Improve RAG application quality
This article provides an overview of how you can refine each component to increase the quality of your retrieval augmented generation (RAG) application.
There are myriad “knobs” to tune at every point in both the offline data pipeline, and online RAG chain. While there are countless others, the article focuses on the most important knobs that have the greatest impact on the quality of your RAG application. Databricks recommends starting with these knobs.
Two types of quality considerations
From a conceptual point of view, it's helpful to view RAG quality knobs through the lens of the two key types of quality issues:
-
Retrieval quality: Are you retrieving the most relevant information for a given retrieval query?
It's difficult to generate high-quality RAG output if the context provided to the LLM is missing important information or contains superfluous information.
-
Generation quality: Given the retrieved information and the original user query, is the LLM generating the most accurate, coherent, and helpful response possible?
Issues here can manifest as hallucinations, inconsistent output, or failure to directly address the user query.
RAG apps have two components that can be iterated on to address quality challenges: data pipeline and the chain. It's tempting to assume a clean division between retrieval issues (simply update the data pipeline) and generation issues (update the RAG chain). However, the reality is more nuanced. Retrieval quality can be influenced by both the data pipeline (for example, parsing/chunking strategy, metadata strategy, embedding model) and the RAG chain (for example, user query transformation, number of chunks retrieved, re-ranking). Similarly, generation quality will invariably be impacted by poor retrieval (for example, irrelevant or missing information affecting model output).
This overlap underscores the need for a holistic approach to RAG quality improvement. By understanding which components to change across both the data pipeline and RAG chain, and how these changes affect the overall solution, you can make targeted updates to improve RAG output quality.
Data pipeline quality considerations
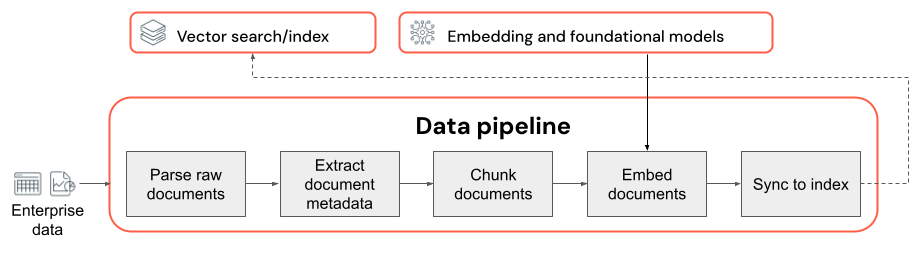
Key considerations about the data pipeline:
- The composition of the input data corpus.
- How raw data is extracted and transformed into a usable format (for example, parsing a PDF document).
- How documents are split into smaller chunks and how those chunks are formatted (for example, chunking strategy, and chunk size).
- The metadata (like section title or document title) extracted about each document and/or chunk. How this metadata is included (or not included) in each chunk.
- The embedding model used to convert text into vector representations for similarity search.
RAG chain
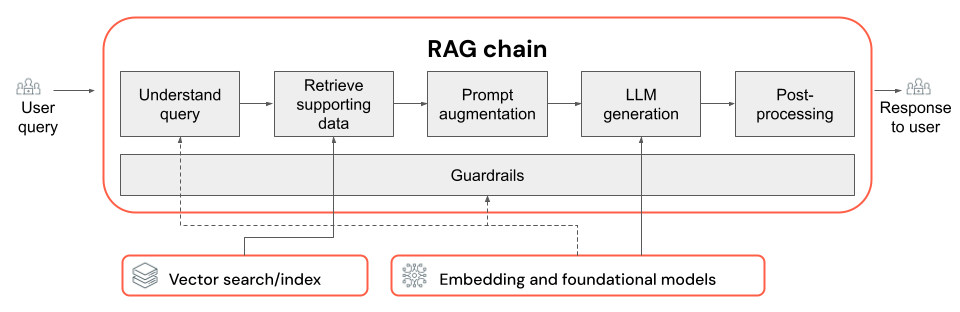
- The choice of LLM and its parameters (for example, temperature and max tokens).
- The retrieval parameters (for example, the number of chunks or documents retrieved).
- The retrieval approach (for example, keyword vs. hybrid vs. semantic search, rewriting the user's query, transforming a user's query into filters, or re-ranking).
- How to format the prompt with the retrieved context to guide the LLM toward quality output.