Improve RAG chain quality
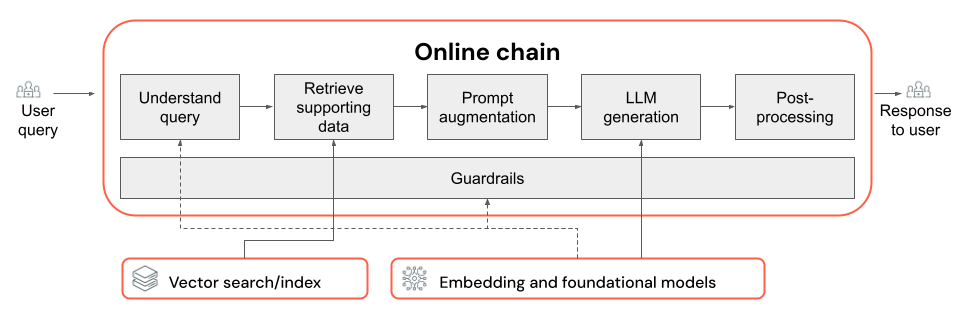
This article covers how you can improve the quality of the RAG app using components of the RAG chain.
The RAG chain takes a user query as input, retrieves relevant information given that query, and generates an appropriate response grounded on the retrieved data. While the exact steps within a RAG chain can vary widely depending on the use case and requirements, the following are the key components to consider when building your RAG chain:
- Query understanding: Analyzing and transforming user queries to better represent intent and extract relevant information, such as filters or keywords, to improve the retrieval process.
- Retrieval: Finding the most relevant chunks of information given a retrieval query. In the unstructured data case, this typically involves one or a combination of semantic or keyword-based search.
- Prompt augmentation: Combining a user query with retrieved information and instructions to guide the LLM towards generating high-quality responses.
- LLM: Selecting the most appropriate model (and model parameters) for your application to optimize/balance performance, latency, and cost.
- Post-processing and guardrails: Applying additional processing steps and safety measures to ensure the LLM-generated responses are on-topic, factually consistent, and adhere to specific guidelines or constraints.
Iteratively implement & evaluate quality fixes shows you how to iterate over the components of a chain.
Query understanding
Using the user query directly as a retrieval query can work for some queries. However, it is generally beneficial to reformulate the query before the retrieval step. Query understanding comprises a step (or series of steps) at the beginning of a chain to analyze and transform user queries to better represent intent, extract relevant information, and ultimately help the subsequent retrieval process. Approaches to transforming a user query to improve retrieval include:
-
Query rewriting: Query rewriting involves translating a user query into one or more queries that better represent the original intent. The goal is to reformulate the query in a way that increases the likelihood of the retrieval step finding the most relevant documents. This can be particularly useful when dealing with complex or ambiguous queries that might not directly match the terminology used in the retrieval documents.
Examples:
- Paraphrasing conversation history in a multi-turn chat
- Correcting spelling mistakes in the user's query
- Replacing words or phrases in the user query with synonyms to capture a broader range of relevant documents
importantQuery rewriting must be done in conjunction with changes to the retrieval component
-
Filter extraction: In some cases, user queries may contain specific filters or criteria that can be used to narrow down the search results. Filter extraction involves identifying and extracting these filters from the query and passing them to the retrieval step as additional parameters. This can help improve the relevance of the retrieved documents by focusing on specific subsets of the available data.
Examples:
- Extracting specific time periods mentioned in the query, such as “articles from the last 6 months” or “reports from 2023”.
- Identifying mentions of specific products, services, or categories in the query, such as “Databricks Professional Services” or “laptops”.
- Extracting geographic entities from the query, such as city names or country codes.
noteFilter extraction must be done in conjunction with changes to both metadata extraction data pipeline and retriever chain components. The metadata extraction step should ensure that the relevant metadata fields are available for each document/chunk, and the retrieval step should be implemented to accept and apply extracted filters.
In addition to query rewriting and filter extraction, another important consideration in query understanding is whether to use a single LLM call or multiple calls. While using a single call with a carefully crafted prompt can be efficient, there are cases where breaking down the query understanding process into multiple LLM calls can lead to better results. This, by the way, is a generally applicable rule of thumb when you are trying to implement a number of complex logic steps into a single prompt.
For example, you might use one LLM call to classify the query intent, another to extract relevant entities, and a third to rewrite the query based on the extracted information. Although this approach may add some latency to the overall process, it can allow for more fine-grained control and potentially improve the quality of the retrieved documents.
Multistep query understanding for a support bot
Here's how a multi-step query understanding component might look for a customer support bot:
- Intent classification: Use an LLM to classify the user's query into predefined categories, such as “product information”, “troubleshooting”, or “account management”.
- Entity extraction: Based on the identified intent, use another LLM call to extract relevant entities from the query, such as product names, reported errors, or account numbers.
- Query rewriting: Use the extracted intent and entities to rewrite the original query into a more specific and targeted format, for example, “My RAG chain is failing to deploy on Model Serving, I'm seeing the following error…”.
Retrieval
The retrieval component of the RAG chain is responsible for finding the most relevant chunks of information given a retrieval query. In the context of unstructured data, retrieval typically involves one or a combination of semantic search, keyword-based search, and metadata filtering. The choice of retrieval strategy depends on the specific requirements of your application, the nature of the data, and the types of queries you expect to handle. Let's compare these options:
- Semantic search: Semantic search uses an embedding model to convert each chunk of text into a vector representation that captures its semantic meaning. By comparing the vector representation of the retrieval query with the vector representations of the chunks, semantic search can retrieve conceptually similar documents, even if they don't contain the exact keywords from the query.
- Keyword-based search: Keyword-based search determines the relevance of documents by analyzing the frequency and distribution of shared words between the retrieval query and the indexed documents. The more often the same words appear in both the query and a document, the higher the relevance score assigned to that document.
- Hybrid search: Hybrid search combines the strengths of both semantic and keyword-based search by employing a two-step retrieval process. First, it performs a semantic search to retrieve a set of conceptually relevant documents. Then, it applies keyword-based search on this reduced set to further refine the results based on exact keyword matches. Finally, it combines the scores from both steps to rank the documents.
Compare retrieval strategies
The following table contrasts each of these retrieval strategies against one another:
Semantic search | Keyword search | Hybrid search | |
|---|---|---|---|
Simple explanation | If the same concepts appear in the query and a potential document, they are relevant. | If the same words appear in the query and a potential document, they are relevant. The more words from the query in the document, the more relevant that document is. | Runs BOTH a semantic search and keyword search, then combines the results. |
Example use case | Customer support where user queries are different than the words in the product manuals. Example: “how do i turn my phone on?” and the manual section is called “toggling the power”. | Customer support where queries contain specific, non descriptive technical terms. Example: “what does model HD7-8D do?” | Customer support queries that combined both semantic and technical terms. Example: “how do I turn on my HD7-8D?” |
Technical approaches | Uses embeddings to represent text in a continuous vector space, enabling semantic search. | Relies on discrete token-based methods like bag-of-words, TF-IDF, BM25 for keyword matching. | Use a re-ranking approach to combine the results, such as reciprocal rank fusion or a re-ranking model. |
Strengths | Retrieving contextually similar information to a query, even if the exact words are not used. | Scenarios requiring precise keyword matches, ideal for specific term-focused queries such as product names. | Combines the best of both approaches. |
Ways to enhance the retrieval process
In addition to these core retrieval strategies, there are several techniques you can apply to further enhance the retrieval process:
- Query expansion: Query expansion can help capture a broader range of relevant documents by using multiple variations of the retrieval query. This can be achieved by either conducting individual searches for each expanded query, or using a concatenation of all expanded search queries in a single retrieval query.
Query expansion must be done in conjunction with changes to the query understanding component (RAG chain). The multiple variations of a retrieval query are typically generated in this step.
- Re-ranking: After retrieving an initial set of chunks, apply additional ranking criteria (for example, sort by time) or a reranker model to re-order the results. Re-ranking can help prioritize the most relevant chunks given a specific retrieval query. Reranking with cross-encoder models such as mxbai-rerank and ColBERTv2 can yield an uplift in retrieval performance.
- Metadata filtering: Use metadata filters extracted from the query understanding step to narrow down the search space based on specific criteria. Metadata filters can include attributes like document type, creation date, author, or domain-specific tags. By combining metadata filters with semantic or keyword-based search, you can create more targeted and efficient retrieval.
Metadata filtering must be done in conjunction with changes to the query understanding (RAG chain) and metadata extraction (data pipeline) components.
Prompt augmentation
Prompt augmentation is the step where the user query is combined with the retrieved information and instructions in a prompt template to guide the language model toward generating high-quality responses. Iterating on this template to optimize the prompt provided to the LLM (AKA prompt engineering) is required to ensure that the model is guided to produce accurate, grounded, and coherent responses.
There are entire guides to prompt engineering, but here are some considerations to keep in mind when you're iterating on the prompt template:
- Provide examples
- Include examples of well-formed queries and their corresponding ideal responses within the prompt template itself (few-shot learning). This helps the model understand the desired format, style, and content of the responses.
- One useful way to come up with good examples is to identify types of queries your chain struggles with. Create gold-standard responses for those queries and include them as examples in the prompt.
- Ensure that the examples you provide are representative of user queries you anticipate at inference time. Aim to cover a diverse range of expected queries to help the model generalize better.
- Parameterize your prompt template
- Design your prompt template to be flexible by parameterizing it to incorporate additional information beyond the retrieved data and user query. This could be variables such as current date, user context, or other relevant metadata.
- Injecting these variables into the prompt at inference time can enable more personalized or context-aware responses.
- Consider Chain-of-Thought prompting
- For complex queries where direct answers aren't readily apparent, consider Chain-of-Thought (CoT) prompting. This prompt engineering strategy breaks down complicated questions into simpler, sequential steps, guiding the LLM through a logical reasoning process.
- By prompting the model to “think through the problem step-by-step,” you encourage it to provide more detailed and well-reasoned responses, which can be particularly effective for handling multi-step or open-ended queries.
- Prompts may not transfer across models
- Recognize that prompts often do not transfer seamlessly across different language models. Each model has its own unique characteristics where a prompt that works well for one model may not be as effective for another.
- Experiment with different prompt formats and lengths, refer to online guides (such as OpenAI Cookbook or Anthropic cookbook), and be prepared to adapt and refine your prompts when switching between models.
LLM
The generation component of the RAG chain takes the augmented prompt template from the previous step and passes it to a LLM. When selecting and optimizing an LLM for the generation component of a RAG chain, consider the following factors, which are equally applicable to any other steps that involve LLM calls:
- Experiment with different off-the-shelf models.
- Each model has its own unique properties, strengths, and weaknesses. Some models may have a better understanding of certain domains or perform better on specific tasks.
- As mentioned prior, keep in mind that the choice of model may also influence the prompt engineering process, as different models may respond differently to the same prompts.
- If there are multiple steps in your chain that require an LLM, such as calls for query understanding in addition to the generation step, consider using different models for different steps. More expensive, general-purpose models may be overkill for tasks like determining the intent of a user query.
- Start small and scale up as needed.
- While it may be tempting to immediately reach for the most powerful and capable models available (e.g., GPT-4, Claude), it's often more efficient to start with smaller, more lightweight models.
- In many cases, smaller open-source alternatives like Llama 3 can provide satisfactory results at a lower cost and with faster inference times. These models can be particularly effective for tasks that don't require highly complex reasoning or extensive world knowledge.
- As you develop and refine your RAG chain, continuously assess the performance and limitations of your chosen model. If you find that the model struggles with certain types of queries or fails to provide sufficiently detailed or accurate responses, consider scaling up to a more capable model.
- Monitor the impact of changing models on key metrics such as response quality, latency, and cost to ensure that you're striking the right balance for the requirements of your specific use case.
- Optimize model parameters
- Experiment with different parameter settings to find the optimal balance between response quality, diversity, and coherence. For example, adjusting the temperature can control the randomness of the generated text, while max_tokens can limit the response length.
- Be aware that the optimal parameter settings may vary depending on the specific task, prompt, and desired output style. Iteratively test and refine these settings based on evaluation of the generated responses.
- Task-specific fine-tuning
- As you refine performance, consider fine-tuning smaller models for specific sub-tasks within your RAG chain, such as query understanding.
- By training specialized models for individual tasks with the RAG chain, you can potentially improve the overall performance, reduce latency, and lower inference costs compared to using a single large model for all tasks.
- Continued pre-training
- If your RAG application deals with a specialized domain or requires knowledge that is not well-represented in the pre-trained LLM, consider performing continued pre-training (CPT) on domain-specific data.
- Continued pre-training can improve a model's understanding of specific terminology or concepts unique to your domain. In turn this can reduce the need for extensive prompt engineering or few-shot examples.
Post-processing and guardrails
After the LLM generates a response, it is often necessary to apply post-processing techniques or guardrails to ensure that the output meets the desired format, style, and content requirements. This final step (or multiple steps) in the chain can help maintain consistency and quality across the generated responses. If you are implementing post-processing and guardrails, consider some of the following:
- Enforcing output format
- Depending on your use case, you may require the generated responses to adhere to a specific format, such as a structured template or a particular file type (such as JSON, HTML, Markdown, and so on).
- If structured output is required, libraries such as Instructor or Outlines provide good starting points to implement this kind of validation step.
- When developing, take time to ensure that the post-processing step is flexible enough to handle variations in the generated responses while maintaining the required format.
- Maintaining style consistency
- If your RAG application has specific style guidelines or tone requirements (e.g., formal vs. casual, concise vs. detailed), a post-processing step can both check and enforce these style attributes across generated responses.
- Content filters and safety guardrails
- Depending on the nature of your RAG application and the potential risks associated with generated content, it may be important to implement content filters or safety guardrails to prevent the output of inappropriate, offensive, or harmful information.
- Consider using models like Llama Guard or APIs specifically designed for content moderation and safety, such as OpenAI's moderation API, to implement safety guardrails.
- Handling hallucinations
- Defending against hallucinations can also be implemented as a post-processing step. This may involve cross-referencing the generated output with retrieved documents, or using additional LLMs to validate the factual accuracy of the response.
- Develop fallback mechanisms to handle cases where the generated response fails to meet the factual accuracy requirements, such as generating alternative responses or providing disclaimers to the user.
- Error handling
- With any post-processing steps, implement mechanisms to gracefully deal with cases where the step encounters an issue or fails to generate a satisfactory response. This could involve generating a default response, or escalating the issue to a human operator for manual review.