ノートブックの出力と結果
ノートブックをクラスターに接続してセルを実行すると、ノートブックは状態を保持し、セルの出力を表示します。状態や出力のクリア、結果テーブルの操作、データの並べ替え、フィルタリング、フォーマット、および結果のダウンロードが可能です。
ノートブックの状態と出力をクリアする
ノートブックの状態と出力をクリアするには、 実行 メニューの下部にある クリア オプションのいずれかを選択します。
メニューオプション | 説明 |
|---|---|
すべてのセル出力をクリア | セル出力をクリアします。 これは、ノートブックを共有し、結果を含めないようにする場合に便利です。 |
状態を消去 | ノートブックの状態 (関数と変数の定義、データ、インポートされたライブラリなど) をクリアします。 |
状態と出力をクリア | セルの出力とノートブックの状態をクリアします。 |
状態をクリアしてすべて実行 | ノートブックの状態をクリアし、新しい実行を開始します。 |
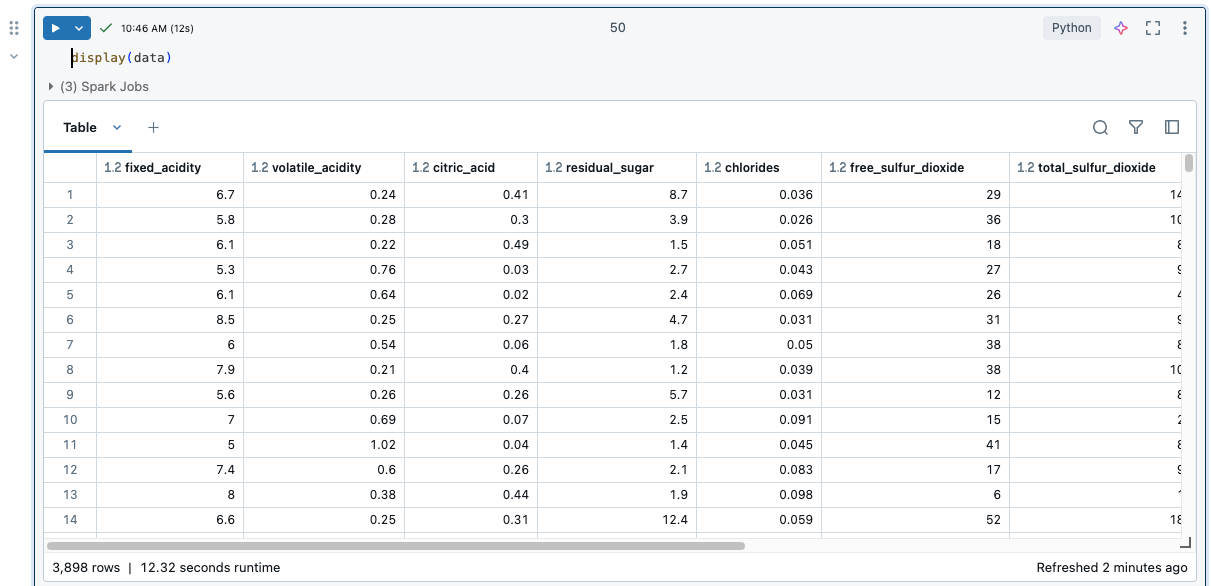
結果テーブル
セルを実行すると、結果が結果テーブルに表示されます。 結果テーブルでは、次の操作を実行できます。
- 列または表形式の結果データの他のサブセットをクリップボードにコピーします。
- 結果表でテキスト検索をしてください。
- データを並べ替えてフィルタリングします。
- キーボードの矢印キーを使用して、テーブルのセル間を移動します。
- 列名またはセル値の一部を選択するには、ダブルクリックしてドラッグし、目的のテキストを選択します。
- 列エクスプローラーを使用して、列の検索、表示または非表示、ピン留め、および再配置を行います。
結果テーブルの制限を表示するには、「 ノートブックの結果テーブルの制限」を参照してください。
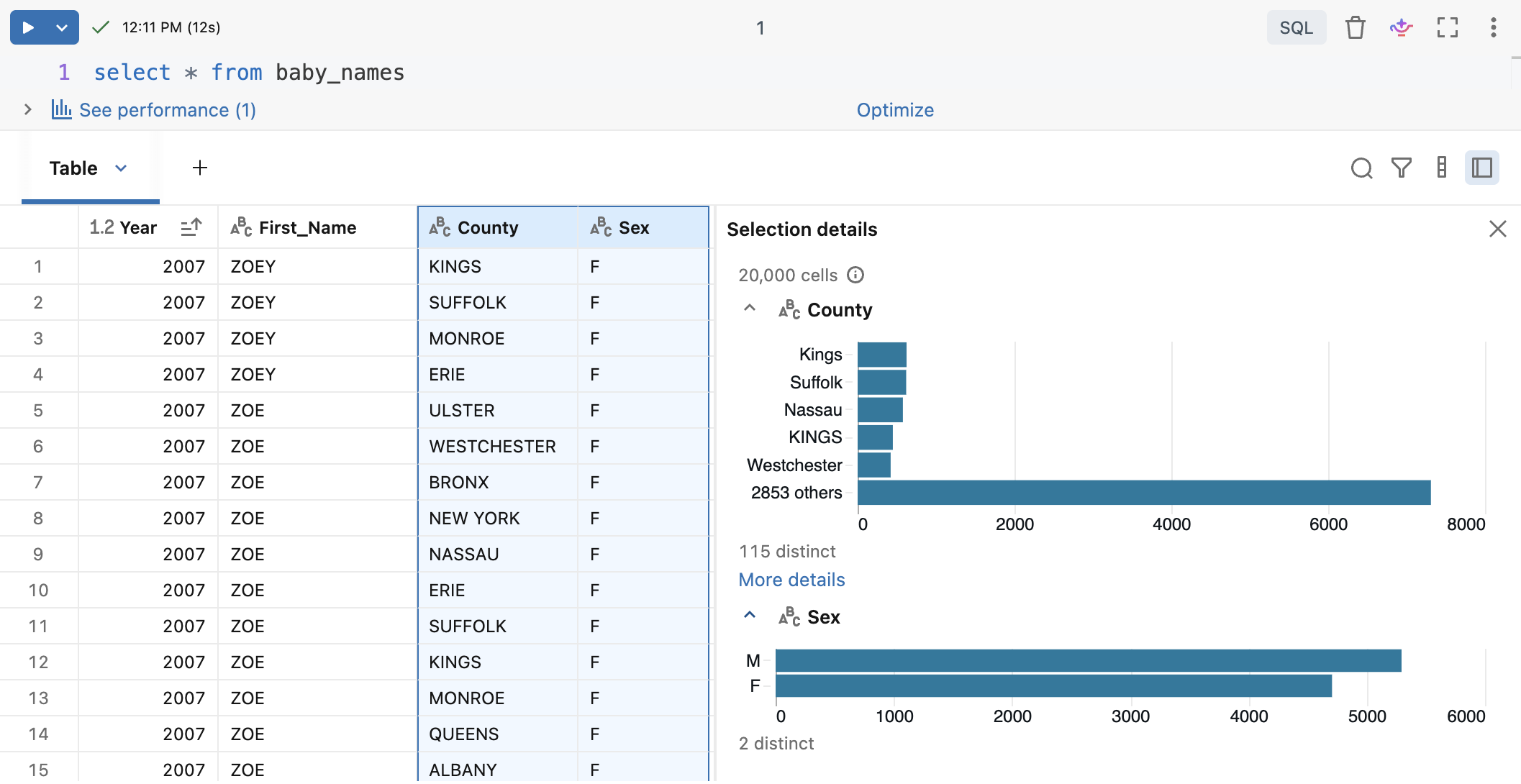
データを選択
結果表のデータを選択するには、次のいずれかを実行してください。
- データまたはデータのサブセットをクリップボードにコピーします。
- 列または行のヘッダーをクリックします。
- テーブルの左上のセルをクリックして、テーブル全体を選択します。
- 任意のセルのセットにカーソルをドラッグして選択します。
- 複数の列を選択するには、 Ctrlキー (Windows)または Cmdキー (macOS)を押しながら、追加の列ヘッダーをクリックします。ケバブメニューを使用すると、コピー、フィルター、書式設定、ピン留めなどの操作を、選択したすべての列に一度に適用できます。
 。
。
選択情報を表示するサイドペインを開くには、![]() 選択内容の詳細を開く 。列ヘッダーを選択すると、プロファイリング統計が表示されます。
選択内容の詳細を開く 。列ヘッダーを選択すると、プロファイリング統計が表示されます。
データをクリップボードにコピーする
結果テーブルを CSV 形式でクリップボードにコピーするには、テーブルのタイトルタブの横にある下向き矢印をクリックし、[ 結果をクリップボードにコピー ] をクリックします。
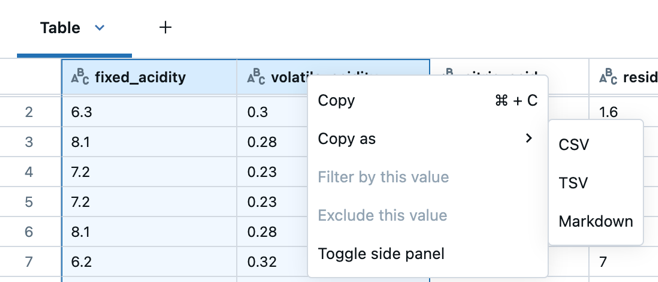
または、テーブルの左上にあるボックスをクリックしてテーブル全体を選択し、右クリックしてドロップダウンメニューから[ コピー ]を選択します。
選択したデータをコピーするには、いくつかの方法があります。
- MacOSの場合は
Cmd + C、Windowsの場合はCtrl + Cを押して、結果をCSV形式でクリップボードにコピーします。 - 右クリックして コピー を選択し、結果を CSV 形式でクリップボードにコピーします。
- 右クリックして コピー > を選択し、選択したデータをCSV、TSV、またはMarkdown形式でコピーします。
結果を並べ替える
結果テーブルを列の値で並べ替えるには、列名の上にカーソルを置きます。 列名を含むアイコンがセルの右側に表示されます。 矢印をクリックして列を並べ替えます。
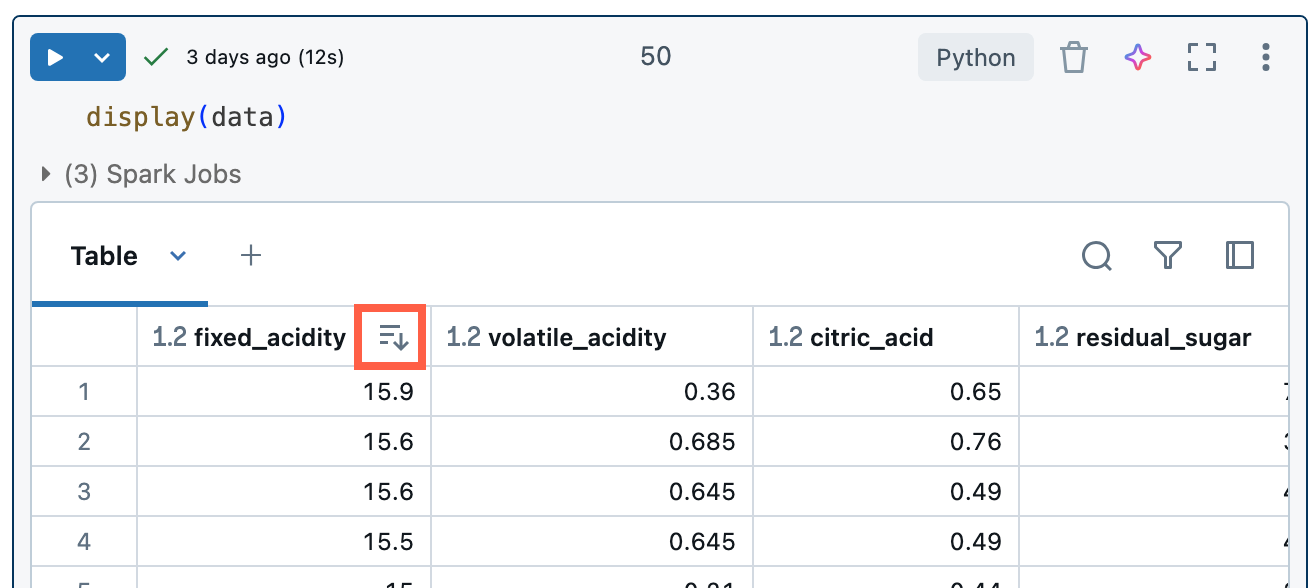
複数の列で並べ替えるには、 Shift キーを押しながら列の並べ替え矢印をクリックします。
並べ替えは、デフォルトによる自然な並べ替え順序に従います。 辞書式ソート順序を適用するには、SQLの ORDER BY を使用するか、環境で使用可能なそれぞれの SORT 関数を使用します。
結果をフィルタリングする
結果テーブルでフィルタを使用して、データを詳しく調べます。結果テーブルに適用されるフィルターは視覚化にも影響するため、基になるクエリやデータセットを変更せずに対話型の探索が可能になります。「ビジュアリゼーションのフィルター」を参照してください。
フィルターを作成するには、いくつかの方法があります。
- Genie Code
- Filter dialog
- By value
- By column
Genie Codeで自然言語プロンプトを使用します。
自然言語プロンプトを使用してフィルターを作成します。
- セル結果の右上にある [
 ] をクリックします。
] をクリックします。 - 表示されるダイアログで、必要なフィルターを説明するテキストを入力します。
- クリック
 。Genie Codeは、フィルターを生成して適用します。
。Genie Codeは、フィルターを生成して適用します。
Genie Code を使用して追加のフィルターを作成したい場合は、フィルターの横にある ![]() をクリックして、別のプロンプトを入力します。
をクリックして、別のプロンプトを入力します。
自然言語プロンプトによるデータのフィルタリングを参照してください。
組み込みのフィルターダイアログを使用する
- Genie Codeが有効になっていない場合は、セル結果の右上にある をクリックして、フィルター ダイアログを開きます。このダイアログには、
![[フィルターの追加] ボタン](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAE8AAAAcCAYAAAAgLuLfAAAAAXNSR0IArs4c6QAAAERlWElmTU0AKgAAAAgAAYdpAAQAAAABAAAAGgAAAAAAA6ABAAMAAAABAAEAAKACAAQAAAABAAAAT6ADAAQAAAABAAAAHAAAAAB9MFOvAAAFQElEQVRoBe1Ze1BUVRj/7YJNI/FYBUV8NGNTPDSnqUzCmoackEBJMZumUcdIzTAtJXw0TGU2WJOjjDpMDqJgrKIiCiqPGXM0fCxgjJNQqC3Ea2AgiIcgsLvc7neae3cvy+7dXeSfut/M3XPO9/u+b8/+7ne+c/ceFccLFHGJAbVLXooTY8B9OA8P+vpR19KOv7v6YOKGhsP/y7GbSg2N93g86T8RT4x/XORAZblsibjbdxvw1DQ/TJrgBTc3JTGJKZNpCK0d3dA3tuG5wOkigRLyqmqaMMHTA1P8fER2lY6Zgea2TnT09GLWzKlMKUktWqqUcYqMzABxQxwJIiGPapyyVAVqrFvixnIfkJBnba5o7DGgkGePHRlsVOSZTCacOXsO7e3tMl8D7Nt/EFdLrtm0s4cPGgzMf2XcGty9dx+/3qkE9Xt7e9HQ0IiPNn7C74gmm7HHChgVebrSMqyN34jDRzNk53f9xg3U19fbtLOH55+/gAOpP+CdZbHw95/MYhgGDazt7unGyZxcMa72RDYOpaWL47HsjIo8yjqSQ4ePjumdr639E9GREVgcHQVvLy/MeXY2srMy4eHhYcWNvqaWz857VvqxULhMXk/PA2RkHceF3NPo7OpCaVm5ZH6ZP2rx6oIIzAyajb0p+yUYDeRwwSHpy53YvWcvtCdPI+y11/GHXo/Kqt9YbMFGaHclf4uUg6lsXmTb0NjEoHP55xEVE8vmsmlzglhmBgYGWMy09COs3ZK4TQjlWEv/MAS58ku10JVtc8/lcc/PC+P4WsPtSPqCS9i6XfQpKCrmNP7TuLN5+dzv1dVcwrYdbHwsS8ts5HAxEN9pbW3jErd/zq1dH8/V1dVzA4OD3K2KChaP7CqrqljfaDRybW1/cZs/28p9sG49szUYjNyVn0sYfrGwiM2F4ixa+jb7iocPHzIsPOJN7qaulGtsamJ6ex+WHLmceSeyT2HVivegVqsRsygaR45lgbKRpKCwCJ9+HI8lMYsRFBiI5F07JXdSDrc09vPzhUbjAy9vb8yYMR2PjRtnCUv6vr4T4ePD2/JLm2zd3d1wKucM1qxehVfmhyEgIACJCVtw/aYOzS0tom/y118hdN5LmMrjzojViwFHnGk5XLpyFfraWuj1NTAYjczt0uXLWPpWDG7zu+GGD9eJoegHh86dK47lcNHwEXROnMphUXLO5kmiNfK/QcMTTaLRaCSYowOXyLtYUMjiJ+0w1wja8dLSMxh5IUGB/CNEgzgHeoyotijicrjo+Ag6y2OXYFZIMDZtiLeK1t/fb6VzRuH0suXrAY5pj2PP7m8YUZRpdJX8VAxdeTn4uoEF4eGsyNOjTEdHB/bsS2GbijAxOVywc6WdPGkSdPzmRfMYGhpCZMQbSDmQirLyW6ys8HUYL4TOR2dnpyvhJT5OZ96dyio+i+4jcmGEJFBIcDCCnnkahUXFWBP3PvQ1ekQtWcZs4latwPyXQ1l9JMXyZUvt4pLA/EClUkHNX4LQ2JZERS5EZpYWc14MRYXuGruxzc0teHflanYDA6b4I+X771htFDLPXjxb38P0ljuL5U5iqXe1z/8z4Pr6+my6y+E2HWUAPuPYrmxpRrqu7m6O2tGIJUdOZ57dOzEMHOfuDrpsiRxuy09OT5k0fFcmnZenp5yrU7jTNc+p6P9xYwl59K6eXjkrMjIDxA1xJIi5x2vokIPe1SsyMgPEDXEkiIQ8Oh2iQw56V69koEDRvwdAxAlxQxwJIjkAIqVy9ChQY24dOno0mys9RxiQLFtHHBQbMwP/ANahBET9oTZSAAAAAElFTkSuQmCC) 。
。 - フィルタリングする列を選択します。
- 適用するフィルタールールを選択します。
- フィルタリングする値を選択します。
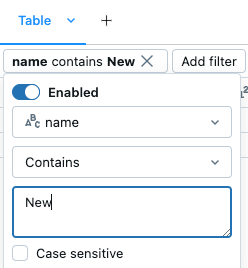
特定の値でフィルタリングする
- 結果テーブルから、その値を含むセルを右クリックします。
- ドロップダウンメニューから[ Filter by this value ]を選択します。
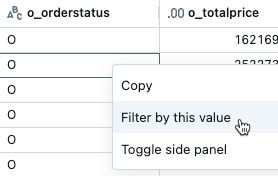
特定の列でフィルター処理する
- フィルタリングする列にカーソルを合わせます。
- をクリックします。
- フィルター をクリックします。
- フィルタリングする値を選択します。
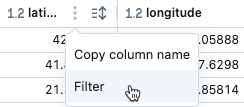
フィルターを一時的に有効または無効にするには、ダイアログの 「有効/無効」 ボタンをクリックします。
![]() フィルターを削除するには、フィルター名 の横にある
フィルターを削除するには、フィルター名 の横にある![]() をクリックします。
をクリックします。
完全なデータセットにフィルターを適用する
デフォルトでは、フィルタは結果テーブルに表示される結果にのみ適用されます。 返されるデータが切り捨てられる場合 (たとえば、クエリが 10,000 行を超える行を返す場合や、データセットが 2 MB を超える場合)、フィルターは返された行にのみ適用されます。 表の右上にあるメモは、切り捨てられたデータにフィルターが適用されたことを示しています。
代わりに、データセット全体をフィルタリングすることもできます。 「切り捨てデータ」 をクリックし、次に 「完全なデータセット」 を選択します。データセットのサイズによっては、フィルターの適用に時間がかかる場合があります。

フィルター処理された結果からクエリを作成する
SQLをデフォルト言語 として使用したノートブックのフィルター済み結果テーブルまたはビジュアライゼーションから、フィルターが適用された新しいクエリを作成できます。テーブルまたはビジュアライゼーションの右上にある [ クエリの作成 ] をクリックします。クエリは、ノートブックの次のセルとして追加されます。
作成されたクエリは、元のクエリの上にフィルターを適用します。これにより、より小さく、より関連性の高いデータセットを操作できるため、より効率的なデータ探索と分析が可能になります。

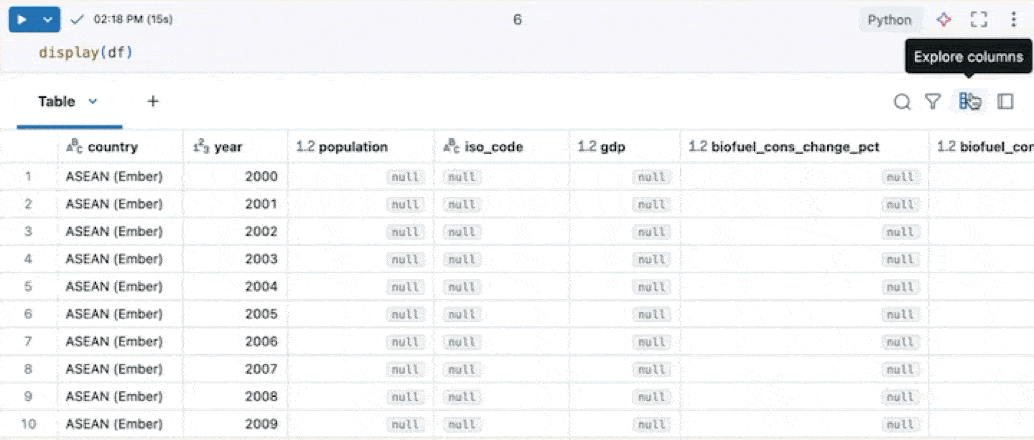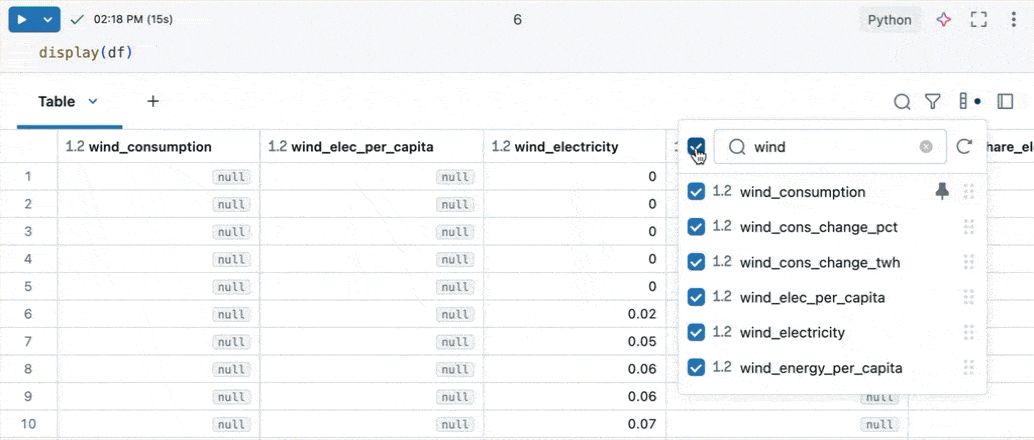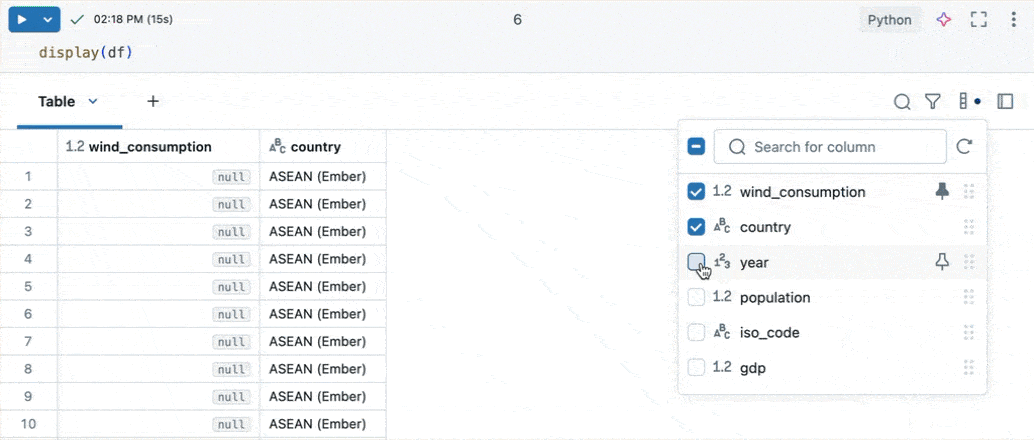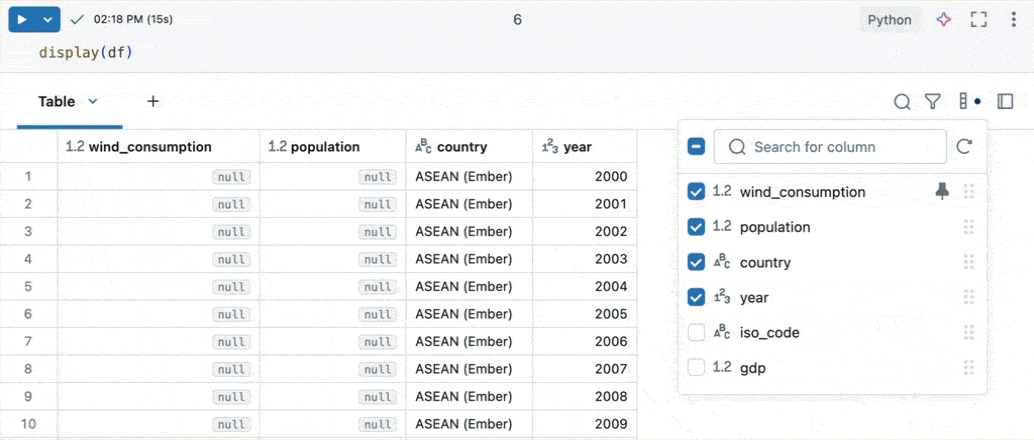
列の探索
多くの列を持つテーブルの操作を容易にするために、カラムエクスプローラーを使用できます。カラムエクスプローラーを開くには、結果テーブルの右上にあるカラムアイコン (![]() ) をクリックします。
) をクリックします。
カラムエクスプローラーでは、次のことができます。
- 列を検索する :検索バーに入力して、列のリストを絞り込みます。エクスプローラーで列をクリックすると、結果テーブル内の該当箇所に移動します。
- 列を表示または非表示 にする: チェックボックスを使用して、列の表示を制御します。上部のチェックボックスは、すべての列の表示を一度に切り替えます。個々の列は、名前の横にあるチェックボックスを使用して表示または非表示にできます。
- 列のピン留め : 列名にカーソルを合わせると、ピン留めアイコンが表示されます。 ピン留めアイコンをクリックして、列をピン留めします。 ピン留めされた列は、結果テーブルを水平方向にスクロールしても表示されたままになります。
- 列を並べ替え る: 列の名前の右側にあるドラッグ アイコン (
 ) をクリックしたまま、列を新しい目的の位置にドラッグ アンド ドロップします。これにより、結果テーブルの列が並べ替えられます。
) をクリックしたまま、列を新しい目的の位置にドラッグ アンド ドロップします。これにより、結果テーブルの列が並べ替えられます。
列の書式設定
列ヘッダーは、列のデータ型を示します。 たとえば、 ![]() は整数データ型を示します。 インジケーターにカーソルを合わせると、データ型が表示されます。
は整数データ型を示します。 インジケーターにカーソルを合わせると、データ型が表示されます。
結果テーブルの列は、 通貨 、 パーセンテージ 、 URL などのタイプとしてフォーマットでき、小数点以下の桁数を制御してテーブルをより明確にすることができます。
列名でケバブメニューの列をフォーマットします。

結果のダウンロード
デフォルトでは、結果のダウンロードは有効になっています。この設定を変更するには、 「ノートブックから結果をダウンロードする機能を管理する」を参照してください。
表形式の出力を含むセル結果をローカル コンピューターにダウンロードできます。 タブタイトルの横にある下向きの矢印をクリックします。 メニュー オプションは、結果の行数と Databricks Runtime のバージョンによって異なります。 ダウンロードした結果は、ノートブック名に対応する名前の CSV ファイルとしてローカル マシンに保存されます。
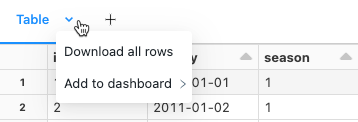
SQLウェアハウスまたはサーバレス コンピュートに接続されているノートブックの場合、結果をExcelファイルとしてダウンロードすることもできます。
SQL セルの結果を調べる
Databricks ノートブックでは、SQL 言語セルの結果は、変数 _sqldfに割り当てられた データフレーム として自動的に使用できます。 _sqldf変数を使用して、後続の Python セルと SQL セルで前の SQL 出力を参照できます。詳細については、「 SQL セルの結果の調査」を参照してください。
セルごとに複数の出力を表示する
Python ノートブックと Python 以外のノートブックの %python セルは、セルごとに複数の出力をサポートします。 たとえば、次のコードの出力には、プロットとテーブルの両方が含まれています。
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
出力のサイズ変更
セル出力のサイズを変更するには、テーブルまたはビジュアライゼーションの右下隅をドラッグします。
Databricks Git フォルダーにノートブックの出力をコミットする
.ipynb のコミットについて学習するには ノートブック出力については、「 .ipynb ノートブック出力のコミットを許可する」を参照してください。
- ノートブックは .ipynb である必要があります ファイル
- ワークスペース管理者設定では、ノートブックの出力をコミットできるようにする必要があります