チュートリアル: ノートブックから CSV データをインポートして視覚化する
このチュートリアルでは、 Databricksノートブックを使用して、 health.data.ny.govの赤ちゃんの名前データを含むCSVファイルからPython 、 Scala 、および R を使用してUnity Catalogボリュームにデータをインポートする手順を説明します。 また、列名の変更、データの視覚化、テーブルへの保存についても学習します。
必要条件
この記事のタスクを完了するには、次の要件を満たす必要があります。
- ワークスペースで Unity Catalog が有効になっている必要があります。情報 Unity Catalog入門 、 Unity Catalog入門を参照してください。
- ボリュームに対する
WRITE VOLUME権限、親スキーマに対するUSE SCHEMA権限、および親カタログに対するUSE CATALOG権限が必要です。 - 既存のコンピュート リソースを使用するか、新しいコンピュート リソースを作成するには、権限が必要です。 「コンピューティング」を参照するか、 Databricks管理者に問い合わせてください。
この記事の完成したノートブックについては、「 データ ノートブックのインポートと視覚化」を参照してください。
ステップ 1: 新しいノートブックを作成する
ワークスペースにノートブックを作成するには、サイドバーの「![]() 新規 」をクリックし、「 ノートブック 」をクリックします。空白のノートブックがワークスペースで開きます。
新規 」をクリックし、「 ノートブック 」をクリックします。空白のノートブックがワークスペースで開きます。
ノートブックの作成と管理の詳細については、「 ノートブックの管理」を参照してください。
ステップ 2: 変数を定義する
この手順では、この記事で作成するサンプル ノートブックで使用する変数を定義します。
- 次のコードをコピーして、新しい空のノートブック セルに貼り付けます。
<catalog-name>、<schema-name>、および<volume-name>を、Unity Catalog ボリュームのカタログ、スキーマ、およびボリューム名に置き換えます。必要に応じて、table_name値を任意のテーブル名に置き換えます。 赤ちゃんの名前のデータは、この記事の後半でこのテーブルに保存します。 Shift+Enterを押すとセルが実行され、新しい空白のセルが作成されます。
- Python
- Scala
- R
catalog = "<catalog_name>"
schema = "<schema_name>"
volume = "<volume_name>"
download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name = "baby_names.csv"
table_name = "baby_names"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_table = catalog + "." + schema
print(path_table) # Show the complete path
print(path_volume) # Show the complete path
val catalog = "<catalog_name>"
val schema = "<schema_name>"
val volume = "<volume_name>"
val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
val fileName = "baby_names.csv"
val tableName = "baby_names"
val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}"
val pathTable = s"${catalog}.${schema}"
print(pathVolume) // Show the complete path
print(pathTable) // Show the complete path
catalog <- "<catalog_name>"
schema <- "<schema_name>"
volume <- "<volume_name>"
download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name <- "baby_names.csv"
table_name <- "baby_names"
path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "")
path_table <- paste(catalog, ".", schema, sep = "")
print(path_volume) # Show the complete path
print(path_table) # Show the complete path
ステップ3:CSVファイルをインポートする
このステップでは、 health.data.ny.gov から赤ちゃんの名前データを含む CSV ファイルを Unity Catalog ボリュームにインポートします。
- 次のコードをコピーして、新しい空のノートブック セルに貼り付けます。 このコードは、Databricks dbutuilsコマンドを使用して、health.data.ny.gov から Unity Catalog ボリュームに
rows.csvファイルをコピーします。 Shift+Enterを押してセルを実行し、次のセルに移動します。
- Python
- Scala
- R
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
ステップ 4: CSV データを データフレーム に読み込む
このステップでは、spark.read.csvメソッドを使用して、以前にUnity CatalogボリュームにロードしたCSVファイルからdfという名前のデータフレームを作成します。
- 次のコードをコピーして、新しい空のノートブックセルに貼り付けます。このコードは、CSVファイルからデータフレーム「
df」に赤ちゃんの名前データをロードします。 Shift+Enterを押してセルを実行し、次のセルに移動します。
- Python
- Scala
- R
df = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")
val df = spark.read
.option("header", "true")
.option("inferSchema", "true")
.option("delimiter", ",")
.csv(s"${pathVolume}/${fileName}")
# Load the SparkR package that is already preinstalled on the cluster.
library(SparkR)
df <- read.df(paste(path_volume, "/", file_name, sep=""),
source="csv",
header = TRUE,
inferSchema = TRUE,
delimiter = ",")
サポートされている多くのファイル形式からデータをロードできます。
ステップ 5: ノートブックからデータを視覚化する
このステップでは、display()メソッドを使用してデータフレームの内容をノートブックのテーブルに表示し、ノートブックのワードクラウドチャートでデータを可視化します。
- 次のコードをコピーして、新しい空のノートブックのセルに貼り付け、 [セルを実行] をクリックしてデータをテーブルに表示します。
- Python
- Scala
- R
display(df)
display(df)
display(df)
-
テーブルの結果を確認します。
-
テーブル タブの横にある + をクリックし、 ビジュアライゼーション をクリックします。
-
可視化エディタで、 [ビジュアライゼーションの種類] をクリックし、 [ワードクラウド] が選択されていることを確認します。
-
[単語列] で [
First Name] が選択されていることを確認します。 -
[頻度制限] で [
35] をクリックします。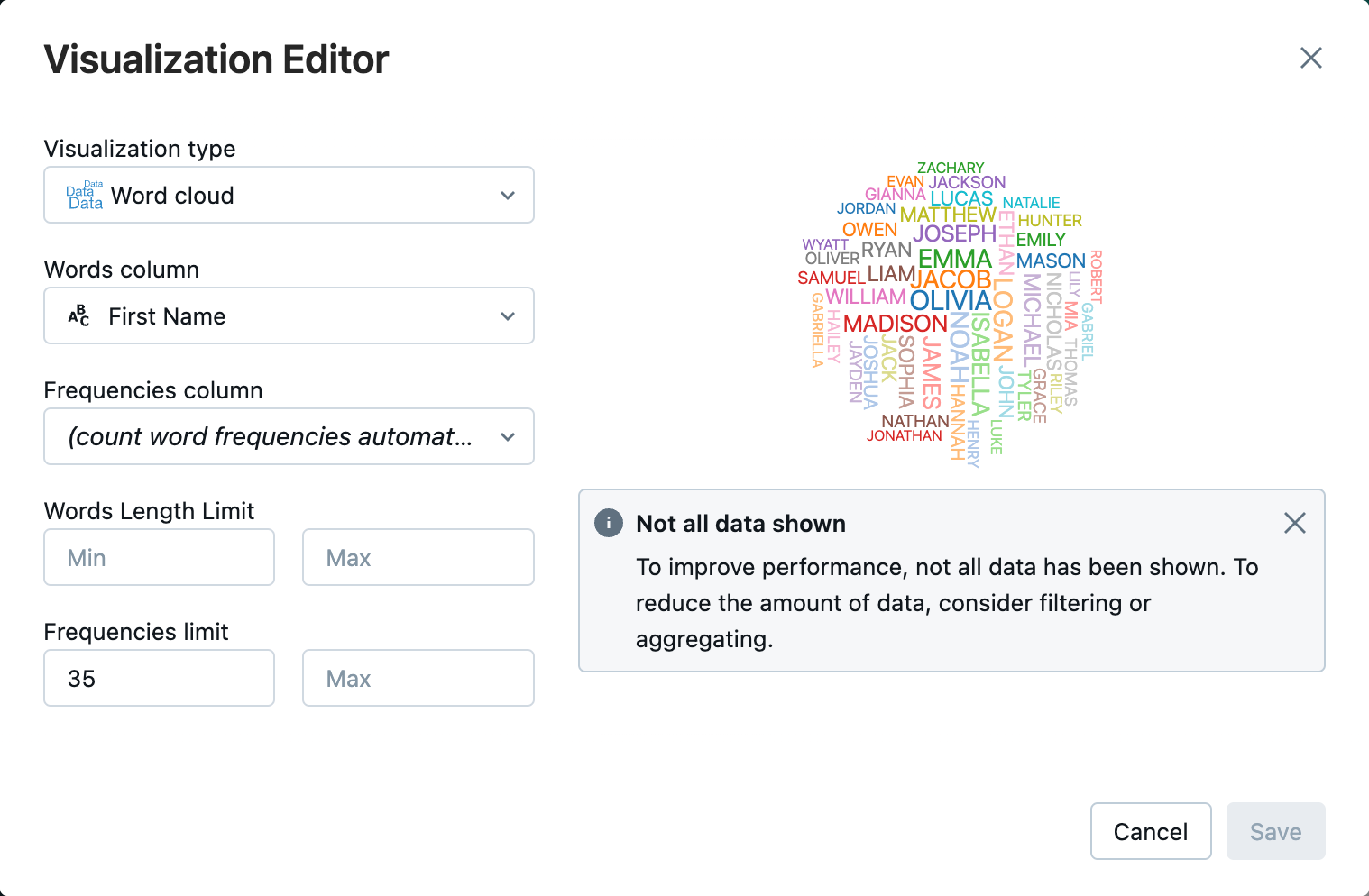
-
[ 保存 ]をクリックします。
ステップ 6: データフレーム をテーブルに保存する
データフレームを Unity Catalogに保存するには、カタログとスキーマに対する CREATE テーブル権限が必要です。Unity Catalogの権限については、Unity Catalogの権限とセキュリティ保護可能なオブジェクトおよびUnity Catalogの権限の管理を参照してください。
- 次のコードをコピーして、空のノートブック セルに貼り付けます。 このコードは、列名のスペースを置き換えます。 スペースなどの特殊文字は、列名には使用できません。このコードでは、Apache Spark
withColumnRenamed()メソッドを使用します。
- Python
- Scala
- R
df = df.withColumnRenamed("First Name", "First_Name")
df.printSchema
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name")
// when modifying a DataFrame in Scala, you must assign it to a new variable
dfRenamedColumn.printSchema()
df <- withColumnRenamed(df, "First Name", "First_Name")
printSchema(df)
- 次のコードをコピーして、ノートブックの空のセルに貼り付けます。このコードは、この記事の冒頭で定義したテーブル名変数を使用して、データフレームの内容をUnity Catalogのテーブルに保存します。
- Python
- Scala
- R
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")
-
テーブルが保存されたことを確認するには、左のサイドバーで [カタログ] をクリックして、カタログエクスプローラーUIを開きます。カタログを開き、スキーマを開いてテーブルが表示されていることを確認します。
-
テーブルをクリックすると、 [概要] タブにテーブルスキーマが表示されます。
-
[サンプルデータ] をクリックすると、テーブルから100行のデータが表示されます。
データノートブックのインポートと視覚化
次のいずれかのノートブックを使用して、この記事の手順を実行します。 <catalog-name>、<schema-name>、および <volume-name> を、Unity Catalog ボリュームのカタログ、スキーマ、およびボリューム名に置き換えます。必要に応じて、 table_name 値を任意のテーブル名に置き換えます。
- Python
- Scala
- R
Pythonを使用してCSVからデータをインポートする
Scala を使用して CSV からデータをインポートする
R を使用して CSV からデータをインポートする
次のステップ
- 探索的データ分析 (EDA) 手法の詳細については、「 チュートリアル: Databricks ノートブックを使用した EDA 手法」を参照してください。
- ETL (抽出、変換、ロード) パイプラインの構築について学習するには、チュートリアル: Lakeflow Spark宣言型パイプラインを使用してETLパイプラインを構築するおよびチュートリアル: DatabricksプラットフォームでApache Spark使用してETLパイプラインを構築するを参照してください。