Explorar e criar tabelas no DBFS
Essa documentação foi descontinuada e pode não estar atualizada. O produto, serviço ou tecnologia mencionados neste conteúdo não são mais suportados. Veja upload de arquivos para Databricks, Criar ou modificar uma tabela usando o arquivo upload e O que é o Catalog Explorer?
Acessar o upload de arquivos DBFS herdados e a interface de criação de tabelas por meio da interface de adição de dados. Clique em ![]() New > Data > DBFS .
New > Data > DBFS .
O senhor também pode acessar a UI do Notebook clicando em File (Arquivo) > Add data (Adicionar dados ).
A Databricks recomenda o uso do Catalog Explorer para uma experiência aprimorada de visualização de objetos de dados e gerenciamento de ACLs e a página Criar ou modificar tabela a partir de upload de arquivo para ingerir facilmente pequenos arquivos no Delta Lake.
A disponibilidade de alguns elementos descritos neste artigo varia de acordo com as configurações do site workspace. Entre em contato com o administrador do workspace ou com a equipe do Databricks account .
Importar dados
Se tiver pequenos arquivos de dados em sua máquina local que deseja analisar com o Databricks, o senhor pode importá-los para o DBFS usando a interface do usuário.
Os administradores do workspace podem desativar esse recurso. Para obter mais informações, consulte gerenciar dados upload.
Crie uma tabela
O senhor pode iniciar a interface de usuário de criação de tabela do DBFS clicando em ![]() New na barra lateral ou no botão DBFS na interface de usuário de adição de dados. O senhor pode preencher uma tabela a partir de arquivos no DBFS ou fazer upload de arquivos.
New na barra lateral ou no botão DBFS na interface de usuário de adição de dados. O senhor pode preencher uma tabela a partir de arquivos no DBFS ou fazer upload de arquivos.
Com a interface do usuário, você só pode criar tabelas externas.
-
Escolha uma fonte de dados e siga as etapas da seção correspondente para configurar a tabela.
Se o administrador do Databricks workspace tiver desativado a opção de upload de arquivo, o senhor não terá a opção de upload arquivos; poderá criar tabelas usando uma das outras fontes de dados.
Instruções para upload de arquivos
- Arraste os arquivos para a zona suspensa Arquivos ou clique na zona suspensa para navegar e escolher os arquivos. Após o upload, é exibido um caminho para cada arquivo. O caminho será algo como
/FileStore/tables/<filename>-<integer>.<file-type>. O senhor pode usar esse caminho em um Notebook para ler dados. - Clique em Criar tabela com interface do usuário .
- No menu suspenso de clustering, escolha um clustering.
Instruções para DBFS
- Selecione um arquivo.
- Clique em Criar tabela com interface do usuário .
- No menu suspenso de clustering, escolha um clustering.
- Arraste os arquivos para a zona suspensa Arquivos ou clique na zona suspensa para navegar e escolher os arquivos. Após o upload, é exibido um caminho para cada arquivo. O caminho será algo como
-
Clique em Preview Table (Visualizar tabela ) para view a tabela.
-
No campo Table Name (Nome da tabela ), substitua opcionalmente o nome da tabela default. Um nome de tabela pode conter apenas caracteres alfanuméricos minúsculos e sublinhados e deve começar com uma letra minúscula ou sublinhado.
-
No campo Criar no banco de dados , opcionalmente, substitua o banco de dados
defaultselecionado. -
No campo Tipo de arquivo , opcionalmente, substitua o tipo de arquivo inferido.
-
Se o tipo de arquivo for CSV:
- No campo Delimitador de coluna , selecione se deseja substituir o delimitador inferido.
- Indique se deseja usar a primeira linha como títulos das colunas.
- Indique se deseja inferir o esquema.
-
Se o tipo de arquivo for JSON, indique se o arquivo tem várias linhas.
-
Clique em Criar tabela .
visualizar bancos de dados e tabelas
com o Catalog Explorer ativado não têm acesso ao comportamento herdado descrito abaixo.
Clique em ![]() Catálogo na barra lateral. Databricks seleciona os clusters em execução aos quais o senhor tem acesso. A pasta Bancos de dados exibe a lista de bancos de dados com o banco de dados
Catálogo na barra lateral. Databricks seleciona os clusters em execução aos quais o senhor tem acesso. A pasta Bancos de dados exibe a lista de bancos de dados com o banco de dados default selecionado. A pasta Tables exibe a lista de tabelas no banco de dados default.
O senhor pode alterar o clustering no menu Databases (Bancos de dados), criar tabela UI ou view table UI. Por exemplo, no menu Bancos de dados:
-
Clique na seta
 para baixo na parte superior da pasta Bancos de dados.
para baixo na parte superior da pasta Bancos de dados. -
Selecione um clustering.
ver detalhes da tabela
Os detalhes da tabela view mostram o esquema da tabela e os dados de amostra.
-
Clique em
 Catálogo na barra lateral.
Catálogo na barra lateral. -
Na pasta Bancos de dados, clique em um banco de dados.
-
Na pasta Tabelas, clique no nome da tabela.
-
No menu suspenso de clustering, selecione opcionalmente outro clustering para renderizar a visualização da tabela.
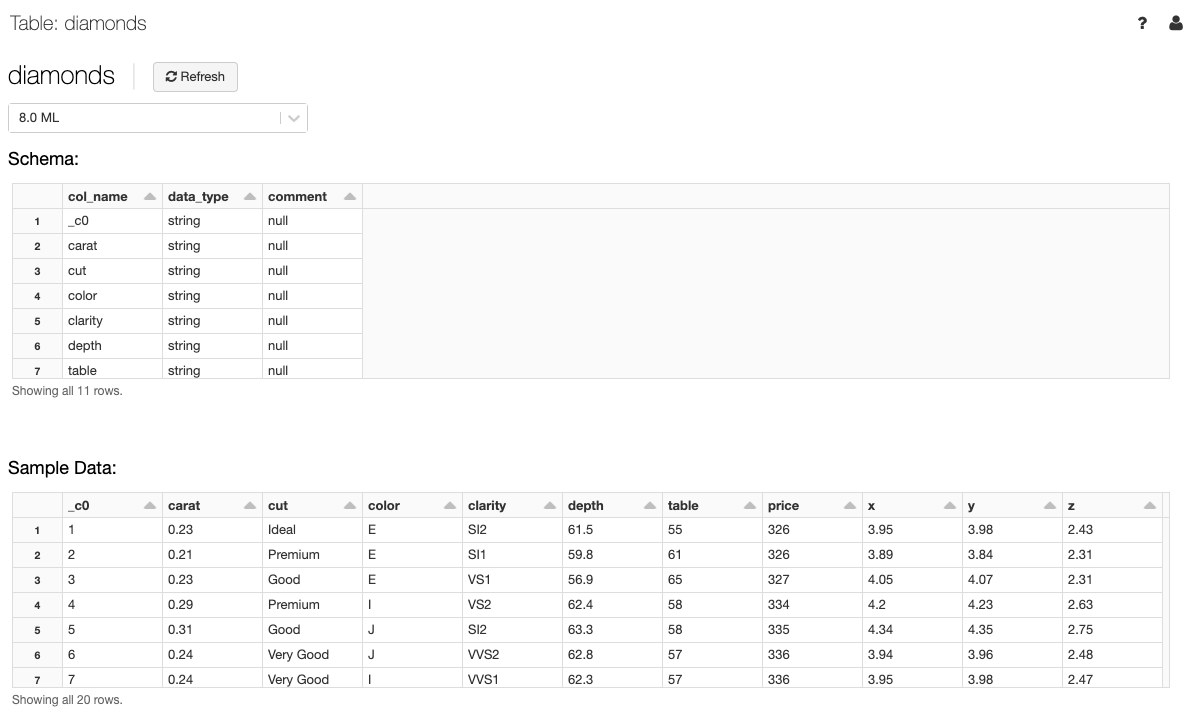
Para exibir a visualização da tabela, uma execução da consulta Spark SQL no clustering selecionado no menu suspenso de clustering . Se o clustering já tiver uma carga de trabalho em execução, a visualização da tabela poderá demorar mais para carregar.
Excluir uma tabela usando a interface
- Clique em Catálogo na barra lateral.
- Clique ao
 lado do nome da tabela e selecione Excluir .
lado do nome da tabela e selecione Excluir .