チュートリアル: カスタム モデルのデプロイとクエリ
この記事では、モデルサービング モデルを使用して、カスタム モデル (従来のMLモデル) をデプロイおよびクエリするための基本的なステップを説明します。 モデルはUnity Catalogまたはワークスペースモデルレジストリに登録されている必要があります。
代わりに生成AI モデルの提供とデプロイについては、次の記事を参照してください。
ステップ 1: モデルのログを記録する
モデルサービングのモデルをログに記録するには、さまざまな方法があります。
ロギング手法 | 説明 |
|---|---|
オートロギング | これは、機械学習に Databricks Runtime を使用すると自動的に有効になります。これは最も簡単な方法ですが、制御が少なくなります。 |
MLflow の組み込みフレーバーを使用したログ記録 | MLflow の組み込みモデル フレーバーを使用して、モデルを手動でログに記録できます。 |
カスタムロギング | カスタムモデルがある場合、または推論の前後に追加のステップが必要な場合に、これを使用します。 |
次の例は、 transformer フレーバーを使用して MLflow モデルをログに記録し、モデルに必要なパラメーターを指定する方法を示しています。
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
モデルがログに記録されたら、モデルが Unity Catalog、またはMLflowのモデルレジストリに登録されていることを確認してください。
ステップ2:サービングUIを使用してエンドポイントを作成します
登録したモデルがログに記録され、それをサービングする準備ができたら、 サービング UI を使用してモデルサービングエンドポイントを作成できます。
-
サイドバーの [ サービング ] をクリックして、 サービング UI を表示します。
-
[ サービングエンドポイントの作成 ]をクリックします。
-
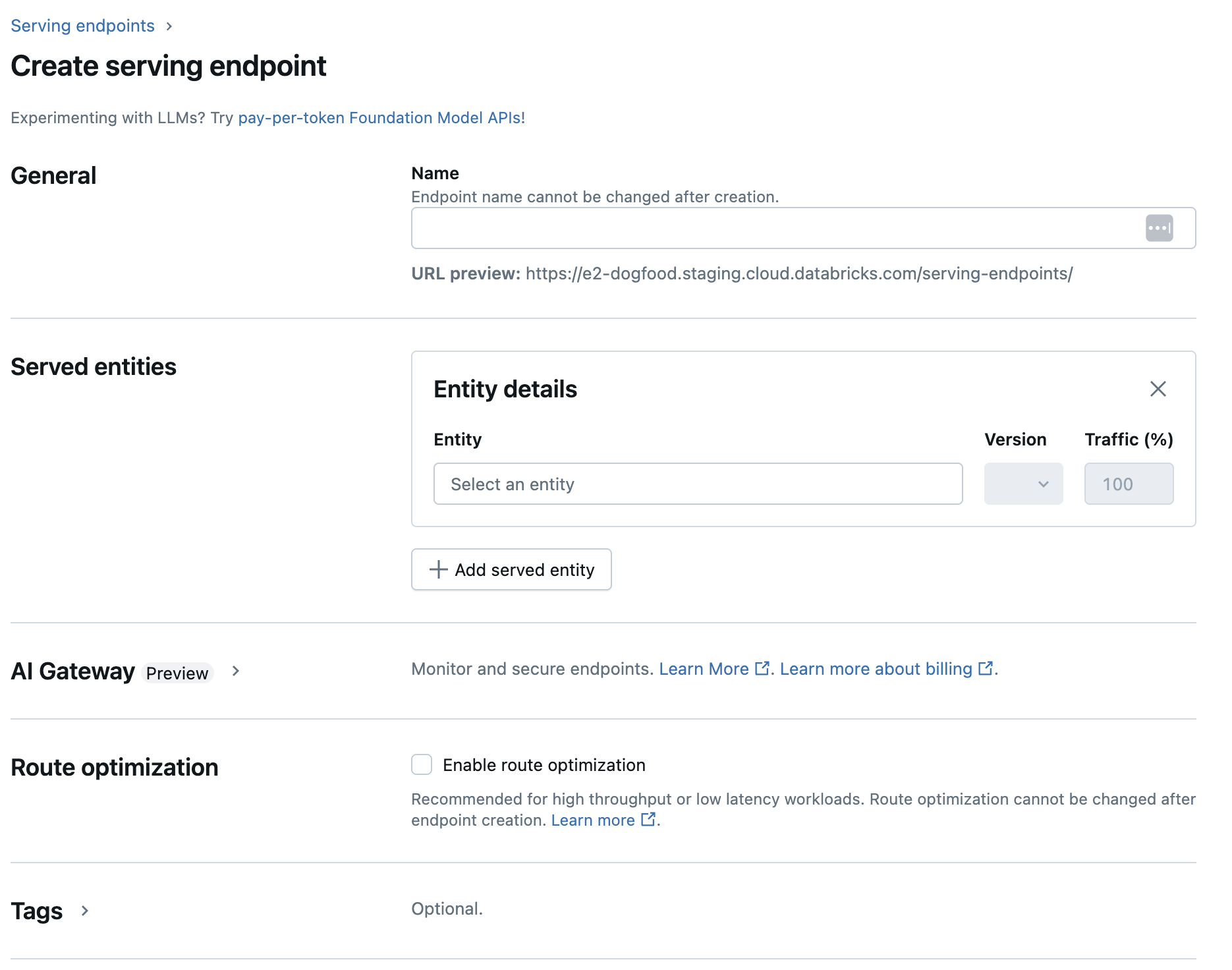
[ 名前 ]フィールドに、エンドポイントの名前を入力します。
-
Served entities セクションで
-
エンティティ フィールドをクリックして、 サービング済みエンティティの選択 フォームを開きます。
-
提供したいモデルのタイプを選択してください。 フォームは選択内容に基づいて動的に更新されます。
-
提供するモデルとモデルバージョンを選択します。
-
サービングされるモデルにルーティングするトラフィックの割合を選択します。
-
使用するコンピュートのサイズを選択します。
-
コンピュート スケールアウト で、このサーブ モデルが同時に処理できる要求の数に対応するコンピュート スケールアウトのサイズを選択します。この数値は、QPS x モデルの実行時間とほぼ等しくする必要があります。
- 使用可能なサイズは、0 から 4 リクエストの場合は Small 、8 から 16リクエストの場合は Medium 、16-64リクエストの場合は Large です。
-
使用していないときにエンドポイントを 0 にスケーリングするかどうかを指定します。
-
-
作成 をクリックします。 サービングエンドポイント ページが表示され、 サービングエンドポイントの状態 が [準備ができていません] と表示されます。
Databricks Serving APIを使用してプログラムでエンドポイントを作成する場合は、「カスタム モデルサービング エンドポイントを作成する」を参照してください。
ステップ 3: エンドポイントをクエリする
テストしてサーバーモデルにスコアリングリクエストを送信する最も簡単で速い方法は、 サービング UIを使用することです。
-
サービングエンドポイント ページで、 エンドポイントのクエリー を選択します。
-
モデル入力データをJSON形式で挿入し、[ リクエストの送信 ]をクリックします。 モデルが入力例とともにログ記録されている場合は、[ 例を表示 ] をクリックして入力例を読み込みます。
Python{
"inputs" : ["Hello, I'm a language model,"],
"params" : {"max_new_tokens": 10, "temperature": 1}
}
スコアリング要求を送信するには、サポートされているキーの 1 つと、入力形式に対応する JSON オブジェクトを使用して JSON を作成します。 サポートされている形式と、API を使用してスコアリング要求を送信する方法に関するガイダンスについては、 カスタム モデルのクエリ サービング エンドポイント を参照してください。
Databricks Serving UI の外部でサービス エンドポイントにアクセスする予定の場合は、 DATABRICKS_API_TOKENが必要です。
本番運用シナリオのセキュリティのベスト プラクティスとして、 Databricks では、本番運用中の認証に マシン間 OAuth トークン を使用することをお勧めします。
テストと開発のために、 Databricks ワークスペース ユーザーではなく 、サービスプリンシパル に属する個人用アクセス トークンを使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
ノートブックの例
モデルサービングを使用して MLflow transformersモデルを提供する方法については、次のノートブックを参照してください。
Hugging Face トランスフォーマー モデル をデプロイするノートブック
モデルサービングを使用して MLflow pyfuncモデルを提供する方法については、次のノートブックを参照してください。 モデル デプロイのカスタマイズの詳細については、「 モデルサービングを使用した Python コードのデプロイ」を参照してください。