モデルサービングエンドポイントからリソースへのアクセスを構成する
この記事では、モデルサービング エンドポイントから外部リソースとプライベート リソースへのアクセスを構成する方法について説明します。 モデルサービングは、プレーンテキストの環境変数と、Databricksシークレットを使用したシークレットベースの環境変数をサポートしています。
必要条件
シークレットベースの環境変数の場合、
- エンドポイント作成者は、構成で参照されている Databricks シークレットへの読み取りアクセス権を持っている必要があります。
- API キーやその他のトークンなどの資格情報は、Databricks シークレットとして保存する必要があります。
プレーンテキスト環境変数の追加
非表示にする必要のない変数を設定するには、プレーンテキスト環境変数を使用します。エンドポイントを作成または更新するときに、Serving UI、REST API、または SDK で変数を設定できます。
- Serving UI
- REST API
- WorkspaceClient SDK
- MLflow Deployments SDK
Serving UI から、 Advanced configurations で環境変数を追加できます。
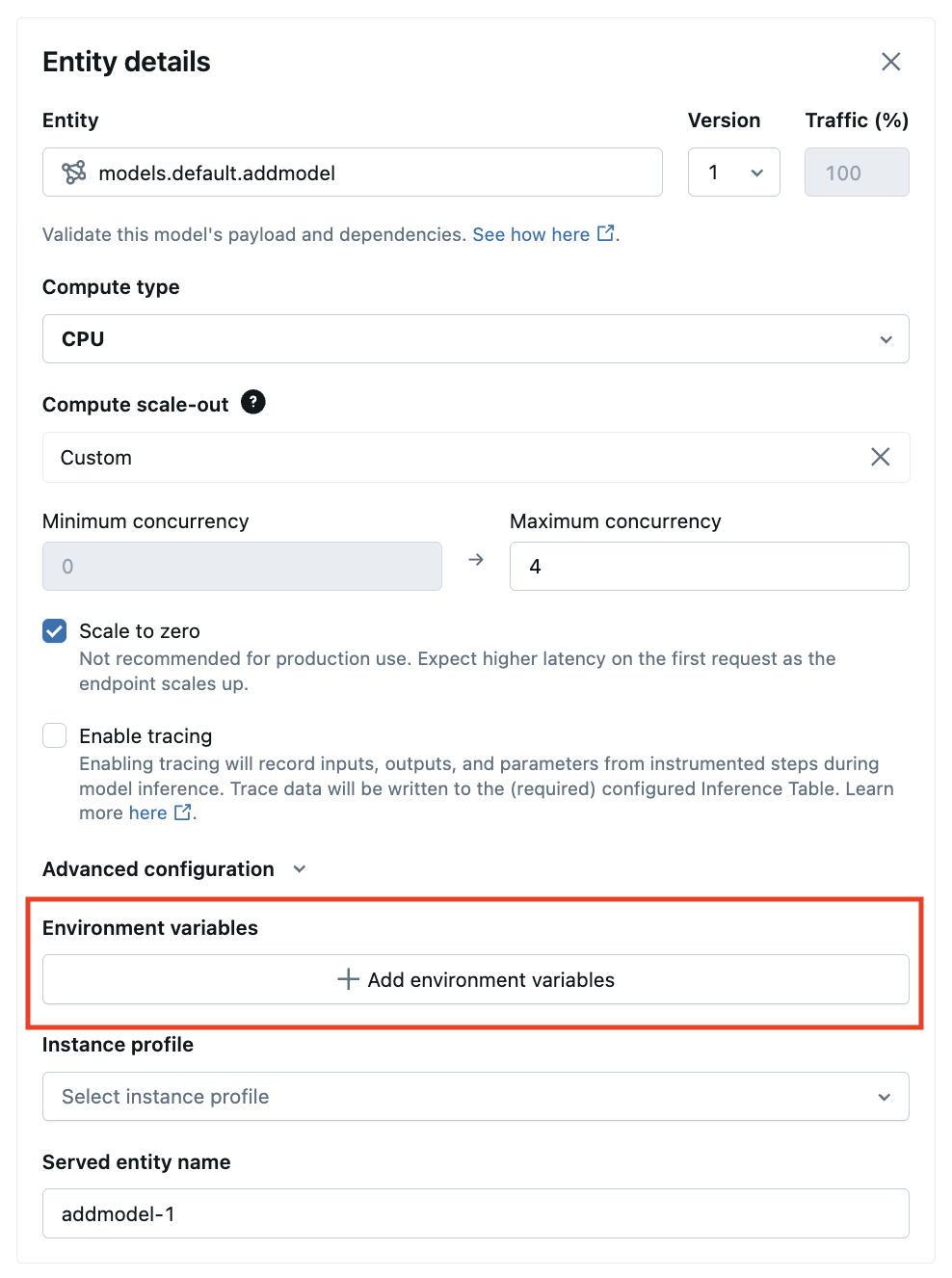
以下は、 POST /api/2.0/serving-endpoints REST API と environment_vars フィールドを使用して環境変数を設定するためのサービングエンドポイントを作成する例です。
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"TEXT_ENV_VAR_NAME": "plain-text-env-value"
}
}
]
}
}
以下は、WorkspaceClient SDK とenvironment_varsフィールドを使用して環境変数を構成し、サービス エンドポイントを作成する例です。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
)
]
)
)
以下は、Mlflow デプロイメント SDK とenvironment_varsフィールドを使用してサービス エンドポイントを作成し、環境変数を構成する例です。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
}
]
}
)
推論テーブルへの特徴量検索 データフレームの記録
エンドポイントで推論テーブルが有効になっている場合は、ENABLE_FEATURE_TRACINGを使用して、自動特徴ルックアップデータフレームをその推論テーブルに記録できます。これには MLflow 2.14.0 以降が必要です。
エンドポイントを作成または更新するときに、Serving UI、REST API、または SDK でENABLE_FEATURE_TRACING環境変数として設定します。
- Serving UI
- REST API
- WorkspaceClient SDK
- MLflow Deployments SDK
- 詳細構成 で、** + 環境変数の追加** を選択します。
- 環境名として「
ENABLE_FEATURE_TRACING」と入力します。 - 右側のフィールドに「
true」と入力します。
次に、 POST /api/2.0/serving-endpoints REST API と environment_vars フィールドを使用して ENABLE_FEATURE_TRACING 環境変数を設定するサービスエンドポイントを作成する例を示します。
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
}
以下は、WorkspaceClient SDK とenvironment_varsフィールドを使用してサービス エンドポイントを作成し、 ENABLE_FEATURE_TRACING環境変数を構成する例です。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"ENABLE_FEATURE_TRACING": "true"
}
)
]
)
)
以下は、Mlflow デプロイメント SDK とenvironment_varsフィールドを使用してサービス エンドポイントを作成し、 ENABLE_FEATURE_TRACING環境変数を構成する例です。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
)
シークレットベースの環境変数を追加する
Databricksシークレットを使用して認証情報を安全に保存し、シークレットベースの環境変数を使用してモデルサービングでそれらのシークレットを参照できます。これにより、サービス時にモデルサービングエンドポイントから資格情報を取得できます。
たとえば、OpenAI やその他の外部モデルエンドポイントを呼び出したり、モデルサービングから直接外部データストレージの場所にアクセスしたりするために、認証情報を渡すことができます。
Databricks では、 OpenAI と LangChain MLflow モデル フレーバーをサービスにデプロイするために、この機能を推奨しています。 また、アクセスパターンが環境変数とAPIキーおよびトークンの使用に基づいていることを理解した上で、資格情報を必要とする他のSaaSモデルにも適用できます。
ステップ 1: シークレットスコープを作成する
モデルサービング中、シークレットスコープとキーによって Databricks シークレットからシークレットが取得されます。 これらは、モデル内で使用できるシークレット環境変数名に割り当てられます。
まず、シークレットスコープを作成します。 シークレットスコープの管理を参照してください。
次に、CLI コマンドを示します。
databricks secrets create-scope my_secret_scope
その後、以下に示すように、シークレットを目的のシークレットスコープとキーに追加できます。
databricks secrets put-secret my_secret_scope my_secret_key
シークレット情報と環境変数の名前は、エンドポイントの作成時にエンドポイント設定に渡すことも、既存のエンドポイントの設定の更新として渡すこともできます。
ステップ 2: エンドポイント設定にシークレットスコープを追加する
シークレットスコープを環境変数に追加し、エンドポイントの作成時または設定の更新時にその変数をエンドポイントに渡すことができます。 「カスタム モデルサービング エンドポイントの作成」を参照してください。
- Serving UI
- REST API
- WorkspaceClient SDK
- MLflow Deployments SDK
Serving UI から、 詳細設定 で環境変数を追加できます。 シークレットベースの環境変数は、 {{secrets/scope/key}}の構文を使用して指定する必要があります。 それ以外の場合、環境変数はプレーンテキスト環境変数と見なされます。
次に、REST API を使用してサービスエンドポイントを作成する例を示します。 モデルサービングエンドポイントの作成および設定の更新中に、 environment_vars フィールドを使用して、API リクエスト内で提供される各モデルのシークレット環境変数仕様のリストを提供できます。
次の例では、指定されたコードで作成されたシークレットの値を環境変数 OPENAI_API_KEYに代入します。
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
}
次の PUT /api/2.0/serving-endpoints/{name}/configREST API の例のように、配信エンドポイントを更新することもできます。
{
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "2",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
以下は、WorkspaceClient SDK を使用してサービス エンドポイントを作成する例です。モデルサービング エンドポイントの作成および構成の更新中に、 environment_varsフィールドを使用して、 APIリクエスト内で提供される各モデルの秘密の環境変数仕様のリストを提供できます。
次の例では、指定されたコードで作成されたシークレットの値を環境変数 OPENAI_API_KEYに代入します。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
)
]
)
)
以下は、Mlflow デプロイメント SDK を使用してサービス エンドポイントを作成する例です。モデルサービング エンドポイントの作成および構成の更新中に、 environment_varsフィールドを使用して、 APIリクエスト内で提供される各モデルの秘密の環境変数仕様のリストを提供できます。
次の例では、指定されたコードで作成されたシークレットの値を環境変数 OPENAI_API_KEYに代入します。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
)
エンドポイントが作成または更新されると、モデルサービングは Databricks シークレットスコープからシークレットキーを自動的にフェッチし、モデル推論コードが使用する環境変数を入力します。
ノートブックの例
シークレットベースの環境変数を使用してモデルサービングエンドポイントの背後にデプロイされたLangChainのRetrieval QA チェーン の OpenAI APIキーを設定する方法の例については、次のノートブックを参照してください。