Databricks Connect for Databricks Runtime 12.2 LTS 以下
Databricks Connect では、代わりに Databricks Runtime 13.0 以降に Databricks Connect を使用することをお勧めします。
Databricks は、Databricks Runtime 12.2 LTS 以下の Databricks Connect の新機能の作業を計画していません。
Databricks ConnectIDEsを使用すると、Visual Studio Code やPyCharm 、ノートブック サーバー、その他のカスタム アプリケーションなどの一般的な をDatabricks クラスターに接続できます。
この記事では、Databricks Connect のしくみ、Databricks Connect の使用を開始する手順、Databricks Connect の使用時に発生する可能性のある問題のトラブルシューティング方法、Databricks Connect を使用した実行と Databricks ノートブックでの実行の違いについて説明します。
概要
Databricks Connect は、Databricks Runtime のクライアント ライブラリです。 これにより、 を使用してジョブを書き込み、ローカルのSparkAPI DatabricksSparkセッションではなく、 クラスターでリモートで実行できます。
たとえば、データフレーム を使用して コマンドspark.read.format(...).load(...).groupBy(...).agg(...).show() Databricks Connectを実行すると、コマンドの論理表現が で実行されているSpark Databricksサーバーに送信され、リモート クラスターで実行されます。
Databricks Connectを使用すると、次のことができます。
- 大規模な Spark ジョブを任意の Python、R、 Scala、または Java アプリケーションから実行できます。
import pyspark、require(SparkR)、import org.apache.sparkできる場所ならどこでも、IDEプラグインをインストールしたり、Spark送信スクリプトを使用したりすることなく、アプリケーションから直接ジョブを実行Sparkできるようになりました。 - IDEでコードをステップ実行してデバッグする場合でも、リモートクラスターで作業しています。
- ライブラリの開発時に迅速に反復します。 で または ライブラリの依存関係を変更した後でクラスターを再開する必要はありません。これは、クラスター内で各クライアント セッションが互いに分離されているためです。PythonJavaDatabricks Connect
- 作業を失うことなくアイドル状態のクラスターをシャットダウンします。 クライアント アプリケーションはクラスターから切り離されているため、クラスターの再起動やアップグレードの影響を受けません。通常、ノートブックで定義されているすべての変数、RDD、および データフレーム オブジェクトが失われます。
クエリを使用した PythonSQLDatabricksDatabricks SQL開発の場合、Python Databricks ConnectDatabricks SQLPythonDatabricks Connectでは、 の代わりに Connector を使用することをお勧めします。 用の コネクタは、 よりもセットアップが簡単です。また、 Databricks Connect はローカル マシンでジョブ実行を解析して計画し、ジョブはリモート コンピュート リソースで実行します。 これにより、ランタイムエラーのデバッグが特に困難になる可能性があります。 Databricks SQLConnector は、Python SQLクエリをリモート コンピュート リソースに直接送信し、結果をフェッチします。
必要条件
このセクションでは、Databricks Connect の要件の一覧を示します。
-
次の Databricks Runtime バージョンのみがサポートされています。
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
-
Python3 を開発用マシンにインストールする必要があり、クライアントPython インストールのマイナーPython バージョンは、Databricks クラスターのマイナー バージョンと同じである必要があります。次の表は、各 Databricks Runtime と共にインストールされる Python のバージョンを示しています。
Databricks Runtimeのバージョン
Pythonのバージョン
12.2 LTS ML, 12.2 LTS
3.9
11.3 LTS ML, 11.3 LTS
3.9
10.4 LTS ML, 10.4 LTS
3.8
9.1 LTS ML, 9.1 LTS
3.8
7.3 LTS
3.7
Databricksと共に使用するPython バージョンごとに、 仮想環境 Python Databricks Connectをアクティブ化することを強くお勧めします。Python 仮想環境は、Python と Databricks Connect の正しいバージョンを一緒に使用していることを確認するのに役立ちます。 これにより、関連する技術的な問題の解決に費やす時間を短縮できます。
たとえば、開発マシンで venv を使用していて、クラスターが 3.9 Python 実行されている場合は、そのバージョンで
venv環境を作成する必要があります。 次のコマンド例では、Python 3.9 でvenv環境をアクティブ化するスクリプトを生成し、これらのスクリプトを現在の作業ディレクトリ内の.venvという名前の隠しフォルダに配置します。Bash# Linux and macOS
python3.9 -m venv ./.venv
# Windows
python3.9 -m venv .\.venvこれらのスクリプトを使用してこの
venv環境をアクティブ化するには、venvsの仕組みを参照してください。別の例として、開発マシンで Conda を使用していて、クラスターが 3.9 Python実行されている場合は、そのバージョンでConda環境を作成する必要があります。たとえば、次のようにします。
Bashconda create --name dbconnect python=3.9この環境名で Conda 環境をアクティブ化するには、
conda activate dbconnectを実行します。 -
Databricks Connect のメジャー パッケージとマイナー パッケージのバージョンは、常に Databricks Runtime のバージョンと一致する必要があります。 Databricks では、Databricks Runtime のバージョンに一致する Databricks Connect の最新のパッケージを常に使用することをお勧めします。 たとえば、 Databricks Runtime 12.2 LTS クラスターを使用する場合は、
databricks-connect==12.2.*パッケージも使用する必要があります。
利用可能な Databricks Connect リリースとメンテナンス更新プログラムの一覧については、 Databricks Connect のリリースノート を参照してください。
- Java Runtime 環境(JRE) 8. クライアントはOpenJDK 8 JREでテストされています。 クライアントは Java 11 をサポートしていません。
Windows で、Databricks Connect が winutils.exeを見つけられないというエラーが表示された場合は、「 Windows で winutils.exe が見つからない」を参照してください。
クライアントをセットアップします
Databricks Connect のローカル クライアントを設定するには、次の手順を実行します。
ローカルの Databricks Connect クライアントの設定を開始する前に、Databricks Connect の 要件を満たす 必要があります。
手順 1: Databricks Connect クライアントをインストールする
-
仮想環境をアクティブ化した状態で、PySpark が既にインストールされている場合は、
uninstallコマンドを実行してアンインストールします。 これは、databricks-connectパッケージがPySparkと競合するためです。 詳細については、「 競合する PySpark インストール」を参照してください。 PySpark がすでにインストールされているかどうかを確認するには、showコマンドを実行します。Bash# Is PySpark already installed?
pip3 show pyspark
# Uninstall PySpark
pip3 uninstall pyspark -
仮想環境をアクティブ化したまま、
installコマンドを実行して Databricks Connect クライアントをインストールします。--upgradeオプションを使用して、既存のクライアント・インストールを指定したバージョンにアップグレードします。Bashpip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.
Databricks では、最新のパッケージがインストールされていることを確認するために、databricks-connect=X.Yではなく databricks-connect==X.Y.* を指定するために "ドット アスタリスク" 表記を追加することをお勧めします。
ステップ 2: 接続プロパティを構成する
-
次の設定プロパティを収集してください。
-
Databricks ワークスペースの URL。
-
Databricks の個人用アクセス トークン。
-
クラスターの ID。 クラスター ID は URL から取得できます。 ここで、クラスター ID は
0304-201045-hoary804です。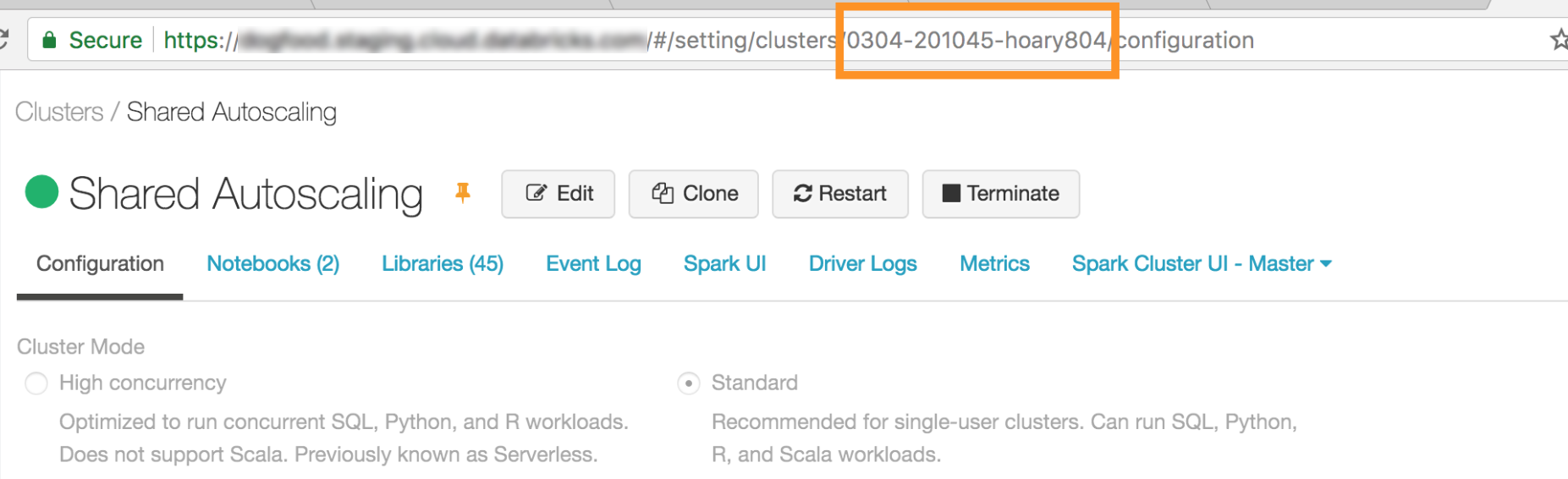
-
クラスターで Databricks Connect が接続するポート。 デフォルトのポートは
15001です。
-
-
次のように接続を構成します。
CLI、SQL 設定、または環境変数を使用できます。 設定方法の優先順位は、高いものから低いものへと、SQL 設定キー、CLI、および環境変数です。
-
CLI
databricks-connectを実行します。
Bashdatabricks-connect configureライセンスには次の情報が表示されます。
Copyright (2018) Databricks, Inc.
This library (the "Software") may not be used except in connection with the
Licensee's use of the Databricks Platform Services pursuant to an Agreement
...- ライセンスを受け入れ、構成値を指定します。 [Databricks Host and Databricks Token ] に、ステップ 1 でメモしたワークスペース URL と個人用アクセス トークンを入力します。
Do you accept the above agreement? [y/N] y
Set new config values (leave input empty to accept default):
Databricks Host [no current value, must start with https://]: <databricks-url>
Databricks Token [no current value]: <databricks-token>
Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id>
Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id>
Port [15001]: <port> -
SQL 構成または環境変数。 次の表は、手順 1 でメモした構成プロパティに対応する SQL 構成キーと環境変数を示しています。 SQL 設定キーを設定するには、
sql("set config=value")を使用します。 たとえば、sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh")のようになります。パラメーター
SQL 設定キー
環境変数名
Databricksホスト
spark.databricks.サービス.アドレス
DATABRICKS_ADDRESS
Databricksトークン
spark.databricks.サービス.トークン
DATABRICKS_API_TOKEN
ClusterID
spark.databricks.サービス.clusterId
クラスター
Org ID
spark.databricks.サービス.orgId
DATABRICKS_ORG_ID
ポート
spark.databricks.サービス.port
DATABRICKS_PORT
-
-
仮想環境をアクティブ化したまま、次のように Databricks への接続をテストします。
Bashdatabricks-connect test構成したクラスターが実行されていない場合、テストはクラスターを開始し、構成された自動終了時刻まで実行し続けます。 出力は次のようになります。
* PySpark is installed at /.../.../pyspark
* Checking java version
java version "1.8..."
Java(TM) SE Runtime Environment (build 1.8...)
Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode)
* Testing scala command
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state
../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2...
/_/
Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(100).reduce(_ + _)
Spark context Web UI available at https://...
Spark context available as 'sc' (master = local[*], app id = local-...).
Spark session available as 'spark'.
View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi
View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi
res0: Long = 4950
scala> :quit
* Testing python command
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state
View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi -
接続関連のエラーが表示されない場合 (
WARNメッセージは問題ありません)、正常に接続されています。
Databricks Connect を使用する
このセクションでは、Databricks Connect のクライアントを使用するように、優先する IDE またはノートブック サーバーを構成する方法について説明します。
このセクションの内容:
- JupyterLab
- クラシックJupyterノートブック
- PyCharm
- SparkR と RStudio デスクトップ
- sparklyrとRStudioデスクトップ
- IntelliJ (Scala または Java)
- PyDevとEclipseの組み合わせ
- Eclipse
- SBT
- Spark シェル
ジュピターラボ
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を JupyterLab と Python で使用するには、次の手順に従います。
-
JupyterLab をインストールするには、 Python 仮想環境をアクティブにして、ターミナルまたはコマンド プロンプトから次のコマンドを実行します。
Bashpip3 install jupyterlab -
Web ブラウザーで JupyterLab を起動するには、アクティブ化した Python 仮想環境から次のコマンドを実行します。
Bashjupyter labJupyterLab が Web ブラウザーに表示されない場合は、仮想環境から
localhostまたは127.0.0.1で始まる URL をコピーし、Web ブラウザーのアドレス バーに入力します。 -
新しいノートブックを作成する: JupyterLab で、メイン メニューの [ファイル] > [新しい > ノートブック ] をクリックし、[ Python 3 (ipykernel)] を選択して [選択 ] をクリックします。
-
ノートブックの最初のセルに、 サンプル コード または独自のコードを入力します。独自のコードを使用する場合は、少なくとも、サンプルコードに示すように、
SparkSession.builder.getOrCreate()のインスタンスをインスタンス化する必要があります。 -
ノートブックを実行するには、[ 実行] > [すべてのセル を実行] をクリックします。
-
ノートブックをデバッグするには、ノートブックのツールバーで Python 3 (ipykernel) の横にあるバグ ( Enable Debugger ) アイコンをクリックします。1 つ以上のブレークポイントを設定し、[ 実行] > [すべてのセルを実行] をクリックします。
-
JupyterLab をシャットダウンするには、[ ファイル] > [シャットダウン] をクリックします。 JupyterLab プロセスがまだターミナルまたはコマンド プロンプトで実行されている場合は、
Ctrl + cキーを押してからyと入力して、このプロセスを停止します。
より具体的なデバッグ手順については、「 デバッガー」を参照してください。
Classic Jupyter ノートブック
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect の構成スクリプトは、パッケージをプロジェクト構成に自動的に追加します。 Python カーネルで開始するには、次のコマンドを実行します。
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
SQL クエリの実行と視覚化の %sql 短縮形を有効にするには、次のスニペットを使用します。
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
ビジュアルスタジオコード
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を Visual Studio Code と共に使用するには、次の操作を行います。
-
Python 拡張機能がインストールされていることを確認します。
-
コマンド パレットを開きます (macOS では コマンド+Shift+P 、Windows/Linux では Ctrl+Shift+P)。
-
Python インタープリターを選択します。 [Code > [Preferences] > [Settings ] に移動し、[ Python settings ] を選択します。
-
databricks-connect get-jar-dirを実行します。 -
コマンドから返されたディレクトリを User Settings JSON の
python.venvPathに追加します。 これは Python 設定に追加する必要があります。 -
リンターを無効にします。 右側の [...] をクリックし 、 JSON 設定を編集します 。 変更された設定は次のとおりです。
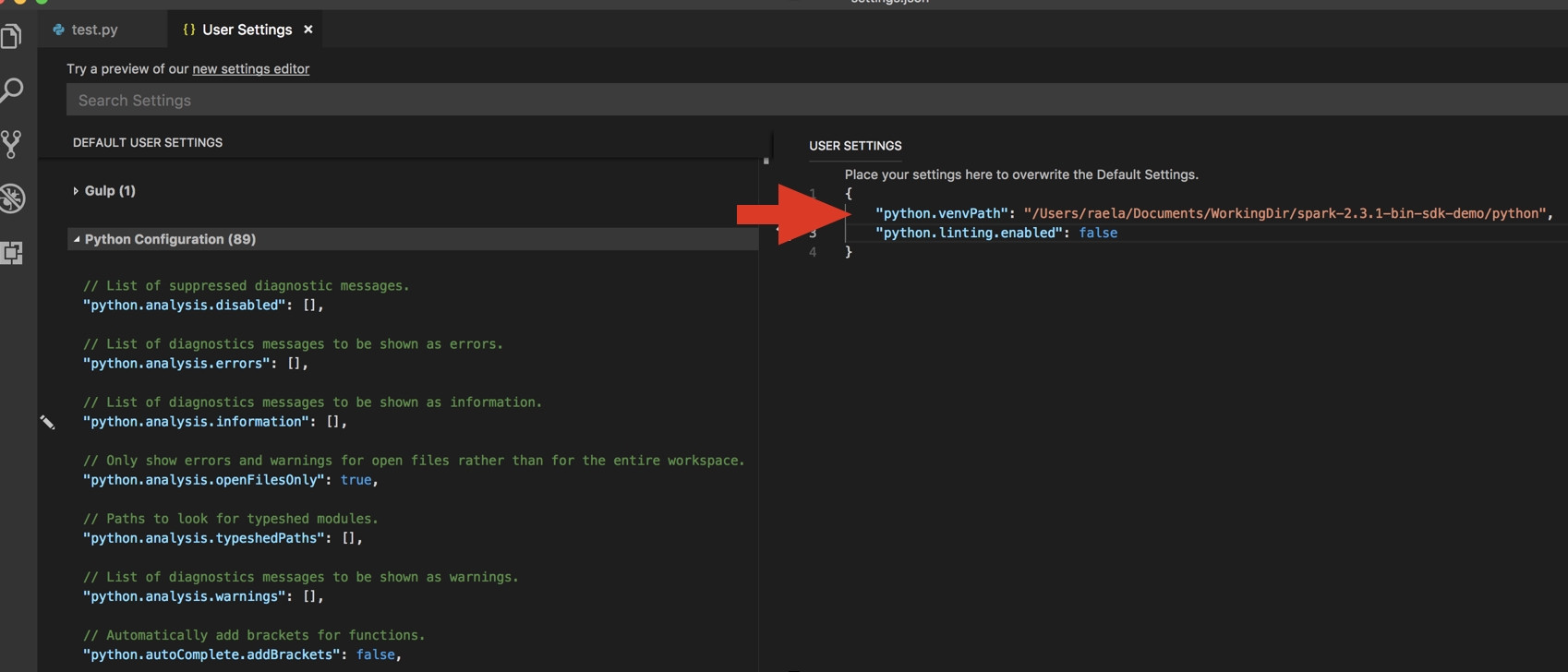
-
仮想環境で実行している場合Python (VS Code で を開発するための推奨される方法) は、コマンド パレットに「
select python interpreter」と入力し、クラスターPython のバージョン に一致する 環境をポイントします。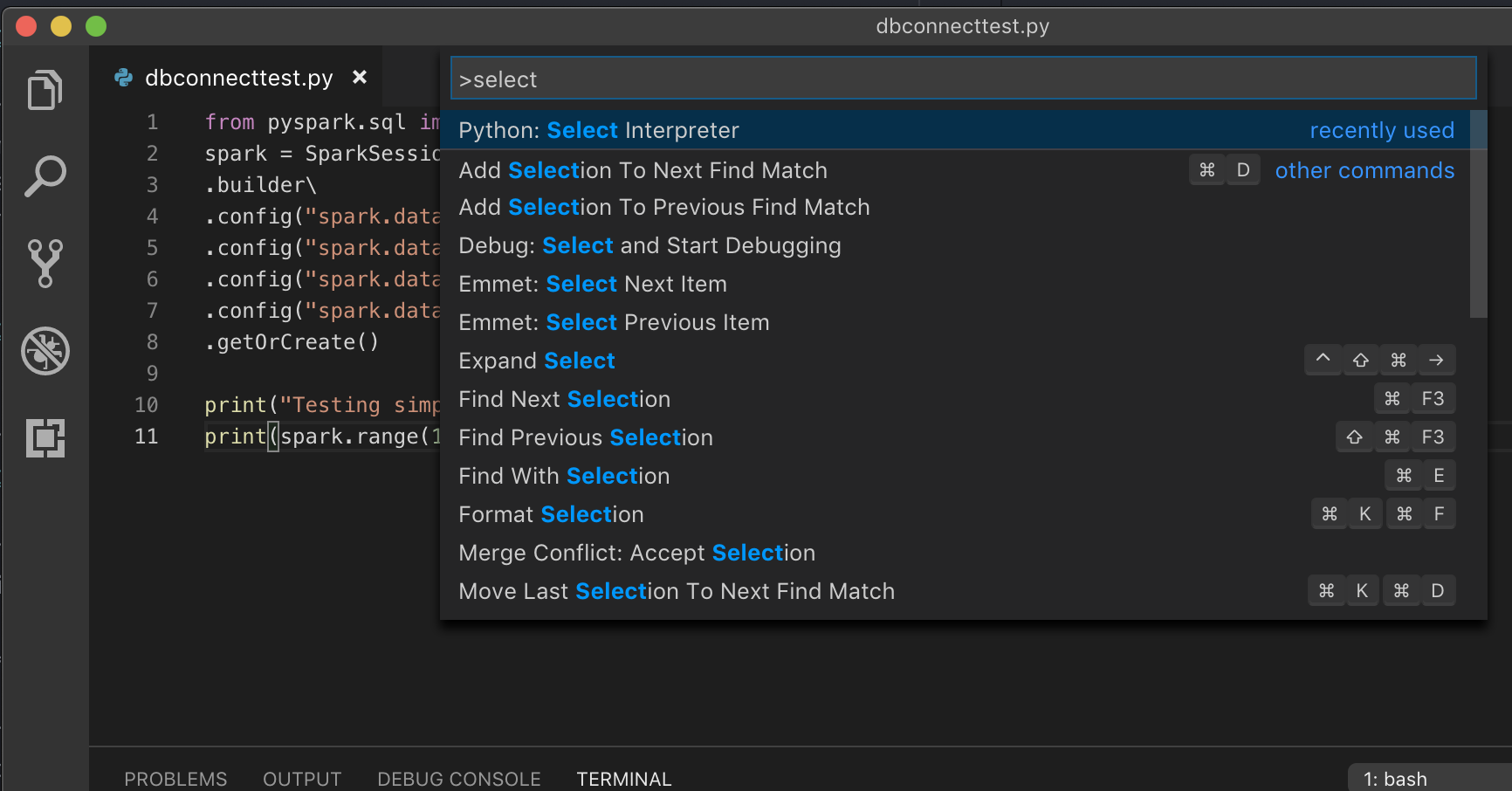
たとえば、クラスターが 3.9 Python の場合、開発環境は 3.9 Python 必要があります。
PyCharm
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect の構成スクリプトは、パッケージをプロジェクト構成に自動的に追加します。
Python 3 クラスター
-
PyCharm プロジェクトを作成するときは、 既存のインタープリター を選択します。 ドロップダウンメニューから、作成したConda環境を選択します( 要件を参照)。
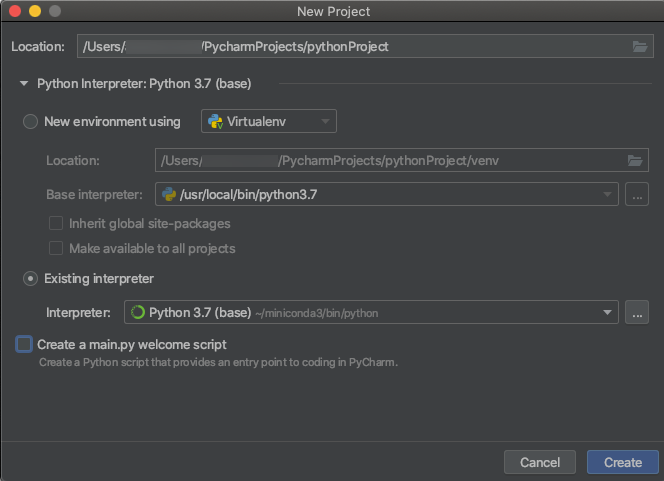
-
「設定の実行>編集 」に移動します。
-
環境変数として
PYSPARK_PYTHON=python3を追加します。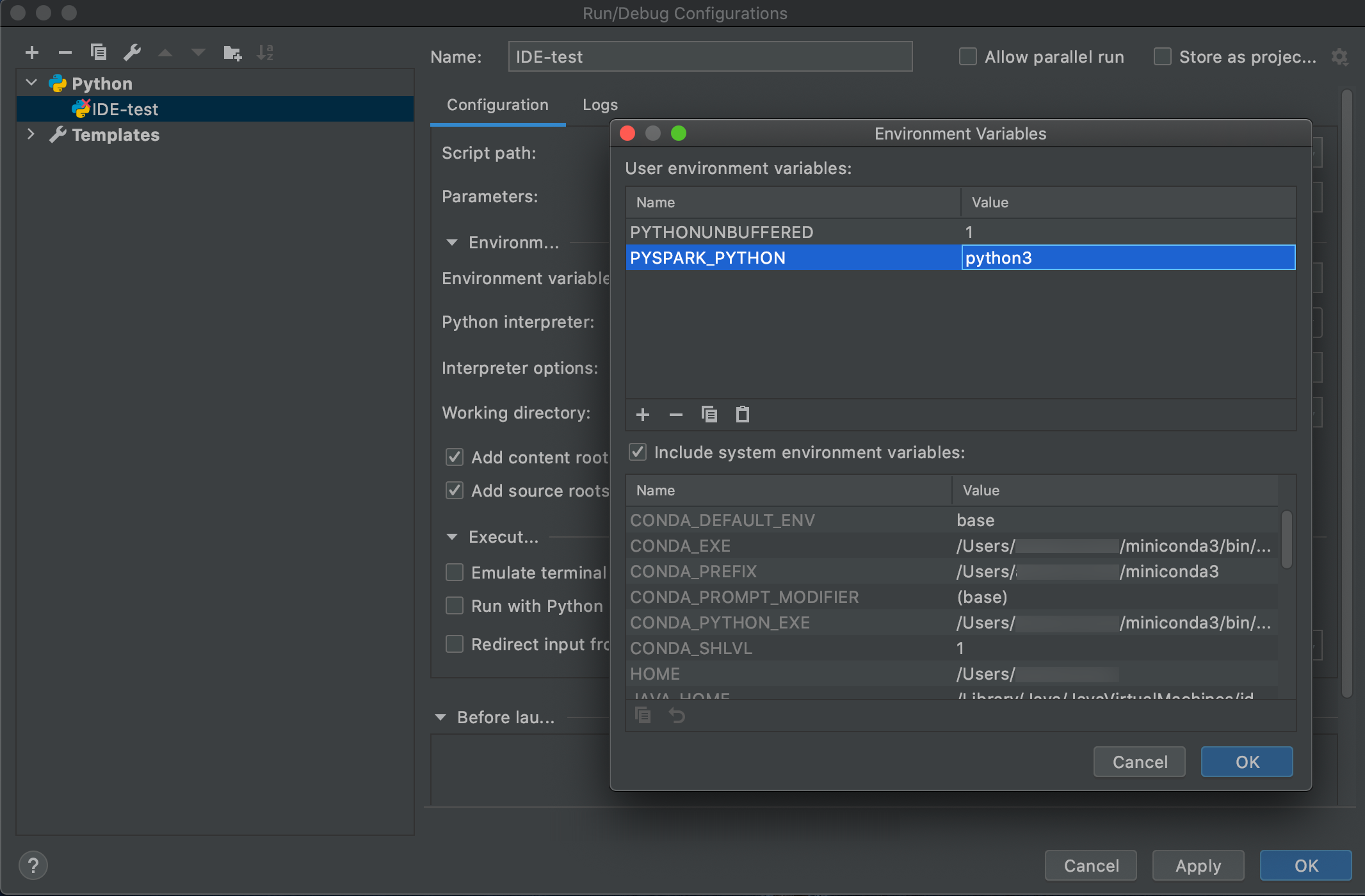
SparkR と RStudio デスクトップ
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を SparkR および RStudio Desktop と共に使用するには、次の操作を行います。
-
オープンソースの Spark ディストリビューションを開発マシンにダウンロードして解凍します。Databricksクラスター(Hadoop 2.7)と同じバージョンを選択します。
-
databricks-connect get-jar-dirを実行します。このコマンドは、/usr/local/lib/python3.5/dist-packages/pyspark/jarsのようなパスを返します。 JAR ディレクトリのファイルパス の上の 1 つのディレクトリ のファイルパス (/usr/local/lib/python3.5/dist-packages/pysparkなど) (SPARK_HOMEディレクトリ) をコピーします。 -
Spark の lib パスと Spark ホームを R スクリプトの先頭に追加して構成します。
<spark-lib-path>を、手順 1 でオープンソース Spark パッケージを解凍したディレクトリに設定します。<spark-home-path>をステップ 2 の Databricks Connect ディレクトリに設定します。R# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7
library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths())))
# Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark
Sys.setenv(SPARK_HOME = "<spark-home-path>") -
Spark セッションを開始し、SparkR コマンドの実行を開始します。
RsparkR.session()
df <- as.DataFrame(faithful)
head(df)
df1 <- dapply(df, function(x) { x }, schema(df))
collect(df1)
Sparklyrおよび RStudio デスクトップ
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
プレビュー
この機能は パブリック プレビュー段階です。
Databricks Connect を使用してローカルで開発した sparklyr に依存するコードをコピーし、Databricks ノートブックまたは Databricks ワークスペースでホストされている RStudio サーバーで、コードの変更を最小限に抑えるか、まったく行わずに実行できます。
このセクションの内容:
必要条件
- sparklyr 1.2以上。
- Databricks Runtime 7.3 LTS 以降と対応するバージョンの Databricks Connect。
Sparklyr のインストール、構成、使用
-
RStudio Desktop で、CRAN から Sparklyr 1.2 以降をインストールするか、GitHubから最新のマスター バージョンをインストールします。
R# Install from CRAN
install.packages("sparklyr")
# Or install the latest master version from GitHub
install.packages("devtools")
devtools::install_github("sparklyr/sparklyr") -
正しいバージョンの Databricks Connect がインストールされた状態で Python 環境をアクティブ化し、ターミナルで次のコマンドを実行して
<spark-home-path>を取得します。Bashdatabricks-connect get-spark-home -
Sparkセッションを開始し、Sparklyr コマンドの実行を開始します。
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
iris_tbl <- copy_to(sc, iris, overwrite = TRUE)
library(dplyr)
src_tbls(sc)
iris_tbl %>% count -
接続を閉じます。
Rspark_disconnect(sc)
リソース
詳細については、Sparklyr GitHub の README を参照してください。
コード例については、「 Sparklyr」を参照してください。
Sparklyr と RStudio Desktop の制限
次の機能はサポートされていません。
- sparklyr ストリーミング API
- sparklyr 機械学習 API
- ほうき API
- csv_file シリアル化モード
- Spark Submit
IntelliJ (Scala または Java)
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を IntelliJ (Scala または Java) と共に使用するには、次の操作を行います。
-
databricks-connect get-jar-dirを実行します。 -
依存関係を、コマンドから返されたディレクトリにポイントします。 「File」>「Project Structure」>「Modules」>依存関係に移動し、「+」記号>JARまたはディレクトリ> 。
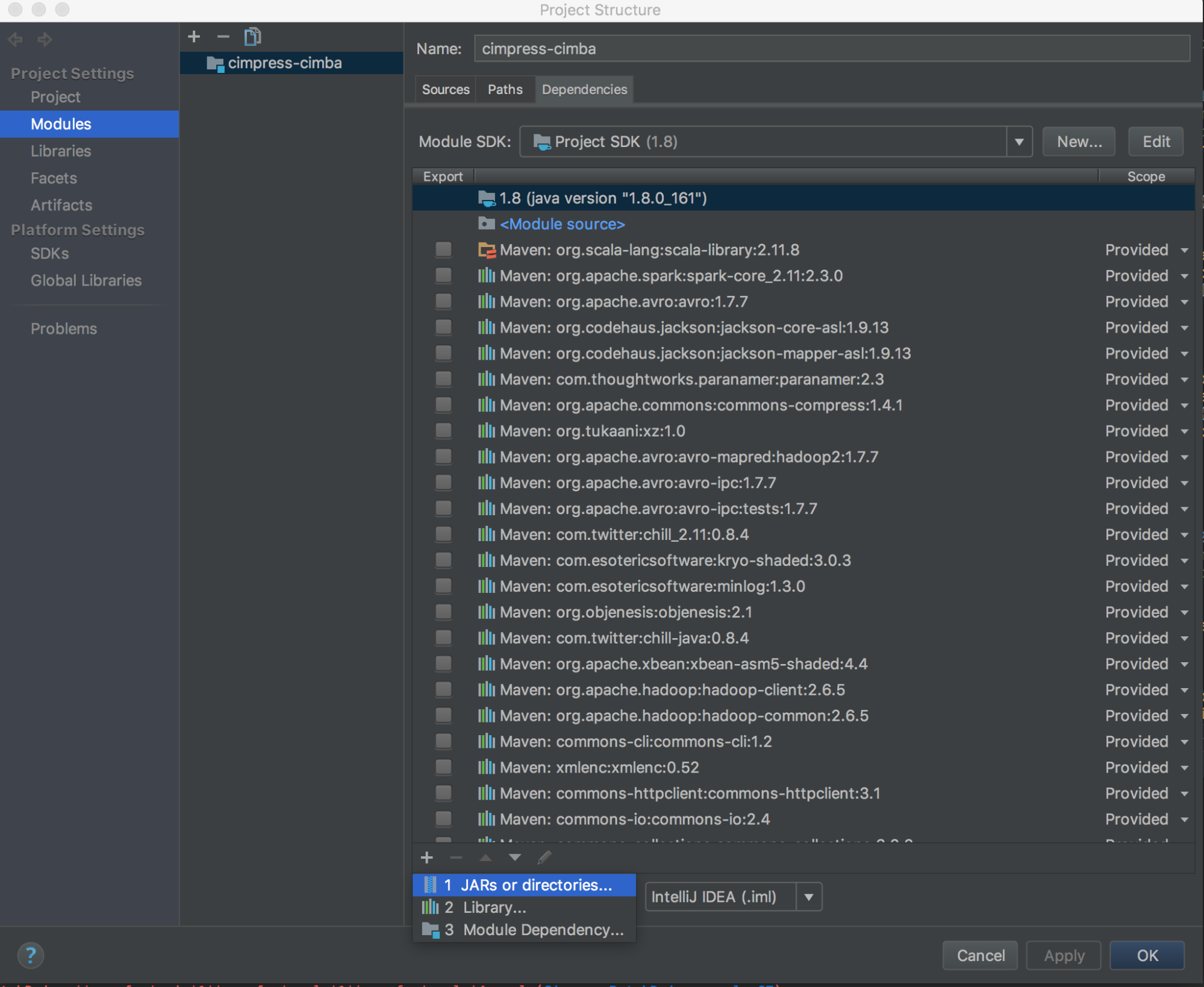
競合を避けるために、クラスパスから他の Spark インストールを削除することを強くお勧めします。 これが不可能な場合は、追加する JAR がクラスパスの先頭にあることを確認してください。 特に、インストールされている他のバージョンの Spark よりも進んでいる必要があります (そうでない場合は、他の Spark バージョンのいずれかを使用してローカルで実行するか、
ClassDefNotFoundErrorをスローします)。 -
IntelliJのブレークアウトオプションの設定を確認してください。 デフォルトは [すべて ] で、デバッグ用にブレークポイントを設定すると、ネットワークタイムアウトが発生します。 バックグラウンドネットワークスレッドが停止しないように 、Thread に設定します。

PyDevとEclipseの組み合わせ
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect と PyDev を Eclipse と共に使用するには、こちらの手順に従ってください。
- Eclipseを起動します。
- プロジェクトの作成: 「File」>「New > Project」>「PyDev Project」>「PyDev Project 」をクリックし、「 Next 」をクリックします。
- プロジェクト名 を指定します。
- [Project contents ] で、Python 仮想環境へのパスを指定します。
- 続ける前に通訳を設定してください。をクリックしてください。
- [手動設定 ] をクリックします。
- [新規] をクリックして> Python/pypy exe を参照します 。
- 仮想環境から参照される Python インタープリターへの絶対パスを参照して選択し、[ 開く ] をクリックします。
- 「インタープリターを選択 」ダイアログで、「 OK」 をクリックします。
- 「 必要な選択 」ダイアログで、「 OK」 をクリックします。
- 「プリファレンス 」ダイアログで、「 適用して閉じる 」をクリックします。
- 「PyDev プロジェクト 」ダイアログで、「 完了」 をクリックします。
- 「パースペクティブを開く」 をクリックします。
- サンプルコードまたは独自のコードを含む Python コード (
.py) ファイルをプロジェクトに追加します。独自のコードを使用する場合は、少なくとも、サンプルコードに示すように、SparkSession.builder.getOrCreate()のインスタンスをインスタンス化する必要があります。 - Python コード ファイルを開いた状態で、実行中にコードを一時停止する場所にブレークポイントを設定します。
- 「実行」>「実行 」または 「デバッグ>実行 」をクリックします。
実行とデバッグの具体的な手順については 、「プログラムの実行」を参照してください。
Eclipse
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect と Eclipse を使用するには、次の操作を行います。
-
databricks-connect get-jar-dirを実行します。 -
外部JAR構成を、コマンドから返されたディレクトリにポイントします。 「プロジェクト」メニュー>「プロパティ」>「Java ビルドパス」>「ライブラリ」>「外部 jar ファイルの追加 」に移動します。
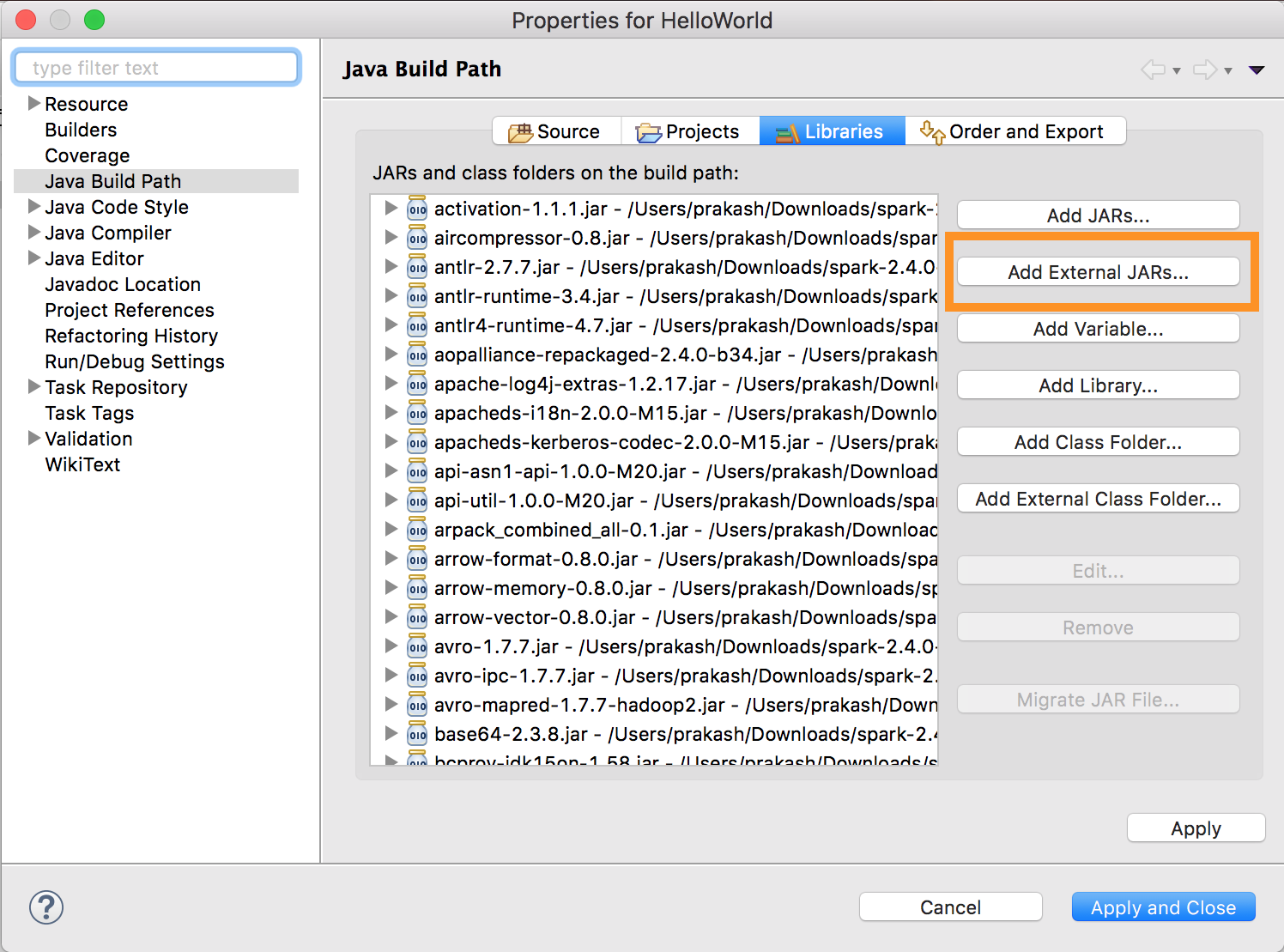
競合を避けるために、クラスパスから他の Spark インストールを削除することを強くお勧めします。 これが不可能な場合は、追加する JAR がクラスパスの先頭にあることを確認してください。 特に、インストールされている他のバージョンの Spark よりも進んでいる必要があります (そうでない場合は、他の Spark バージョンのいずれかを使用してローカルで実行するか、
ClassDefNotFoundErrorをスローします)。
SBTの
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を SBT と共に使用するには、通常の Spark ライブラリの依存関係ではなく、Databricks Connect JAR に対してリンクするように build.sbt ファイルを構成する必要があります。 これは、次のビルド ファイルの例では unmanagedBase ディレクティブを使用して行います。これは、 com.example.Test メイン オブジェクトを持つ Scala アプリを想定しています。
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark シェル
Databricks Connect の使用を開始する前に、 要件を満たし 、Databricks Connect の クライアントを設定する必要があります 。
Databricks Connect を Spark シェルと Python または Scala と共に使用するには、こちらの手順に従ってください。
-
仮想環境をアクティブ化した状態で、クライアントのセットアップで
databricks-connect testコマンドが正常に実行されたことを確認します。 -
仮想環境をアクティブ化した状態で、Spark シェルを起動します。 Python の場合は、
pysparkコマンドを実行します。 Scala の場合は、spark-shellコマンドを実行します。Bash# For Python:
pysparkBash# For Scala:
spark-shell -
Spark シェルが表示されます (Python など)。
Python 3... (v3...)
[Clang 6... (clang-6...)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3....
/_/
Using Python version 3... (v3...)
Spark context Web UI available at http://...:...
Spark context available as 'sc' (master = local[*], app id = local-...).
SparkSession available as 'spark'.
>>>Scala の場合:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://...
Spark context available as 'sc' (master = local[*], app id = local-...).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3...
/_/
Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...)
Type in expressions to have them evaluated.
Type :help for more information.
scala> -
SparkSparkシェルをPython またはScala とともに使用してクラスターでコマンドを実行する方法については、「 シェルを使用した対話型解析 」をご参照ください。
組み込み
spark変数を使用して、稼働中のクラスターのSparkSessionを表します (例: Pythonの場合>>> df = spark.read.table("samples.nyctaxi.trips")
>>> df.show(5)
+--------------------+---------------------+-------------+-----------+----------+-----------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|
+--------------------+---------------------+-------------+-----------+----------+-----------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282|
+--------------------+---------------------+-------------+-----------+----------+-----------+
only showing top 5 rowsScala の場合:
>>> val df = spark.read.table("samples.nyctaxi.trips")
>>> df.show(5)
+--------------------+---------------------+-------------+-----------+----------+-----------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|
+--------------------+---------------------+-------------+-----------+----------+-----------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282|
+--------------------+---------------------+-------------+-----------+----------+-----------+
only showing top 5 rows -
Spark シェルを停止するには、
Ctrl + dまたはCtrl + zを押すか、Python の場合はquit()またはexit()、Scala の場合は:qまたは:quitコマンドを実行します。
コード例
この単純なコード例では、指定したテーブルに対してクエリを実行し、指定したテーブルの最初の 5 行を表示します。別のテーブルを使用するには、呼び出しを spark.read.tableに調整します。
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
この長いコード例では、次のことを行います。
- インメモリ データフレーム を作成します。
defaultスキーマ内にzzz_demo_temps_tableという名前のテーブルを作成します。この名前のテーブルがすでに存在する場合は、最初にテーブルが削除されます。 別のスキーマまたはテーブルを使用するには、呼び出しをspark.sql、temps.write.saveAsTable、またはその両方に調整します。- DataFrame の内容をテーブルに保存します。
- テーブルの内容に対して
SELECTクエリを実行します。 - クエリの結果が表示されます。
- テーブルを削除します。
- Python
- Scala
- Java
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
依存関係を扱う
通常、メインクラスまたはPythonファイルには、他の依存関係JARとファイルがあります。 このような依存関係 JAR とファイルを追加するには、 sparkContext.addJar("path-to-the-jar") または sparkContext.addPyFile("path-to-the-file")を呼び出します。 addPyFile()インターフェースを使用して、Eggファイルやzipファイルを追加することもできます。IDE でコードを実行するたびに、依存関係 JAR とファイルがクラスターにインストールされます。
- Python
- Scala
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDFs
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Databricks ユーティリティへのアクセス
このセクションでは、Databricks Connect を使用して Databricks ユーティリティにアクセスする方法について説明します。
Databricksユーティリティ(dbutils)リファレンスモジュールのdbutils.fsユーティリティとdbutils.secretsユーティリティを使用できます。サポートされているコマンドは、 dbutils.fs.cp、 dbutils.fs.head、 dbutils.fs.ls、 dbutils.fs.mkdirs、 dbutils.fs.mv、 dbutils.fs.put、 dbutils.fs.rm、 dbutils.secrets.get、 dbutils.secrets.getBytes、 dbutils.secrets.list、 dbutils.secrets.listScopesです。ファイル・システム・ユーティリティ (dbutils.fs)を参照してください。 または、 dbutils.fs.help() と シークレット・ユーティリティ (dbutils.secrets) を実行します。 または、 dbutils.secrets.help()を実行します。
- Python
- Scala
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Databricks Runtime 7.3 LTS 以降を使用している場合、ローカルとDatabricksクラスターの両方で機能する方法で DBUtils モジュールにアクセスするには、次のget_dbutils()を使用します。
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
それ以外の場合は、次の get_dbutils()を使用します。
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
ローカルとリモートのファイルシステムの間でのファイルのコピー
dbutils.fs を使用して、クライアントとリモート・ファイル・システム間でファイルをコピーできます。スキーム file:/ は、クライアント上のローカルファイルシステムを参照します。
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
その方法で転送できる最大ファイルサイズは250 MBです。
エネーブル dbutils.secrets.get
セキュリティ上の制限により、 dbutils.secrets.get を呼び出す機能はデフォルトで無効になっています。 Databricks サポートに連絡して、ワークスペースでこの機能を有効にしてください。
Hadoop 構成の設定
クライアントでは、SQL および データフレーム 操作に適用される spark.conf.set API を使用して Hadoop 構成を設定できます。 sparkContextに設定するHadoop設定は、クラスター設定で設定するか、ノートブックを使用して設定する必要があります。これは、 sparkContext に設定された構成がユーザー セッションに関連付けられず、クラスター全体に適用されるためです。
トラブルシューティング
databricks-connect testを実行して、接続の問題を確認します。このセクションでは、Databricks Connect で発生する可能性のある一般的な問題とその解決方法について説明します。
このセクションの内容:
- Python のバージョンが一致しません
- サーバーが有効になっていない
- PySpark インストールの競合
- 競合
SPARK_HOME - バイナリの
PATHエントリが競合または欠落している - クラスターのシリアル化設定の競合
- Windowsで
winutils.exeが見つかりません - Windows でファイル名、ディレクトリ名、またはボリューム ラベルの構文が正しくありません
Python のバージョンが一致しません
ローカルで使用している Python バージョンに、クラスターのバージョンと少なくとも同じマイナーリリースがあることを確認します(たとえば、3.9.16対3.9.15は問題ありませんが、3.9対3.8はそうではありません)。
複数の Python バージョンがローカルにインストールされている場合は、 PYSPARK_PYTHON 環境変数 ( PYSPARK_PYTHON=python3など) を設定して、Databricks Connect が正しいバージョンを使用していることを確認します。
サーバーが有効になっていない
クラスターで Spark サーバーが spark.databricks.service.server.enabled true で有効になっていることを確認します。 次の行である場合は、ドライバー ログに次の行が表示されます。
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
PySpark インストールの競合
databricks-connectパッケージがPySparkと競合しています。両方をインストールすると、Python で Spark コンテキストを初期化するときにエラーが発生します。 これは、「ストリームが破損しています」や「クラスが見つかりません」というエラーなど、いくつかの形で現れる可能性があります。 Python 環境に PySpark がインストールされている場合は、databricks-connect をインストールする前に、PySpark がアンインストールされていることを確認してください。 PySpark をアンインストールした後、Databricks Connect パッケージを完全に再インストールしてください。
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
矛盾しています SPARK_HOME
以前にマシンで Spark を使用したことがある場合、IDE は Databricks Connect Spark ではなく、他のバージョンの Spark のいずれかを使用するように構成されている可能性があります。 これは、「ストリームが破損しています」や「クラスが見つかりません」というエラーなど、いくつかの形で現れる可能性があります。 どのバージョンの Spark が使用されているかは、 SPARK_HOME 環境変数の値を確認することで確認できます。
- Python
- Scala
- Java
import os
print(os.environ['SPARK_HOME'])
println(sys.env.get("SPARK_HOME"))
System.out.println(System.getenv("SPARK_HOME"));
解決
SPARK_HOME がクライアント内のバージョン以外の Spark に設定されている場合は、SPARK_HOME 変数の設定を解除して再試行する必要があります。
IDE 環境変数の設定、 .bashrc、 .zshrc、 .bash_profile ファイル、および環境変数が設定されている可能性のある場所を確認してください。 ほとんどの場合、古い状態をパージするにはIDEを終了して再起動する必要があり、問題が解決しない場合は新しいプロジェクトを作成する必要があるかもしれません。
SPARK_HOME を新しい値に設定する必要はありません。設定を解除すれば十分です。
バイナリの PATH エントリが競合または欠落している
PATH は、 spark-shell のようなコマンドが、Databricks Connect で提供されるバイナリではなく、以前にインストールされた他のバイナリを実行するように構成されている可能性があります。 これにより、 databricks-connect test が失敗する可能性があります。 Databricks Connect バイナリが優先されるか、以前にインストールされたバイナリを削除する必要があります。
spark-shellのようなコマンドを実行できない場合は、PATHがpip3 installによって自動的に設定されていない可能性もあり、インストールbindirをPATHに手動で追加する必要があります。Databricks ConnectIDEsで を使用することは可能です。これは設定されていません。ただし、 databricks-connect test コマンドは機能しません。
クラスターのシリアル化設定の競合
databricks-connect testの実行時に「ストリームが破損しています」エラーが表示される場合は、互換性のないクラスターシリアル化構成が原因である可能性があります。たとえば、 spark.io.compression.codec 設定を設定すると、この問題が発生する可能性があります。 この問題を解決するには、クラスター設定からこれらの構成を削除するか、 Databricks Connect クライアントで構成を設定することを検討してください。
Windowsで winutils.exe が見つかりません
Windows で Databricks Connect を使用していて、次の情報が表示される場合:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
指示に従って 、Windows で Hadoop パスを設定します。
Windows でファイル名、ディレクトリ名、またはボリューム ラベルの構文が正しくありません
Windows と Databricks Connect を使用していて、次の情報が表示される場合:
The filename, directory name, or volume label syntax is incorrect.
Java または Databricks Connect が 、パスにスペースがあるディレクトリにインストールされました。 これを回避するには、スペースを含まないディレクトリパスにインストールするか、 短い名前の形式を使用してパスを設定します。
制限
-
構造化ストリーミング。
-
Sparkジョブの一部ではない任意のコードをリモートクラスターで実行しています。
-
ScalaPythonAPIDeltaテーブル操作 (
DeltaTable.forPathなど) のネイティブ 、 、および R はサポートされていません。ただし、Delta Lake 操作での SQL API (spark.sql(...)) と、Delta テーブルでの Spark API (spark.read.loadなど) はどちらもサポートされています。 -
コピー先。
-
SQL 関数を使用して、サーバーのカタログの一部である Python または Scala UDFs。ただし、ローカルで導入された Scala と Python の UDF は機能します。
-
Apache Zeppelin 0.7.x およびそれ以下。
-
プロセス分離が有効になっている (つまり、
spark.databricks.pyspark.enableProcessIsolationがtrueに設定されている) クラスターへの接続。 -
Delta
CLONESQL コマンド。 -
グローバル一時ビュー。
-
Koalasと
pyspark.pandas。 -
CREATE TABLE table AS SELECT ...SQL コマンドが常に機能するとは限りません。 代わりに、spark.sql("SELECT ...").write.saveAsTable("table").