Delta Lake テーブルのストリーミングの読み取りと書き込み
このページでは、readStream および writeStream を使用して、Spark 構造化ストリーミング のソースおよびシンクとして Delta Lake テーブルを使用する方法について説明します。Delta Lakeは、ストリーミングシステムやファイルに共通するパフォーマンスと信頼性の問題を解決します。メリットは次のとおりです。
- 低遅延取り込みによって生成された小さなファイルを統合し、パフォーマンスを向上させます。
- 複数のストリーム (または並列バッチ ジョブ) で「1 回だけ」の処理を維持します。
- ファイルをストリームソースとして使用する際に、新しいファイルを効率的に検出します。
Databricks SQLでストリーミング テーブルを使用してデータを読み込む方法については、 「スタンドアロン ストリーミング テーブルの使用」を参照してください。
Delta Lakeを使用したストリーム静的結合については、 「ストリーム静的結合」を参照してください。
Delta Lake のDataStreamReaderおよびDataStreamWriterオプションの完全なリストについては、 DataStreamReader Delta Lake オプションとDataStreamWriter Delta Lake オプションを参照してください。
Delta Lake テーブルをストリーミング ソースとして使用する場合、ストリーミング クエリはソース テーブルの保持期間内に少なくとも1回実行する必要があります。デフォルトの保持期間は、VACUUMで削除されたデータファイルでは7日間、トランザクションログ (logRetentionDuration) では30日間です。クエリがこれらのウィンドウの処理に間に合わない場合、DELTA_FILE_NOT_FOUND_DETAILED というエラーで失敗し、フル更新でリセットする必要があります。
回避策としてspark.sql.files.ignoreMissingFiles trueに設定し ないで ください。この設定では、警告なしに誤った結果が生成されます。ストリームのスケジュールがデフォルトの保持期間に追いつけない場合は、代わりにソーステーブルの保持期間を長くしてください。
Delta Lake テーブルをシンクとして使用
構造化ストリーミングを使用して Delta Lake テーブルにデータを書き込むことができます。テーブルに対して他のストリームやバッチクエリーが同時に実行されている場合でも、Delta Lake のトランザクションログにより、1 回のみの処理が保証されます。
構造化ストリーミングシンクを使用してDelta Lakeテーブルに書き込むと、epochId = -1で空のコミットが表示される可能性があります。これらは想定され、通常発生します:
- ストリーミング クエリの各実行の最初のバッチで (これは、
Trigger.AvailableNowのすべてのバッチで発生します)。 - スキーマが変更されたとき (列の追加など)。
これらの空のコミットは意図的なものであり、エラーを示すものではありません。これらはクエリの正確性やパフォーマンスに重大な影響を与えるものではありません。
Delta Lake VACUUM 関数は、Delta Lake によって管理されていないすべてのファイルを削除しますが、_で始まるディレクトリはスキップします。<table-name>/_checkpointsなどのディレクトリ構造を使用すると、Delta Lake テーブルの他のデータやメタデータと一緒にチェックポイントを安全に保存できます。
メトリクスを使用してバックログを監視する
ストリーミング クエリ プロセスのバックログを監視するには、次のメトリクスを使用します。
numBytesOutstanding: バックログ内でまだ処理されていないバイト数。numFilesOutstanding: バックログに残っている未処理ファイルの数。numNewListedFilesこのバッチのバックログを計算するためにリストされた Delta Lake ファイルの数。backlogEndOffset: バックログの計算に使用される Delta Lake テーブルバージョン。
ノートブックでは、ストリーミング クエリ進行状況ダッシュボードの 生 データタブでこれらのメトリクスを表示します。
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
追加モード
デフォルトでは、ストリームは追記モードで実行され、新しいレコードのみをテーブルに追加します。
テーブルへのストリーミング時には、 toTableメソッドを使用してください。
- Python
- Scala
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
コンプリートモード
構造化ストリーミングを完全モードで使用して、バッチ処理ごとにテーブル全体を置き換えます。例えば、顧客ごとのイベントの集計サマリーテーブルを継続的に更新することができます。
- Python
- Scala
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
厳密なレイテンシー要件のないアプリケーションでは、 AvailableNowのようなワンタイムトリガーを使用してコンピューティングリソースとコストを節約できます。例えば、このトリガーを使用すると、指定されたスケジュールに従って集計テーブルを更新し、前回の更新以降に到着した新しいデータのみを処理することができます。AvailableNow : インクリメンタルバッチ処理を参照してください。
ソース Delta Lake テーブルの変更を処理する
構造化ストリーミングは Delta Lake テーブルをインクリメンタルに読み取ります。Delta Lake テーブルからストリーミング クエリが読み取ると、新しいテーブル バージョンがソース テーブルにコミットされる際に、新しいレコードがべき等に処理されます。構造化ストリーミングは追加入力のみを受け入れ、ソースDelta Lakeテーブルに何らかの変更が発生すると例外をスローします。例えば、ストリーミング クエリによって読み取られるソース Delta Lake テーブルを、UPDATE、DELETE、MERGE INTO、またはOVERWRITEの操作が変更した場合、ストリームはエラーで失敗します。
ユースケースに応じて、ソースのDelta Lakeテーブルに対するアップストリームの変更を処理するための4つの一般的なアプローチがあります。以下に、リファレンステーブルとそれぞれの詳細を示します。
アプローチ | 長所 | 短所 |
|---|---|---|
| シンプルで、複雑なロジックを書く必要はありません。アップストリームの変更が個別に処理される追加のみの処理や、不良レコードを一時的に処理する場合に役立ちます。 | 変更は伝播せず、追加のみを処理します。 |
フルリフレッシュ | またシンプルで、複雑なロジックを書く必要もありません。アップストリームの変更がほとんどない小規模なデータセットに役立ちます。 | 大規模なデータセットにはコストがかかる。下流のすべてのテーブルを再処理する必要があります。 |
チェンジデータフィード | すべての変更タイプ(挿入、更新、および削除)を処理します。Databricks では、可能な限り、テーブルから直接ストリーミングするよりも、Delta Lake テーブルの CDC フィードからストリーミングすることをお勧めします。 | 各変更タイプを処理するには、より複雑なロジックを記述する必要があります。 |
マテリアライズドビュー | 変更の自動伝播機能を備えた、構造化ストリーミングのシンプルな代替手段。 | レイテンシーが高くなります。LakeFlow Pipelines と Databricks SQL でのみ利用可能です。 |
アップストリームの変更コミットをスキップします skipChangeCommits
既存のレコードを削除または変更するトランザクションを無視し、追加のみを処理するには、 skipChangeCommitsを設定します。これは、既存データへの変更をストリームを通じて伝播させる必要がない場合、または変更を処理するための別のロジックを優先する場合に役立ちます。一時的な変更を一時的に無視する必要がある場合は、 skipChangeCommitsをオン/オフできます。
Databricks 、変更データフィードを使用しないほとんどのワークロードにskipChangeCommitsを使用することを推奨します。
- Python
- Scala
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Delta Lakeテーブルのスキーマが、そのテーブルに対してストリーミング読み取りを開始した後に変更された場合、クエリは失敗します。ほとんどのスキーマの変更では、ストリームを再起動してスキーマの不一致を解決することで、処理を続行することができます。
Databricks Runtime 12.2 LTS以前のバージョンは、列の名前変更や削除など非追加的なスキーマ進化が行われた列マッピングが有効になっているDelta Lakeテーブルからのストリーミングに対応していません。詳細については、列マッピングとストリーミングを参照してください。
Databricks Runtime 12.2 LTS以降では、 skipChangeCommits ignoreChangesに置き換わります。Databricks Runtime 11.3 LTS以前のバージョンでは、 ignoreChangesのみがサポートされています。詳細については、レガシーオプション: ignoreChangesを参照してください。
従来オプション: ignoreDeletes
ignoreDeletes パーティション境界でデータを削除するトランザクション (つまり、完全なパーティションの削除) のみを処理するレガシー オプションです。パーティション以外の削除、更新、またはその他の変更を処理する必要がある場合は、代わりにskipChangeCommits使用します。
- Python
- Scala
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
従来オプション: ignoreChanges
ignoreChanges Databricks Runtime 11.3 LTS以前のバージョンで利用可能です。Databricks Runtime 12.2 LTS以降では、 skipChangeCommitsに置き換えられます。
ignoreChangesが有効になっている場合、ソース テーブル内の書き換えられたデータ ファイルは、 UPDATE 、 MERGE INTO 、 DELETE (パーティション内)、またはOVERWRITEなどのデータ変更操作の後に再送信されます。変更されていない行は新しい行と同時に出力されることが多いため、下流のコンシューマーは重複を処理できる必要がある。削除操作は下流には伝播されません。ignoreChanges ignoreDeletesよりも優先されます。
それに対し、 skipChangeCommitsファイル変更操作を完全に無視します。UPDATE 、 MERGE INTO 、 DELETE 、 OVERWRITEなどのデータ変更操作によりソーステーブルで書き換えられたデータファイルは完全に無視されます。ストリームソーステーブルの変更を反映させるには、これらの変更を伝播させるための別のロジックを実装する必要があります。
Databricksは、すべての新規ワークロードにskipChangeCommits使用することを推奨しています。ワークロードをignoreChangesからskipChangeCommitsに移行するには、ストリーミングロジックをリファクタリングしてください。
ダウンストリームテーブルの完全更新
アップストリームの変更がまれで、データが再処理できるほど小さい場合は、ストリーミング チェックポイントと出力テーブルを削除して、ストリームを最初から再開できます。これにより、ストリームはソース テーブルのすべてのデータを再処理します。このアプローチでは、このストリームの出力に依存するすべてのダウンストリーム テーブルの再処理も必要になることに注意してください。
このアプローチは、アップストリームの変更がまれで、完全な更新のコストが許容できる小規模なデータセットまたはワークロードに最適です。
チェンジデータフィードを使う
あらゆる種類の変更(挿入、更新、削除)を処理するワークロードでは、Delta Lake チェンジデータフィードを使用します。チェンジデータフィードは、Delta Lakeテーブルへの行レベルの変更を記録し、それらの変更をストリームして、ダウンストリームテーブルで各変更タイプを処理するロジックを記述できるようにします。これは、コードがあらゆる種類の変更イベントを明示的に処理するため、最も堅牢なアプローチです。Databricksでのチェンジデータフィードの使用 を参照してください。
LakeFlow Pipelinesを使用している場合は、「AUTO CDC APIs: パイプラインによるチェンジデータキャプチャの簡素化」を参照してください。
Databricks Runtime 12.2 LTS以前のバージョンでは、列の名前変更や削除など非追加的なスキーマ進化が行われた列マッピングが有効になっているDelta Lakeテーブルの場合、そのチェンジデータフィードからのストリーミングに対応していません。列マッピングとストリーミングを参照してください。
マテリアライズドビューを使用する
ソースデータが変更されると、マテリアライズドビューは結果を再計算することで上流の変更を自動的に処理します。可能な限り低いレイテンシが必要なく、ストリーミングの複雑さの管理を回避したい場合は、マテリアライズドビューでアーキテクチャを簡素化できます。マテリアライズドビューは、LakeFlow Pipelinesとスタンドアロンパイプラインで利用できます。See マテリアライズドビュー.
例
たとえば、dateによってパーティション化された、date、user_email、およびaction列を含むテーブルuser_eventsがあるとします。user_eventsテーブルからストリーミングしており、GDPRのためテーブルからデータを削除する必要があります。
skipChangeCommits 複数のパーティション内のデータを削除できます (この例では、 user_emailでフィルタリングします)。次の構文を使用します。
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
UPDATE ステートメントでuser_emailを更新すると、問題のuser_emailを含むファイルが書き換えられます。skipChangeCommits を使用して、変更されたデータ ファイルを無視します。
Databricks では、削除によって常にパーティションが完全に削除されることが確実でない限り、 ignoreDeletesではなくskipChangeCommits使用することをお勧めします。
冪等テーブル書き込みにはforeachBatch使用してください
Databricks では、 foreachBatchを使用する代わりに、更新したいシンクごとに個別のストリーミング書き込みを構成することを推奨しています。foreachBatchの複数のシンクへの書き込みは、 foreachBatchで複数のテーブルへの書き込みがシリアル化されるため、並列化を低下させ、全体的なレイテンシを増加させます。
Delta Lake テーブルは、foreachBatch 内の複数のテーブルへの書き込みをべき等にするために、以下の DataFrameWriter オプションをサポートしています。
txnAppId各DataFrame書き込み時に渡すことができる一意の要素。 例えば、StreamingQuery ID をtxnAppIdとして使用できます。txnAppIdユーザーが生成した任意の固有の文字列にすることができ、ストリーム ID に関連している必要はありません。txnVersion: トランザクションのバージョンとして機能する単調増加の数値。
Delta Lake はtxnAppIdとtxnVersionを使用して重複書き込みを識別し、無視します。例えば、バッチ書き込みがエラーで中断された後、同じtxnAppIdとtxnVersionを使用してバッチを再実行することで、重複を正しく識別して無視することができます。任意のデータシンクに書き込むには、foreachBatch の使用を参照してください。
ストリーミング・チェックポイントを削除し、新しいチェックポイントでクエリを再開する場合は、別の txnAppIdを指定する必要があります。 新しいチェックポイントは、バッチ ID 0で開始されます。 Delta Lake は、バッチ ID とtxnAppIdを一意のキーとして使用し、既に表示されている値を持つバッチをスキップします。
次のコード例は、このパターンを示しています。
- Python
- Scala
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
を使用してストリーミング クエリからアップサートします foreachBatch
merge と foreachBatch を組み合わせて使用することで、ストリーミングクエリーから Delta Lake テーブルに複雑なアップサートを書き込むことができます。「foreachBatch を使用して任意のデータ シンクに書き込む」をご参照ください。
このアプローチには多くの応用例がある。
update出力モードでは書き込みパフォーマンスが向上しますが、complete出力モードではマイクロバッチごとに結果テーブル全体を書き直す必要があります。foreachBatchでマージクエリを使用して変更データを書き込むことにより、Delta Lake テーブルに変更のストリームを継続的に適用します。Delta Lakeを使用した緩やかに変化するデータ (SCD) とチェンジデータキャプチャ (CDC) を参照してください。- ストリーム処理中に重複排除を処理します。挿入専用マージクエリを
foreachBatchで使用することで、自動的に重複排除しながら、Delta Lake テーブルにデータを継続的に書き込むことができます。Delta Lakeテーブルへの書き込み時のデータ重複排除を参照してください。
-
foreachBatch内のmergeステートメントが冪等であることを確認してください。そうしないと、ストリーミングクエリを再起動すると、同じデータバッチに対して操作が複数回適用される可能性があります。冪等なテーブル書き込みについては、foreachBatch使用を参照してください。 -
mergeforeachBatchで使用される場合、入力データ レート メトリクスは、ソースでデータが生成される実際のレートの倍数を返す可能性があります。merge入力データを複数回読み込むため、メトリクスが乗算されます。メトリクスの乗算を防ぐには、merge前にバッチDataFrameをキャッシュし、mergeの後にキャッシュを解除します。入力データレートは
StreamingQueryProgressおよびノートブックのストリーミングレートグラフで確認できます。Databricksのモニタリング構造化ストリーミング クエリ」を参照してください。
例えば、 foreachBatch内でMERGE SQL ステートメントを使用できます。
- Scala
- Python
// Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta Lake table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
# Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta Lake table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Delta Lake APIsストリーミング更新/挿入に使用することもできます。
- Scala
- Python
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta Lake table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta Lake table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
変更を処理するために初期テーブルバージョンを設定します
デフォルトで、ストリームは最新の利用可能なDelta Lakeテーブルバージョンで始まります。これには、その時点でのテーブルの完全なスナップショットと、すべての今後の変更が含まれています。Databricks では、ほとんどのワークロードにデフォルトの初期テーブルバージョンを使用することを推奨しています。
必要に応じて、次のオプションを使用して、テーブル全体を処理せずにDelta Lakeストリーミング ソースの開始点を指定できます。
-
startingVersion:読み取りを開始するDelta Lakeテーブルバージョン。指定されたバージョン以降にコミットされたすべてのテーブル変更は、ストリームによって読み取られます。指定されたバージョンが存在しない場合、ストリームを開始できません。利用可能なコミットバージョンを見つけるには、
DESCRIBE HISTORYを実行し、versionを確認します。最新の変更のみを返すには、latestを指定します。Delta Lake テーブルのバージョンに関する情報については、テーブル履歴の操作を参照してください。 -
startingTimestamp: 読み取りを開始するタイムスタンプ。指定されたタイムスタンプ以降にコミットされたすべてのテーブル変更は、ストリームによって読み取られます。指定されたタイムスタンプがすべてのテーブルコミットよりも前である場合、ストリーミング読み取りは利用可能な最も古いタイムスタンプから開始されます。次のいずれかを設定してください。- タイムスタンプ文字列。たとえば、
"2019-01-01T00:00:00.000Z"などです。 - 日付文字列。たとえば、
"2019-01-01"などです。
- タイムスタンプ文字列。たとえば、
startingVersionとstartingTimestampを同時に設定することはできません。これらの設定は、新規のストリーミングクエリにのみ適用されます。ストリーミングクエリが開始され、その進行状況がチェックポイントに記録されている場合、これらの設定は無視されます。
指定されたバージョン、またはタイムスタンプからストリーミングソースを開始できますが、ストリーミングソースのスキーマは常にDelta Lakeテーブルの最新のスキーマになります。指定されたバージョンまたはタイムスタンプ以降に、Delta Lakeテーブルに互換性のないスキーマ変更がないことを確認する必要があります。そうしないと、ストリーミングソースが不正なスキーマでデータを読み取った際に、間違った結果を返す可能性があります。
例
たとえば、user_eventsというテーブルがあるとします。バージョン5以降の変更を読み取りたい場合は、次を使用します:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
2018年10月18日以降の変更を読み取りたい場合は、次を使用します。
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
初期スナップショットをデータ損失なしで処理する
この機能は、Databricks Runtime 11.3 LTS 以降で使用できます。
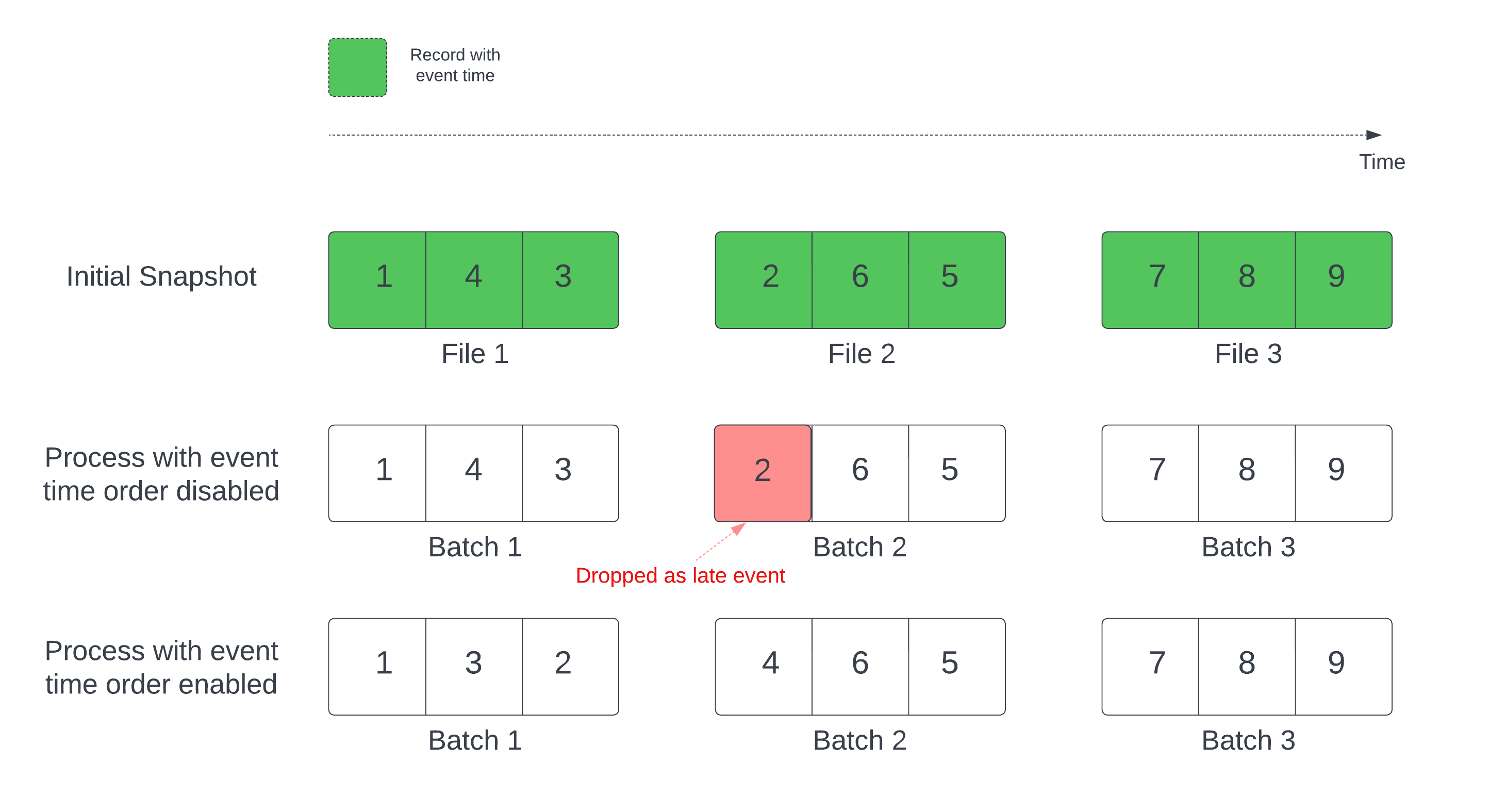
ウォーターマークが定義されたステートフルストリーミングクエリでは、ファイルの更新時刻に基づいてファイルを処理すると、レコードが誤った順序で処理される可能性があります。これにより、ウォーターマークがレコードを遅延イベントとして誤ってマークし、削除する可能性があります。 これは、最初のDeltaスナップショットが当然の順序で処理された場合にのみ発生します。
Deltaソーステーブルを使用するストリームでは、クエリはまずテーブルに存在するすべてのデータを処理し、 初期スナップショット と呼ばれるバージョンを作成します。デフォルトでは、Delta Lakeテーブルのデータファイルは、最後に更新されたファイルに基づいて処理されます。ただし、最終変更時刻は必ずしも記録イベントの時間順を表すわけではありません。
初期スナップショット処理中のデータ損失を回避するには、 withEventTimeOrderオプションを有効にしてください。withEventTimeOrder初期スナップショットデータのイベント時間範囲を時間バケットに分割します。各マイクロバッチは、時間範囲内のデータをフィルタリングすることでバケットを処理します。maxFilesPerTriggerとmaxBytesPerTriggerオプションはマイクロバッチサイズを制御するために依然として適用可能ですが、処理方法のため、おおよそのみ適用可能です。
以下の図はこのプロセスを示しています。
制約
- ストリームクエリが開始され、初期スナップショットがアクティブに処理されている場合、
withEventTimeOrder変更することはできません。withEventTimeOrderを変更して再開するには、チェックポイントを削除する必要があります。 withEventTimeOrderが有効になっている場合、初期スナップショット処理が完了するまで、この機能をサポートしていない Databricks Runtime バージョンにストリームをダウングレードすることはできません。ダウングレードするには、最初のスナップショットが完了するまで待つか、チェックポイントを削除してクエリを再起動してください。- 以下のシナリオでは、この機能はサポートされていません。
- イベント時間列はジェネレーテッドカラムであり、Delta ソースとウォーターマークの間に非投影変換がある場合。
- ストリームクエリーに複数の Delta ソースを持つウォーターマークがある場合。
パフォーマンス
withEventTimeOrderが有効になっている場合、初期スナップショット処理のパフォーマンスが低下する可能性があります。各マイクロバッチは、最初のスナップショットをスキャンして、対応するイベント時間範囲内のデータをフィルタリングします。フィルタリング性能を向上させるには:
- データスキップを適用できるように、イベント時間としてDeltaソース列を使用してください。 データスキップを参照してください。
- テーブルをイベント時間列に沿って分割します。
Spark UI使用して、特定のマイクロ に対してスキャンされたDeltaファイルの数を確認します。 。
例
event_time 列を持つ user_events というテーブルがあるとします。ストリーミングクエリーは集計クエリーです。初期スナップショット処理中にデータドロップが起きないようにするには、以下を使用します。
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
クラスター上の Spark 構成でwithEventTimeOrder設定すると、すべてのストリーミング クエリに適用されます: spark.databricks.delta.withEventTimeOrder.enabled true 。
処理性能を向上させるために、入力レートを制限する
デフォルトでは、構造化ストリーミングは各マイクロバッチで可能な限り多くのファイルを処理します。バッチ処理するデータ量を制限し、メモリ使用量を管理したり、レイテンシを安定させたり、クラウドストレージのコストを削減したりするには、次のオプションを使用してください。
maxFilesPerTrigger: 各マイクロバッチで処理される新規ファイルの数。デフォルト値は1000です。maxBytesPerTrigger各マイクロバッチで処理されるデータ量。このオプションは「ソフトマックス」を設定します。これは、バッチ処理で処理されるデータ量がおおよそこの量であり、最小入力単位がこの制限値よりも大きい場合は、ストリーミングクエリを先に進めるために、制限値を超えるデータを処理する可能性があることを意味します。これはデフォルトでは設定されていません。
maxBytesPerTriggerとmaxFilesPerTrigger両方を使用した場合、マイクロバッチはmaxFilesPerTriggerまたはmaxBytesPerTriggerいずれかの制限に達するまでデータを処理します。
デフォルトでは、 logRetentionDurationソーステーブルのトランザクションをクリーンアップし、ストリーミングクエリがそれらのバージョンを処理しようとすると、クエリはデータ損失を防ぐことができません。オプションfailOnDataLossをfalseに設定すると、失われたデータを無視して処理を続行できます。タイムトラベルクエリのデータ保持設定については、「タイムトラベルクエリのデータ保持設定」を参照してください。
クラウドストレージのコストを管理する
ストリーミングクエリには、 processingTime 、 availableNow 、 realTimeなど、コストとレイテンシのバランスを取ることができる複数のトリガーモードがあります。クラウドストレージのコスト管理については、「クラウドストレージのコスト管理」を参照してください。