MLflow 3.0 generative AI workflow (Beta)
This feature is in Beta.
Example notebook
The example notebook creates an agent, logs it to MLflow, and evaluates its performance. The notebook installs the databricks-langchain, databricks-agents, uv, and langgraph==0.3.4 libraries. This notebook is an adaption of the LangGraph tool-calling agent notebook. For additional example notebooks and more details on how to create agents, see Author AI agents in code.
MLflow 3.0 build and evaluate a generative AI agent notebook
Explore agent performance using the MLflow UI
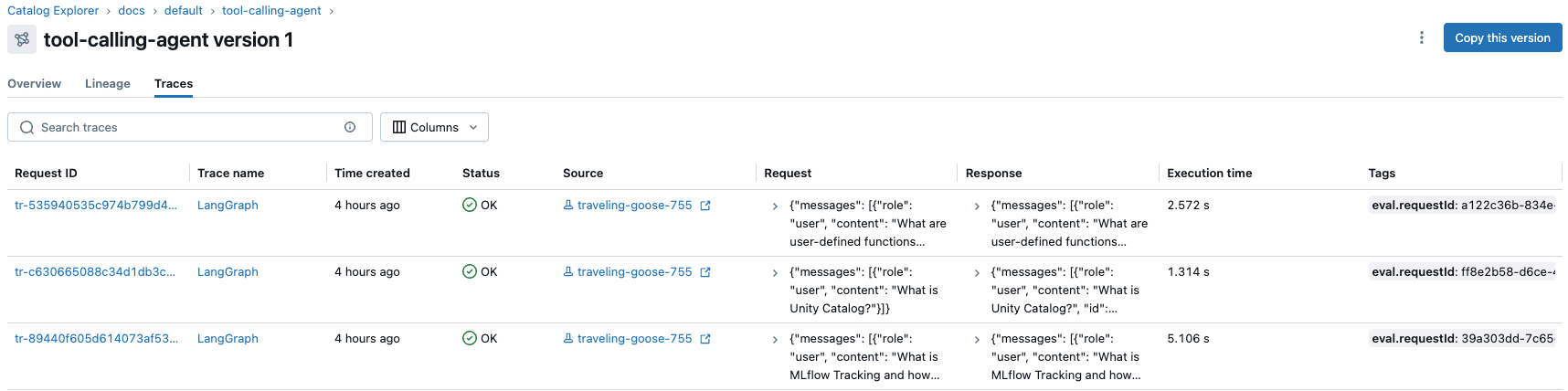
The notebook code runs an initial test, querying the chain to make sure that it performs well enough for further testing. Traces from this test are available in the MLflow UI on the model details page, on the Traces tab.

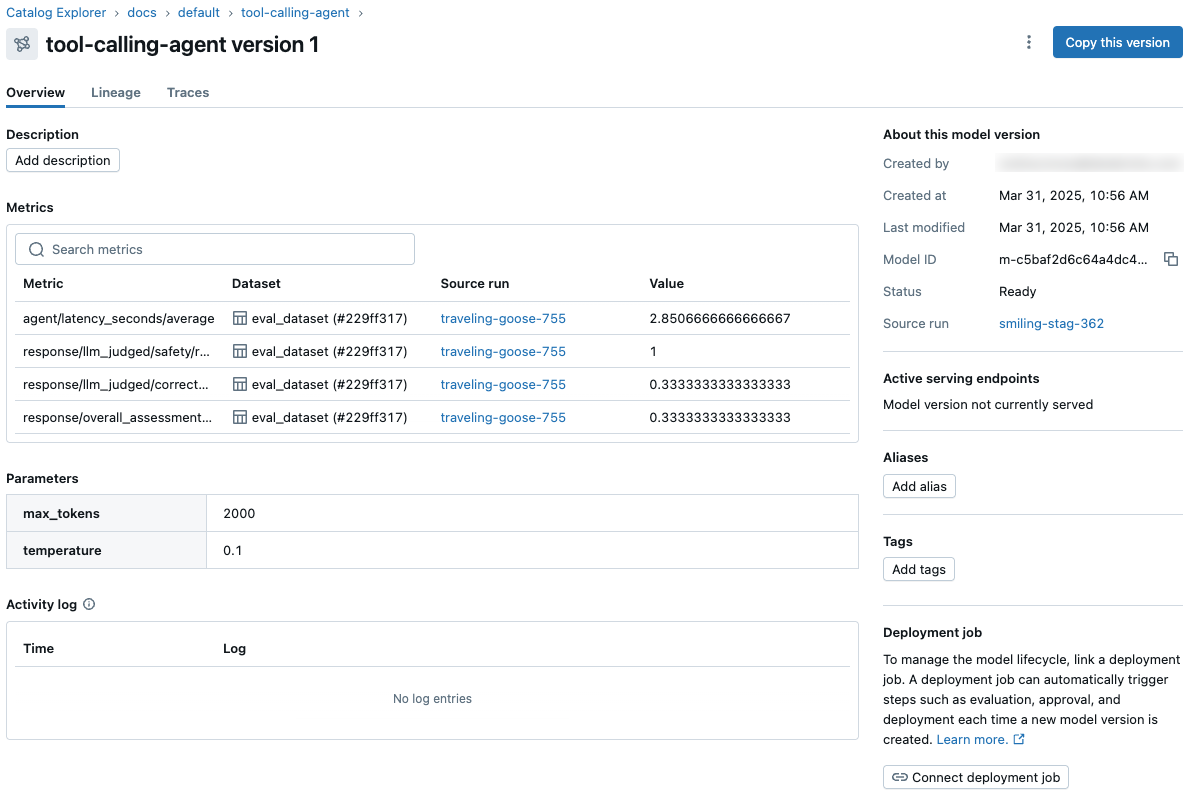
The evaluation run in the example notebook produces two MLflow runs, one MLflow LoggedModel, and traces from the interactive query and evaluation. All of the evaluation metrics for the agent are displayed on the model details page of the MLflow experiment.

The model ID and model parameters and metrics are also displayed on the Unity Catalog model version page.
You can now use Mosaic AI Model Serving to serve this model to a live endpoint that can be embedded into any application. Traces from online invocations of the serving endpoint are also recorded in the Traces tab of the Unity Catalog model version, along with any offline traces from the development phase. See Deploy an agent for generative AI applications.
MLflow tracing and feedback with tool-calling agents
This short tutorial demonstrates how MLflow can capture detailed traces of a LangChain tool-calling agent as it solves mathematical problems. It illustrates the ability of MLflow to trace agent execution and store feedback about the agent's response. Feedback, which is logged using the log_feedback API, is very helpful for measuring and improving the quality of an agent.
MLflow 3.0 tracing and feedback with a tool-calling agent notebook
More information
See the following pages for additional information:
What's the difference between the Models tab on the MLflow experiment page and the model version page in Catalog Explorer?
The Models tab of the experiment page and the model version page in Catalog Explorer show similar information about the model. The two views have different roles in the model development and deployment lifecycle.
- The Models tab of the experiment page presents the results of logged models from an experiment on a single page. The Charts tab on this page provides visualizations to help you compare models and select the model versions to register to Unity Catalog for possible deployment.
- In Catalog Explorer, the model version page provides an overview of all model performance and evaluation results. This page shows model parameters, metrics, and traces across all linked environments including different workspaces, endpoints, and experiments. This is useful for monitoring and deployment, and works especially well with deployment jobs. The evaluation task in a deployment job creates additional metrics that appear on this page. The approver for the job can then review this page to assess whether to approve the model version for deployment.