development, staging, and production). When a LoggedModel is promoted to Unity Catalog as a Model Version, all performance data from the original LoggedModel becomes visible on the UC Model Version page, providing visibility across all workspaces and experiments. For more details, see Track and compare models using MLflow Logged Models.
Deployment jobs
MLflow 3 also introduces the concept of a deployment job. Deployment jobs use Lakeflow Jobs to manage the model lifecycle, including steps like evaluation, approval, and deployment. These model workflows are governed by Unity Catalog, and all events are saved to an activity log that is available on the model version page in Unity Catalog.
Migrating from MLflow 2.x
Although there are many new features in MLflow 3, the core concepts of experiments and runs, along with their metadata such as parameters, tags, and metrics, all remain the same. Migration from MLflow 2.x to 3.0 is very straightforward and should require minimal code changes in most cases. This section highlights some key differences from MLflow 2.x and what you should be aware of for a seamless transition.
Logging Models
When logging models in 2.x, the artifact_path parameter is used.
with mlflow.start_run():
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=python_model,
...
)
In MLflow 3, use name instead, which allows the model to later be searched by name. The artifact_path parameter is still supported but has been deprecated. Additionally, MLflow no longer requires a run to be active when logging a model, because models have become first-class citizens in MLflow 3. You can directly log a model without first starting a run.
mlflow.pyfunc.log_model(
name="model",
python_model=python_model,
...
)
Model artifacts
In MLflow 2.x, model artifacts are stored as run artifacts under the run's artifact path. In MLflow 3, model artifacts are now stored in a different location, under the model's artifact path instead.
# MLflow 2.x
experiments/
└── <experiment_id>/
└── <run_id>/
└── artifacts/
└── ... # model artifacts are stored here
# MLflow 3
experiments/
└── <experiment_id>/
└── models/
└── <model_id>/
└── artifacts/
└── ... # model artifacts are stored here
It is recommended to load models with mlflow.<model-flavor>.load_model using the model URI returned by mlflow.<model-flavor>.log_model to avoid any issues. This model URI is of the format models:/<model_id> (rather than runs:/<run_id>/<artifact_path> as in MLflow 2.x) and can also be constructed manually if only the model ID is available.
Model registry
In MLflow 3, the default registry URI is now databricks-uc, meaning the MLflow Model Registry in Unity Catalog will be used (see Manage model lifecycle in Unity Catalog for more details). The names of models registered in Unity Catalog are of the form <catalog>.<schema>.<model>. When calling APIs that require a registered model name, such as mlflow.register_model, this full, three-level name is used.
For workspaces that have Unity Catalog enabled and whose default catalog is in Unity Catalog, you can also use <model> as the name and the default catalog and schema will be inferred (no change in behavior from MLflow 2.x). If your workspace has Unity Catalog enabled but its default catalog is not configured to be in Unity Catalog, you will need to specify the full three-level name.
Databricks recommends using the MLflow Model Registry in Unity Catalog for managing the lifecycle of your models.
If you want to continue using the Workspace Model Registry (legacy), use one of the following methods to set the registry URI to databricks:
- Use
mlflow.set_registry_uri("databricks"). - Set the environment variable MLFLOW_REGISTRY_URI.
- To set the environment variable for registry URI at scale, you can use init scripts. This requires all-purpose compute.
Other important changes
- MLflow 3 clients can load all runs, models, and traces logged with MLflow 2.x clients. However, the reverse is not necessarily true, so models and traces logged with MLflow 3 clients may not be able to be loaded with older 2.x client versions.
- The
mlflow.evaluateAPI has been deprecated. For traditional ML or deep learning models, usemlflow.models.evaluatewhich maintains full compatibility with the originalmlflow.evaluateAPI. For LLMs or GenAI applications, use themlflow.genai.evaluateAPI instead. - The
run_uuidattribute has been removed from theRunInfoobject. Userun_idinstead in your code.
Install MLflow 3
To use MLflow 3, you must update the package to use the correct (>= 3.0) version. The following lines of code must be executed each time a notebook is run:
%pip install mlflow>=3.0 --upgrade
dbutils.library.restartPython()
Example notebooks
The following pages illustrate the MLflow 3 model tracking workflow for traditional ML and deep learning. Each page includes an example notebook.
Limitation
While Spark model logging (mlflow.spark.log_model) continues to work in MLflow 3, it does not use the new LoggedModel concept. Models logged using Spark model logging continue to use MLflow 2.x runs and run artifacts.
Additional resources
To learn more about the new features of MLflow 3, see the following articles: