Configurar compute para o trabalho
Configure o compute serverless ou clássico para as tarefas em um LakeFlow Job e escolha o tipo certo para cada tarefa.
As limitações do site serverless compute for Job incluem o seguinte:
- Programação contínua é compatível apenas com gatilhos de Transmissão estructurada limitados, como
Trigger.AvailableNow. Consulte Execução de Job continuamente. - Não há suporte para default ou acionadores de intervalo baseados em tempo na transmissão estruturada.
Para obter mais limitações, consulte limitações do compute sem servidor.
Cada trabalho pode ter uma ou mais tarefas. O senhor define compute recurso para cada tarefa. Várias tarefas definidas para o mesmo trabalho podem usar o mesmo recurso compute.
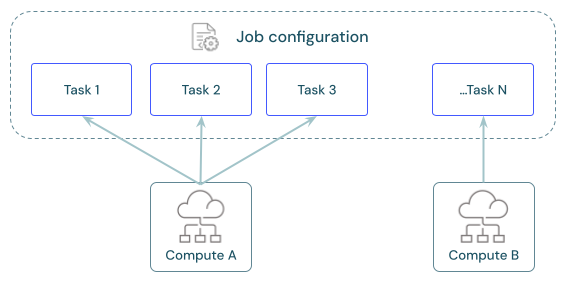
Compute recomendado para cada tarefa
A tabela a seguir indica os tipos de compute recomendados e suportados para cada tipo de tarefa.
sem servidor compute for Job tem limitações e não é compatível com todas as cargas de trabalho. Consulte as limitações do compute sem servidor.
Tarefa | Recomendado compute | Com suporte compute |
|---|---|---|
cadernos | Trabalho sem servidor | Job sem servidor, Job clássico, clássico para todos os fins |
Script Python | Trabalho sem servidor | Job sem servidor, Job clássico, clássico para todos os fins |
Python Wheel | Trabalho sem servidor | Job sem servidor, Job clássico, clássico para todos os fins |
SQL | sem servidor SQL warehouse | sem servidor SQL warehouse, pro SQL warehouse |
LakeFlow Pipelines | sem servidor pipeline | sem servidor pipeline, clássico pipeline |
dbt | sem servidor SQL warehouse | sem servidor SQL warehouse, pro SQL warehouse |
dbt CLI comando | Trabalho sem servidor | Job sem servidor, Job clássico, clássico para todos os fins |
JAR | Trabalho clássico | Trabalho clássico, clássico para todos os fins |
Spark Submit | Trabalho clássico | Trabalho clássico |
Os preços do LakeFlow Jobs estão vinculados ao compute usado para executar a tarefa. Para obter mais detalhes, consulte Databricks preços.
Configurar compute para o trabalho
O trabalho clássico compute é configurado diretamente na interface do usuário do LakeFlow Jobs, e essas configurações fazem parte da definição do trabalho. Todos os outros tipos de compute disponíveis armazenam suas configurações com outros workspace ativos. A tabela a seguir tem mais detalhes:
Tipo de Compute | Detalhes |
|---|---|
Trabalho clássico compute | O senhor configura o compute para o trabalho clássico usando a mesma interface do usuário e as mesmas configurações disponíveis para o compute para todos os fins. Consulte a referência de configuração de computação. |
sem servidor compute para o trabalho | serverless compute for Job é o default para todas as tarefas que o suportam. Databricks gerenciar compute configurações para serverless compute. Veja a execução do seu LakeFlow Jobs with serverless compute for fluxo de trabalho. |
SQL warehouses | serverless e pro SQL warehouse são configurados pelos administradores do workspace ou por usuários com privilégios irrestritos de criação de clustering. O senhor configura a tarefa para execução no site SQL warehouse existente. Consulte Conectar-se a um site SQL warehouse. |
LakeFlow Pipelines Compute | Você configura as configurações de compute para LakeFlow Pipelines durante a configuração do pipeline. Consulte Configure compute clássico para pipelines. A Databricks gerencia recursos de compute para LakeFlow Pipelines serverless. Veja Configurar um pipeline serverless. |
Compute para todos os fins | Opcionalmente, é possível configurar tarefas usando compute clássico multifuncional. A Databricks não recomenda essa configuração para Jobs de produção. Consulte a referência de configuração de compute e as exceções limitadas. |
Compartilhe compute em toda a tarefa
Configure a tarefa para usar o mesmo recurso do Job compute para otimizar o uso do recurso com o Job que orquestra várias tarefas. O compartilhamento compute entre as tarefas pode reduzir a latência associada aos tempos start-up.
O senhor pode usar um único recurso de Job compute para executar todas as tarefas que fazem parte do Job ou vários recursos de Job otimizados para cargas de trabalho específicas. Qualquer tarefa compute configurada como parte de uma tarefa está disponível para todas as outras tarefas da tarefa.
A tabela a seguir destaca as diferenças entre o Job compute configurado para uma única tarefa e o Job compute compartilhado entre tarefas:
Tarefa única | Compartilhado em toda a tarefa | |
|---|---|---|
Iniciar | Quando a execução da tarefa começa. | Quando a primeira execução de tarefa configurada para usar o recurso compute começar. |
Encerrar | Após a execução da tarefa. | Após a tarefa final configurada para usar o recurso compute execução. |
parado compute | Não aplicável. | O cálculo permanece ligado e parado enquanto a tarefa não usa o recurso de execução compute. |
Um clustering de trabalho compartilhado tem o escopo de uma única execução de trabalho e não pode ser usado por outro trabalho ou execução do mesmo trabalho.
biblioteca não pode ser declarado em uma configuração de clustering de trabalho compartilhado. O senhor deve adicionar a biblioteca dependente nas configurações da tarefa.
Estado do motorista compartilhado entre tarefas
Quando múltiplas tarefas compartilham um recurso compute do Job, a tarefa é executada no mesmo driver JVM. O estado da classe e os singletons persistem ao longo da tarefa para a duração da execução do Job. Para a maioria das cargas de trabalho, isso é transparente, mas esteja ciente das seguintes implicações:
- Os singletons e objetos companheirosScala são compartilhados entre tarefas. O estado mutável em um objeto companheiro Scala persiste entre tarefas que são executadas no mesmo cluster compartilhado. Se tarefas paralelas lerem ou escreverem na mesma variável de objeto complementar, o valor de uma tarefa poderá sobrescrever o de outra. Para obter um exemplo prático, consulte os artigos da Base de Conhecimento Fluxo de trabalho multitarefa usando valores de parâmetro incorretos.
- A biblioteca carregada por uma tarefa permanece disponível para a tarefa subsequente para a duração da execução do Trabalho.
Se o seu código exigir isolamento em nível de tarefa, use uma das seguintes abordagens:
- Configure cada tarefa para usar um recurso compute de trabalho separado.
- Adicione dependências de tarefas explícitas para que a tarefa seja executada sequencialmente e não em paralelo.
- Refatore o código para evitar depender de estado único ou estado mutável compartilhado. Por exemplo, passe os parâmetros explicitamente para cada função em vez de lê-los de um objeto auxiliar.
Revisar, configurar e swap Job compute
A seção **Compute** no painel **Detalhes do Job** lista todo o compute configurado para as tarefas no Job atual.
A tarefa configurada para usar um compute recurso é destacada no gráfico da tarefa quando o senhor passa o mouse sobre a especificação compute.
Use o botão de troca para alterar o endereço compute para todas as tarefas associadas a um recurso compute.
O trabalho clássico compute recurso tem uma opção Configure (Configurar ). Outros compute recursos oferecem ao senhor opções para view e modificar compute detalhes de configuração.
Recursos adicionais
Para obter detalhes adicionais sobre a configuração de jobs clássicos do Databricks, consulte Configurar o compute clássico para Lakeflow Jobs.