Pythonでのバンドル構成
宣言型自動化バンドルのPythonサポートにより、宣言型自動化バンドルにバンドルのデプロイ時に適用される追加機能が拡張され、以下のことが可能になります。
-
Python コードでリソースを定義します。これらの定義は、 YAML で定義されたリソースと共存できます。
-
メタデータを使用してバンドルのデプロイメント中にリソースを動的に作成します。「メタデータを使用してリソースを作成する」を参照してください。
-
バンドルのデプロイ中に、YAML または Python で定義されたリソースを変更します。YAML または Python で定義されたリソースを変更するを参照してください。
ジョブのif/else 条件タスクやfor_each_taskなどの機能を使用して、ランタイム時にバンドル リソースを変更することもできます。
宣言型自動化バンドルの Python サポートに関するリファレンス ドキュメント(databricks-bundles パッケージ)は、 https://databricks.github.io/cli/python/で入手できます。
必要条件
宣言型自動化バンドルのPythonサポートを使用するには、まず以下の手順を実行する必要があります。
-
Databricks CLIバージョン 0.275.0 以上をインストールします。「Databricks CLI をインストールまたは更新する」を参照してください。
-
Databricks ワークスペースに対して認証を行っていない場合は、認証します。
Bashdatabricks configure -
uvをインストールします。uvのインストールを参照してください。Python for Declarative Automation Bundlesは、uvを使用して仮想環境を作成し、必要な依存関係をインストールします。あるいは、 venvなどの他のツールを使用してPython環境を設定することもできます。
テンプレートからプロジェクトを作成する
宣言型自動化バンドル用の新しいPythonサポートプロジェクトを作成するには、 pydabsテンプレートを使用してバンドルを初期化します。
databricks bundle init pydabs
プロンプトが表示されたら、プロジェクトに名前を付け ( my_pydabs_projectなど)、ノートブックと Python パッケージを含めることを受け入れます。
次に、新しいプロジェクトフォルダに新しい仮想環境を作成します。
cd my_pydabs_project
uv sync
デフォルトでは、テンプレートには Python として定義されたジョブの例が resources/my_pydabs_project_job.py ファイルに含まれています。
from databricks.bundles.jobs import Job
my_pydabs_project_job = Job.from_dict(
{
"name": "my_pydabs_project_job",
"tasks": [
{
"task_key": "notebook_task",
"notebook_task": {
"notebook_path": "src/notebook.ipynb",
},
},
],
},
)
Job.from_dict関数は、YAML と同じ形式を使用する Python 辞書を受け入れます。リソースはデータクラス構文を使用して構築することもできます。
from databricks.bundles.jobs import Job, Task, NotebookTask
my_pydabs_project_job = Job(
name="my_pydabs_project_job",
tasks=[
Task(
task_key="notebook_task",
notebook_task=NotebookTask(
notebook_path="src/notebook.ipynb",
),
),
],
)
Python ファイルは、databricks.ymlの python セクションで指定されているエントリポイントを介してロードされます。
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
By デフォルト, resources/__init__.py には、リソース パッケージ内のすべての Python ファイルを読み込む関数が含まれています。
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and is responsible for loading
bundle resources defined in Python code. This function is called by Databricks CLI during
bundle deployment. After deployment, this function is not used.
"""
# the default implementation loads all Python files in 'resources' directory
return load_resources_from_current_package_module()
ジョブまたはパイプラインをデプロイして実行する
バンドルを開発ターゲットにデプロイするには、バンドル プロジェクト ルートから bundle deploy コマンド を使用します。
databricks bundle deploy --target dev
このコマンドは、バンドル・プロジェクトに対して定義されているすべてのものをデプロイします。たとえば、デフォルト テンプレートを使用して作成されたプロジェクトでは、 [dev yourname] my_pydabs_project_job というジョブがワークスペースにデプロイされます。 そのジョブを見つけるには、Databricks ワークスペースの [ジョブとパイプライン ] に移動します。
バンドルがデプロイされたら、 bundle summary コマンドを使用して 、デプロイされたすべてのものを確認できます。
databricks bundle summary --target dev
最後に、ジョブまたはパイプラインを実行するには、 bundle 実行コマンドを使用します。
databricks bundle run my_pydabs_project_job
既存のバンドルを更新する
既存のバンドルを更新するには、 「テンプレートからプロジェクトを作成する」の説明に従ってプロジェクト テンプレート構造をモデル化します。YAML を使用した既存のバンドルは、 databricks.ymlにpythonセクションを追加することで、Python コードとして定義されたリソースを含めるように更新できます。
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
指定した 仮想環境 には、インストールされている databricks-bundles PyPi パッケージが含まれている必要があります。
pip install databricks-bundles==0.275.0
リソース フォルダには __init__.py 次のファイルが含まれている必要があります。
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and
is responsible for loading bundle resources defined in Python code.
This function is called by Databricks CLI during bundle deployment.
After deployment, this function is not used.
"""
# default implementation loads all Python files in 'resources' folder
return load_resources_from_current_package_module()
既存のジョブをPythonに変換する
既存のジョブを Python に変換するには、 コードとして表示 機能を使用できます。「ジョブをコードとして表示する」を参照してください。
-
Databricks ワークスペースで既存のジョブのページを開きます。
-
クリック
 「今すぐ実行」 ボタンの左側にある kebab をクリックし、 「コードとして表示」 をクリックします。
「今すぐ実行」 ボタンの左側にある kebab をクリックし、 「コードとして表示」 をクリックします。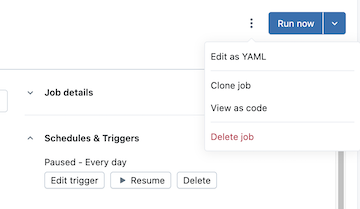
-
Python を選択し、次に 宣言型自動化バンドルを 選択します。
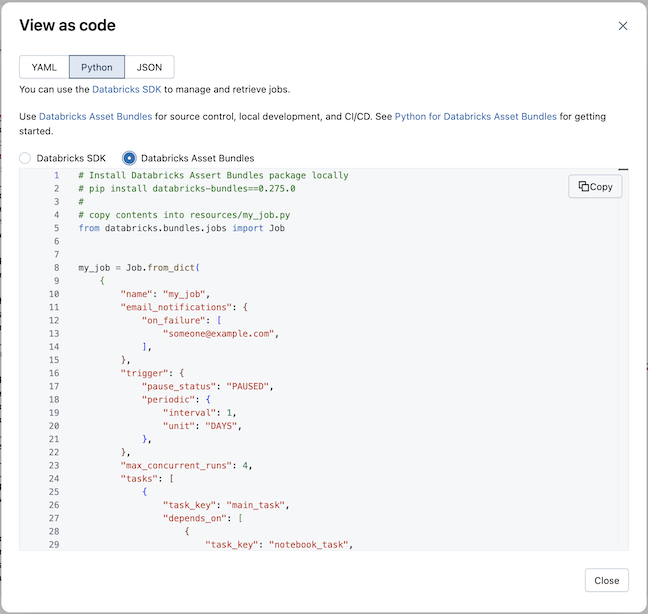
-
「コピー 」をクリックし、生成されたPythonをバンドル・プロジェクトの「リソース」フォルダーにPythonファイルとして保存します。
また、既存のジョブとパイプラインの YAML を表示およびコピーして、バンドル構成 YAML ファイルに直接貼り付けることもできます。
メタデータを使用したリソースの作成
load_resources 関数のデフォルト実装では、resources パッケージ内の Python ファイルが読み込まれます。Python を使用して、プログラムでリソースを作成できます。たとえば、設定ファイルをロードし、ループでジョブを作成できます。
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
from databricks.bundles.jobs import Job
def create_job(country: str):
my_notebook = {
"task_key": "my_notebook",
"notebook_task": {
"notebook_path": "files/my_notebook.py",
},
}
return Job.from_dict(
{
"name": f"my_job_{country}",
"tasks": [my_notebook],
}
)
def load_resources(bundle: Bundle) -> Resources:
resources = load_resources_from_current_package_module()
for country in ["US", "NL"]:
resources.add_resource(f"my_job_{country}", create_job(country))
return resources
バンドル変数へのアクセス
バンドルの置換とカスタム変数を使用すると、値を動的に取得できるため、バンドルがデプロイされターゲットで実行されるときに設定を決定できます。バンドル変数の詳細については、 「カスタム変数」を参照してください。
Pythonでは、変数を定義し、 bundleを使用して変数にアクセスします。 @variablesデコレータ、変数、バンドル、およびリソースを参照してください。
from databricks.bundles.core import Bundle, Resources, Variable, variables
@variables
class Variables:
# Define a variable
warehouse_id: Variable[str]
def load_resources(bundle: Bundle) -> Resources:
# Resolve the variable
warehouse_id = bundle.resolve_variable(Variables.warehouse_id)
...
Python では、置換を使用して変数にアクセスすることもできます。
sample_job = Job.from_dict(
{
"name": "sample_job",
"tasks": [
{
"task_key": "my_sql_query_task",
"sql_task": {
"warehouse_id": "${var.warehouse_id}",
"query": {
"query_id": "11111111-1111-1111-1111-111111111111",
},
...
ターゲット オーバーライドを使用して、さまざまなデプロイメント ターゲットの変数値を設定します。
YAMLまたはPythonで定義されたリソースを変更する
リソースを変更するには、リソースをロードする関数と同様に、 databricks.yml内のミューテーター関数を参照できます。この機能は、Python で定義されたリソースの読み込みとは独立して使用でき、YAML と Python の両方で定義されたリソースを変更します。
まず、バンドル ルートに次の内容の mutators.py を作成します。
from dataclasses import replace
from databricks.bundles.core import Bundle, job_mutator
from databricks.bundles.jobs import Job, JobEmailNotifications
@job_mutator
def add_email_notifications(bundle: Bundle, job: Job) -> Job:
if job.email_notifications:
return job
email_notifications = JobEmailNotifications.from_dict(
{
"on_failure": ["${workspace.current_user.userName}"],
}
)
return replace(job, email_notifications=email_notifications)
次に、次の構成を使用して、バンドルのデプロイ中に add_email_notifications 関数を実行します。これにより、バンドルで定義されているすべてのジョブが不在の場合は、Eメール通知で更新されます。 ミューテーター関数は databricks.ymlで指定する必要があり、指定された順序で実行されます。ジョブミューテーターは、バンドルで定義されているすべてのジョブに対して実行され、更新されたコピーまたは変更されていない入力を返すことができます。 ミューテーターは、デフォルト ジョブ クラスターや SQLウェアハウスの構成など、他のフィールドにも使用できます。
python:
mutators:
- 'mutators:add_email_notifications'
ミューテーターの実行中に関数が例外をスローした場合、バンドルのデプロイは中止されます。
ターゲットのプリセットを構成するには (たとえば、 prodターゲットのスケジュールを一時停止解除する)、デプロイメント モードとプリセットを使用します。カスタムプリセットを参照してください。