パフォーマンスの評価: 注意すべきメトリクス
この記事では、RAGアプリケーションのパフォーマンスの測定について、取得、応答、およびシステムパフォーマンスの品質について説明します。
取得、応答、およびパフォーマンス
評価セットを使用すると、次のようなさまざまな次元でRAGアプリケーションのパフォーマンスを測定できます。
- 検索品質: 検索 メトリクスは、RAGアプリケーションが関連するサポートデータをどの程度正常に取得しているかを評価します。 精度と再現率は、2 つの主要な検索メトリクスです。
- 応答品質: 応答品質メトリクスは、RAGアプリケーションがユーザーのリクエストにどの程度適切に応答しているかを評価します。レスポンスメトリクスは、例えば、結果として得られる回答がグラウンドトゥルースに従って正確であるかどうか、取得したコンテキストに対してレスポンスがどの程度根拠のあるものであったか(例えば、LLMは幻覚を見たか)、またはレスポンスがどれほど安全であったか(つまり、毒性がなかったか)を測定できます。
- システムパフォーマンス(コストとレイテンシ): メトリクスは、RAGアプリケーションの全体的なコストとパフォーマンスをキャプチャします。 全体的なレイテンシとトークンの消費量は、チェーンのパフォーマンスメトリクスの例です。
レスポンスと取得の両方のメトリクスを収集することは非常に重要です。 RAGアプリケーションは、正しいコンテキストを取得しているにもかかわらず、応答が不十分な場合があります。また、誤った検索に基づいて適切な応答を提供することもできます。 両方のコンポーネントを測定することによってのみ、アプリケーションの問題を正確に診断し、対処することができます。
パフォーマンス測定のアプローチ
これらのメトリクス全体のパフォーマンスを測定するには、次の 2 つの主要なアプローチがあります。
- 決定論的測定: コストとレイテンシーのメトリクスは、アプリケーションの出力に基づいて決定論的に計算できます。 評価セットに、質問に対する回答を含むドキュメントのリストが含まれている場合、検索 メトリクスのサブセットも決定論的に計算できます。
- LLMジャッジベースの測定: このアプローチでは、別の LLMがジャッジとして機能し 、RAGアプリケーションの取得とレスポンスの品質を評価します。回答の正しさなど、一部のLLMジャッジは、人間がラベル付けしたグラウンドトゥルースとアプリの出力を比較します。グラウンディングネスなどの他のLLMジャッジは、アプリの出力を評価するために人間がラベル付けしたグラウンドトゥルースを必要としません。
LLMジャッジが効果的であるためには、ユースケースを理解するように調整する必要があります。 そのためには、ジャッジがどこでうまく機能し、どこでうまく機能しないかを理解するために細心の注意を払う必要があります。そして、失敗の場合には、ジャッジを調整して改善する必要があります。
Mosaic AI Agent Evaluation は、このページで説明する各メトリクスに対して、ホストされた LLM ジャッジモデルを使用して、すぐに使用できる実装を提供します。Agent Evaluation のドキュメントでは、これらのメトリクスとジャッジの実装方法の詳細について説明し、ジャッジをデータに合わせて調整して精度を向上させる機能を提供します
メトリクスの概要
以下は、DatabricksがRAGアプリケーションの品質、コスト、レイテンシを測定するために推奨するメトリクスの概要です。 これらのメトリクスは、Mosaic AI エージェント評価に実装されます。
次元 | メトリクス名 | 質問 | 測定者 | グラウンドトゥルースが必要ですか? |
|---|---|---|---|---|
検索 | chunk_relevance/precision | LLMジャッジ | いいえ | |
検索 | document_recall | 取得したチャンクには、グラウンドトゥルース文書の何パーセントが表されていますか? | 確定的 | あり |
検索 | context_sufficiency | LLMジャッジ | あり | |
レスポンス | correctness | LLMジャッジ | あり | |
レスポンス | relevance_to_query | LLMジャッジ | いいえ | |
レスポンス | groundedness | LLMジャッジ | いいえ | |
レスポンス | safety | LLMジャッジ | いいえ | |
コスト | total_token_count、total_input_token_count、total_output_token_count | 確定的 | いいえ | |
レイテンシー | latency_seconds | 確定的 | いいえ |
取得メトリクスの仕組み
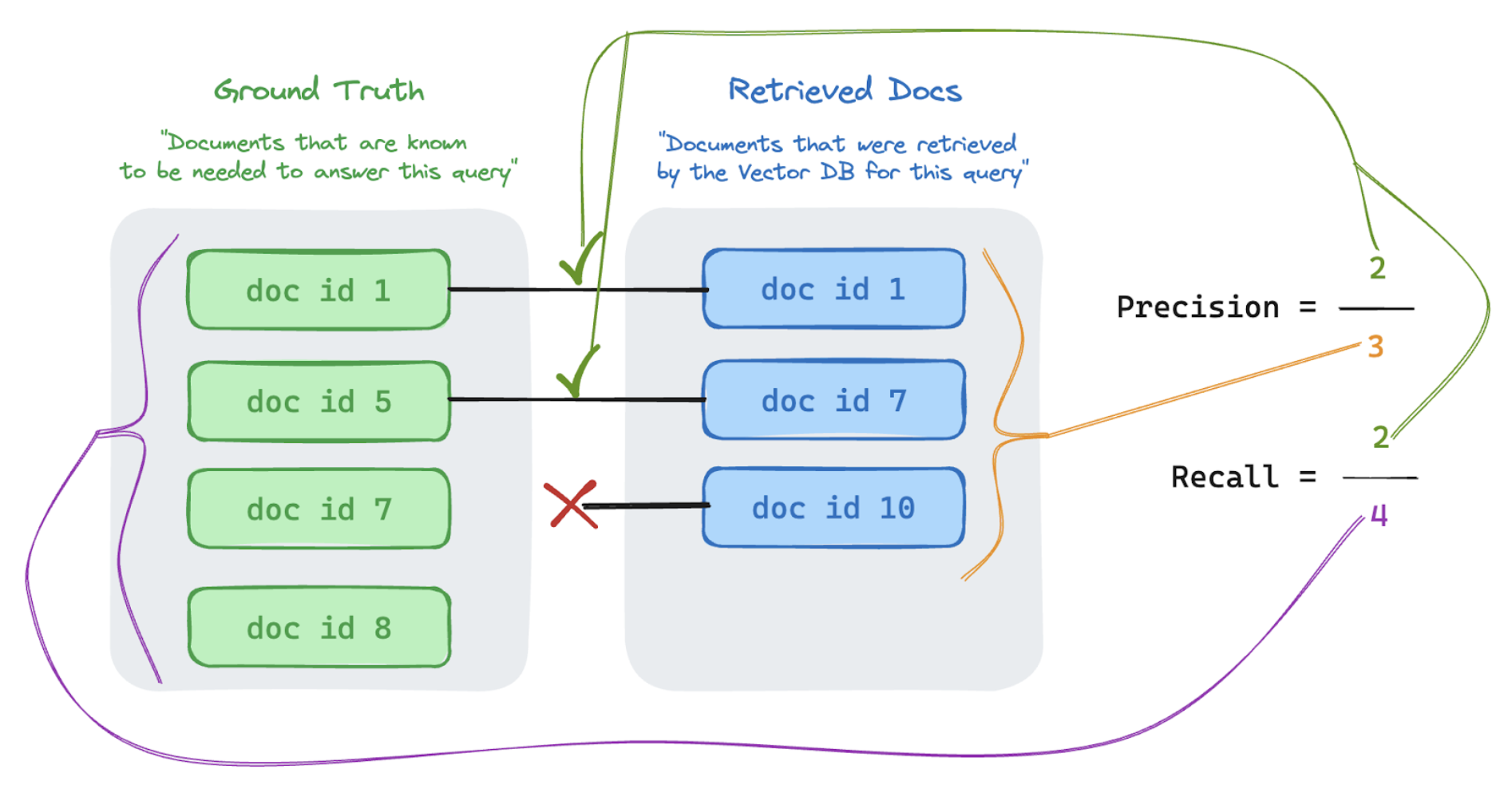
取得メトリクスは、レトリーバーが適切な結果を提供しているかどうかを理解するのに役立ちます。 取得メトリクスは、精度と再現率に基づいています。
メトリクス名 | 質問回答 | 詳細 |
|---|---|---|
Precision | 取得したチャンクの何%がリクエストに関連していますか? | 精度は、ユーザーの要求に実際に関連する取得されたドキュメントの割合です。LLM ジャッジを使用して、取得した各チャンクとユーザーの要求との関連性を評価できます。 |
Recall | 取得したチャンクには、グラウンドトゥルース文書の何パーセントが表されていますか? | リコールは、取得したチャンクで表されるグラウンドトゥルースドキュメントの割合です。 これは、結果の完全性の尺度です。 |
精度と再現率
以下は、 優れたウィキペディアの記事から適応された精度と想起に関する簡単な入門書です。
精度の式
精度は、「取得したチャンクのうち、これらのアイテムの何パーセントが実際にユーザーのクエリに関連しているか」を測定します。精度を計算するために、 関連するすべての 項目を知る 必要はありません 。
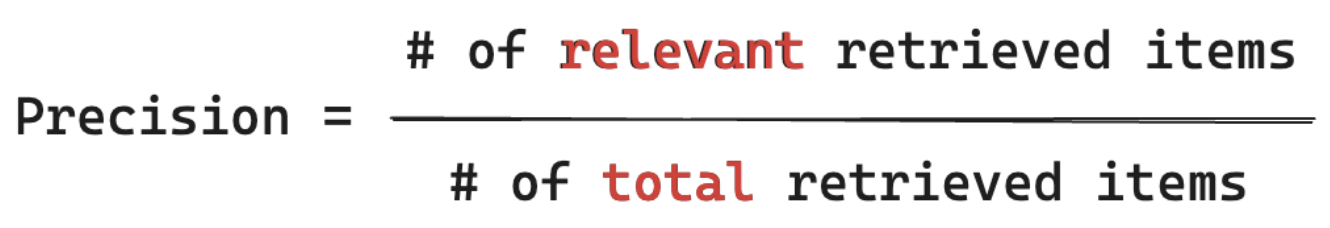
リコール式
リコールは、「ユーザーのクエリに関連することがわかっているすべてのドキュメントのうち、チャンクを何%取得しましたか?」を測定します。リコールの計算には、 すべての 関連アイテムが含まれているグラウンドトゥルースが必要です。アイテムは、ドキュメントまたはドキュメントのチャンクのいずれかです。
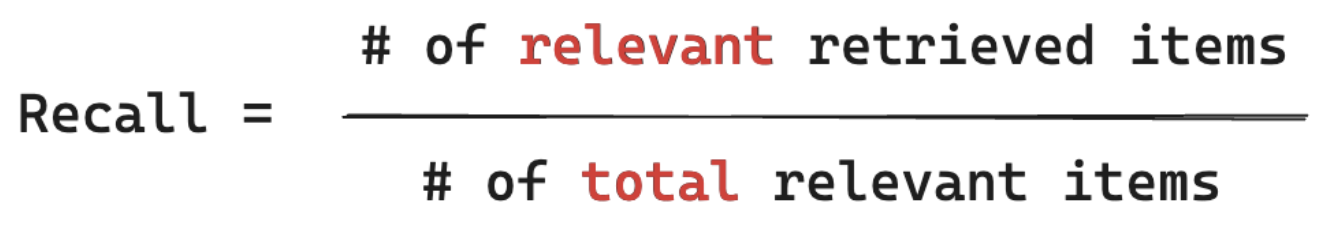
次の例では、取得した 3 つの結果のうち 2 つがユーザーのクエリに関連していたため、精度は 0.66 (2/3) でした。回収された文書には、合計4つの関連文書のうち2つが含まれていたため、リコールは0.5(2/4)でした。