Configuração do pacote em Python
O suporte a Python para Pacotes de Automação Declarativa amplia os Pacotes de Automação Declarativa com recursos adicionais que se aplicam durante a implantação do pacote, permitindo que você:
-
Defina recurso em código Python . Essas definições podem coexistir com recursos definidos em YAML.
-
Criar recursos dinamicamente durante a implantação do pacote usando metadados. Consulte Criar recurso usando metadados.
-
Modifique o recurso definido em YAML ou Python durante a implantação do pacote. Consulte Modificar recurso definido em YAML ou Python.
Você também pode modificar o recurso do pacote em tempo de execução usando recursos como a condição `if/else condition_task` ou `for_each_task` para `Job`.
A documentação de referência para o suporte em Python do pacote databricks-bundles de Automação Declarativa está disponível em https://databricks.github.io/cli/python/.
Requisitos
Para usar o suporte do Python para Pacotes de Automação Declarativa, você deve primeiro:
-
Instale a CLIDatabricks, versão 0.275.0 ou superior. Consulte Instalar ou atualizar a CLI do Databricks.
-
Faça a autenticação em seu site Databricks workspace se ainda não tiver feito isso:
Bashdatabricks configure -
Instalar UV. Consulte a seção Instalação de UV. O Python para pacotes de automação declarativa usa o uv para criar um ambiente virtual e instalar as dependências necessárias. Alternativamente, você pode configurar seu ambiente Python usando outras ferramentas, como o venv.
Criar um projeto a partir do padrão
Para criar um novo projeto de suporte Python para Declarative Automation Bundles, inicialize um bundle usando o padrão pydabs :
databricks bundle init pydabs
Quando solicitado, dê um nome ao seu projeto, como my_pydabs_project, e aceite a inclusão de um pacote Notebook e Python.
Agora, crie um novo ambiente virtual na sua nova pasta do projeto:
cd my_pydabs_project
uv sync
Em default, o padrão inclui um exemplo de um trabalho definido como Python no arquivo resources/my_pydabs_project_job.py:
from databricks.bundles.jobs import Job
my_pydabs_project_job = Job.from_dict(
{
"name": "my_pydabs_project_job",
"tasks": [
{
"task_key": "notebook_task",
"notebook_task": {
"notebook_path": "src/notebook.ipynb",
},
},
],
},
)
A função Job.from_dict aceita um dicionário Python usando o mesmo formato que o YAML. O recurso também pode ser construído usando a sintaxe de classe de dados:
from databricks.bundles.jobs import Job, Task, NotebookTask
my_pydabs_project_job = Job(
name="my_pydabs_project_job",
tasks=[
Task(
task_key="notebook_task",
notebook_task=NotebookTask(
notebook_path="src/notebook.ipynb",
),
),
],
)
Os arquivos Python são carregados por meio de um ponto de entrada especificado na seção python em databricks.yml:
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
Por default, resources/__init__.py contém uma função que carrega todos os arquivos Python no recurso pacote.
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and is responsible for loading
bundle resources defined in Python code. This function is called by Databricks CLI during
bundle deployment. After deployment, this function is not used.
"""
# the default implementation loads all Python files in 'resources' directory
return load_resources_from_current_package_module()
implantado e executado Job ou pipeline
Para implantar o pacote no destino de desenvolvimento, use o comando bundle implantado na raiz do projeto do pacote:
databricks bundle deploy --target dev
Esse comando implantou tudo o que foi definido para o projeto do pacote. Por exemplo, um projeto criado usando o padrão default implantou um Job chamado [dev yourname] my_pydabs_project_job em seu workspace. O senhor pode encontrar esse trabalho navegando até Jobs & pipeline em seu Databricks workspace.
Depois que o pacote for implantado, o senhor pode usar o comando de resumo do pacote para revisar tudo o que foi implantado:
databricks bundle summary --target dev
Por fim, para executar um trabalho ou pipeline, use o comando bundle exec:
databricks bundle run my_pydabs_project_job
Atualizar pacotes existentes
Para atualizar pacotes existentes, modele a estrutura padrão do projeto conforme descrito em Criar um projeto a partir de um padrão. Os pacotes existentes com YAML podem ser atualizados para incluir recursos definidos como código Python adicionando uma seção python em databricks.yml:
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
O ambiente virtual especificado deve conter o pacote PyPi databricks-bundles instalado.
pip install databricks-bundles==0.275.0
A pasta de recursos deve conter o arquivo __init__.py:
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and
is responsible for loading bundle resources defined in Python code.
This function is called by Databricks CLI during bundle deployment.
After deployment, this function is not used.
"""
# default implementation loads all Python files in 'resources' folder
return load_resources_from_current_package_module()
Converter o trabalho existente em Python
Para converter um trabalho existente em Python, o senhor pode usar a visualização como recurso de código. Veja Visualizar trabalho como código.
-
Abra a página da tarefa existente no workspace Databricks .
-
Clique no
 kebab à esquerda do botão de execução , depois clique em visualizar como código :
kebab à esquerda do botão de execução , depois clique em visualizar como código :
-
Selecione Python e, em seguida, Pacotes de Automação Declarativa.
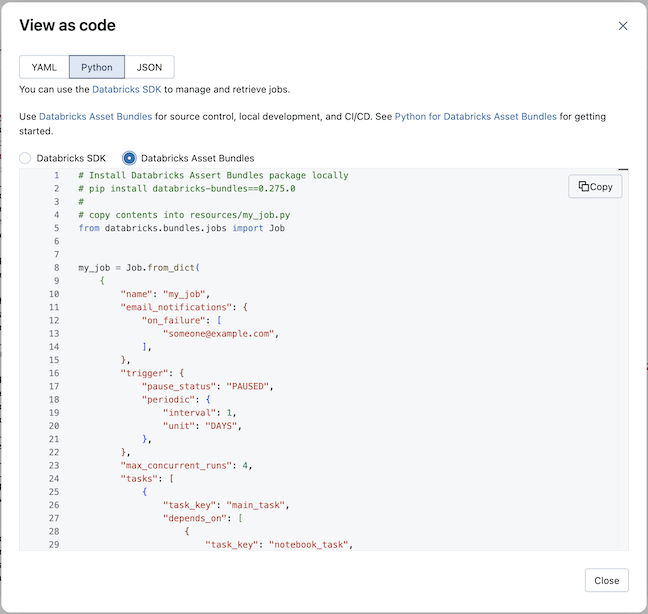
-
Clique em Copy (Copiar ) e salve o Python gerado como um arquivo Python na pasta recurso do projeto do pacote.
O senhor também pode view e copiar YAML para trabalhos e pipelines existentes que podem ser colados diretamente nos arquivos YAML de configuração do pacote.
Criar recurso usando metadados
A implementação default da função load_resources carrega os arquivos Python no pacote resources. O senhor pode usar o site Python para criar recursos de forma programática. Por exemplo, o senhor pode carregar arquivos de configuração e criar trabalhos em um loop:
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
from databricks.bundles.jobs import Job
def create_job(country: str):
my_notebook = {
"task_key": "my_notebook",
"notebook_task": {
"notebook_path": "files/my_notebook.py",
},
}
return Job.from_dict(
{
"name": f"my_job_{country}",
"tasks": [my_notebook],
}
)
def load_resources(bundle: Bundle) -> Resources:
resources = load_resources_from_current_package_module()
for country in ["US", "NL"]:
resources.add_resource(f"my_job_{country}", create_job(country))
return resources
Variáveis do pacote de acesso
A substituição de pacotes e as variáveis personalizadas permitem a recuperação dinâmica de valores, de modo que as configurações possam ser determinadas no momento da implantação e execução de um pacote em um destino. Para obter informações sobre variáveis de pacote configurável, consulte Variáveis personalizadas.
Em Python, defina variáveis e, em seguida, use o parâmetro bundle para acessá-las. Veja @variables decorador, Variável, Pacote e recurso.
from databricks.bundles.core import Bundle, Resources, Variable, variables
@variables
class Variables:
# Define a variable
warehouse_id: Variable[str]
def load_resources(bundle: Bundle) -> Resources:
# Resolve the variable
warehouse_id = bundle.resolve_variable(Variables.warehouse_id)
...
Em Python, também é possível acessar variáveis usando substituições.
sample_job = Job.from_dict(
{
"name": "sample_job",
"tasks": [
{
"task_key": "my_sql_query_task",
"sql_task": {
"warehouse_id": "${var.warehouse_id}",
"query": {
"query_id": "11111111-1111-1111-1111-111111111111",
},
...
Utilize substituições de destino para definir valores de variáveis para diferentes destinos de implantação.
Modifique o recurso definido em YAML ou Python
Para modificar o recurso, você pode referenciar funções mutadoras em databricks.yml, semelhante às funções que carregam o recurso. Este recurso pode ser usado independentemente do recurso de carregamento definido em Python e modifica o recurso definido tanto em YAML quanto em Python.
Primeiro, crie mutators.py na raiz do pacote com o seguinte conteúdo:
from dataclasses import replace
from databricks.bundles.core import Bundle, job_mutator
from databricks.bundles.jobs import Job, JobEmailNotifications
@job_mutator
def add_email_notifications(bundle: Bundle, job: Job) -> Job:
if job.email_notifications:
return job
email_notifications = JobEmailNotifications.from_dict(
{
"on_failure": ["${workspace.current_user.userName}"],
}
)
return replace(job, email_notifications=email_notifications)
Agora, use a configuração a seguir para executar a função add_email_notifications durante a implantação do pacote. Isso atualiza todos os trabalhos definidos no pacote com as notificações do email se eles estiverem ausentes. As funções mutadoras precisam ser especificadas em databricks.yml e executadas na ordem especificada. Job são executados para cada Job definido em um pacote e podem retornar uma cópia atualizada ou uma entrada não modificada. Os mutators também podem ser usados para outros campos, como a configuração do default Job clustering ou do SQL warehouse.
python:
mutators:
- 'mutators:add_email_notifications'
Se as funções lançarem uma exceção durante a execução do mutador, a implantação do pacote será interrompida.
Para configurar predefinições para destinos (por exemplo, para retomar o programar para o destino prod ), use modos de implantação e predefinições. Consulte Predefinições personalizadas.