顧客管理VPCの構成
このページでは、顧客管理VPCの利点と実装について説明します。
概要
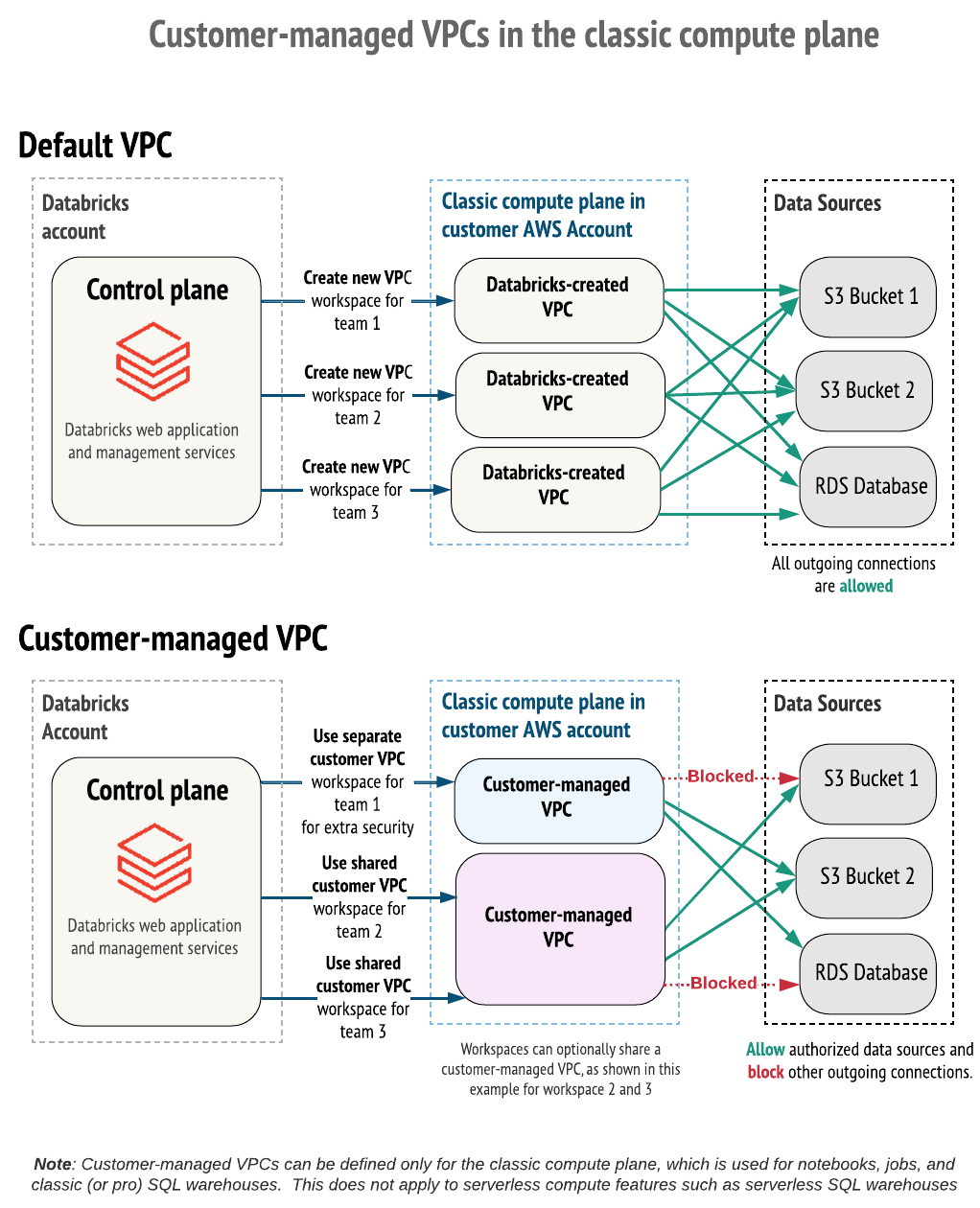
デフォルトでは、Databricks クラスターは、AWSアカウント内で作成および構成する単一の Virtual Private Cloud(VPC)に作成されます。
または、独自の VPC 内に Databricks ワークスペースを作成することもできます。この機能は、 顧客管理VPC と呼ばれます。
顧客管理VPC は、次の場合に使用します。
- 強化された制御: ネットワーク構成をより詳細に制御できます。
- コンプライアンス: 組織が必要とする特定のクラウドセキュリティおよびガバナンス標準に準拠します。
- 内部ポリシー: プロバイダーが AWS アカウントで VPC を作成するのを防ぐセキュリティポリシーを遵守します。
- 明確な承認プロセス: VPC を自社のチーム (情報セキュリティ、クラウドエンジニアリングなど) によって構成および保護する必要がある内部承認プロセスに合わせます。
- AWS PrivateLink: カスタマー管理VPCは、クラシック コンピュート プレーン (バックエンド) AWS PrivateLink 接続に 必要 です。 インバウンド (フロントエンド) とアウトバウンド (サーバレス コンピュート プレーン) のAWS PrivateLinks には顧客管理VPCは必要ありません。
カスタマーマネージドVPCのメリットは次のとおりです。
-
下位の特権レベル: AWS アカウントをより詳細に制御できます。Databricks は、クロスアカウント IAMロールを使用する権限がデフォルト設定に比べて少ないため、内部承認を簡素化できます。
-
ネットワーク運用の簡素化: ワークスペースのサブネットを小さく構成することで、ネットワーク領域の使用率を デフォルト /16 CIDRと比較して向上させます。 複雑になる可能性のある VPC ピアリング設定を回避します。
-
統合 VPC: 複数の Databricks ワークスペースで 1 つのクラシック コンピュートプレーン VPCを共有できます。これは、多くの場合、課金やインスタンス管理に適しています。
-
送信接続を制限する: 出力ファイアウォールまたはプロキシ アプライアンスを使用して、送信トラフィックを許可された内部または外部データソースのリストに制限します。
顧客管理VPCを利用するには、Databricks ワークスペースを最初に作成するときにVPCを指定する必要があります。Databricks管理VPCを持つ既存のワークスペースを移動して、顧客管理VPC使用することはできません。ただし、顧客管理VPC を持つ既存のワークスペースを 1 つの VPC から別の VPC に移動するには、ワークスペース構成のネットワーク構成オブジェクトを更新します。 実行中または失敗したワークスペースの更新を参照してください。
独自のVPCにワークスペースをデプロイするには、次のことを行う必要があります:
-
VPC の要件に列挙されている要件に従って VPC を作成します。
-
ワークスペースを作成するときに、DatabricksのVPCネットワーク設定を参照します。
- アカウントコンソールを使用して 、名前で設定を選択します
- アカウント APIを使用し、ID で構成を選択します
VPCをDatabricksに登録するときに、VPC ID、サブネットID、セキュリティグループIDを指定する必要があります。
VPC の要件
Databricksワークスペースをホストするには、VPCがこのセクションで説明されている要件を満たしている必要があります。
要件:
VPC リージョン
顧客管理 VPCをサポートする AWSリージョンの一覧については、リージョンの可用性が制限されている機能を参照してください。
VPC のサイジング
1 つの AWS アカウント で 1 つの VPC を複数のワークスペースと共有できます。 ただし、Databricks では、ワークスペースごとに一意のサブネットとセキュリティ グループを使用することをお勧めします。 VPCとサブネットのサイズはそれに応じて設定してください。 Databricks ノードごとに2つのIPアドレス(1つは管理トラフィック用、もう1つは Apache Sparkアプリケーション用)を割り当てます。 各サブネットのインスタンスの合計数は、使用可能な IP アドレスの数の半分に等しくなります。 詳細については 、サブネットを参照してください。
VPC の IP アドレス範囲
Databricks では、ワークスペース VPC のネットマスクは制限されませんが、各ワークスペース サブネットには /17 から /26までのネットマスクが必要です。つまり、ワークスペースに 2 つのサブネットがあり、両方のネットマスクが /26の場合、ワークスペース VPC のネットマスクは /25 以下である必要があります。
VPCにセカンダリCIDRブロックを設定している場合は、Databricksワークスペースのサブネットが同じVPC CIDRブロックで設定されていることを確認してください。
DNS
VPCでDNSホスト名とDNS解決が有効になっている必要があります。
サブネット
Databricksは、 ワークスペースごとに少なくとも2つのサブネット にアクセスできる必要があります(各サブネットは異なるアベイラビリティゾーンにあります)。ネットワーク設定の作成APIコールでアベイラビリティゾーンごとに複数のDatabricksワークスペースサブネットを指定することはできません。ネットワーク設定の一環としてアベイラビリティゾーンごとに複数のサブネットを設定することはできますが、Databricksワークスペースに選択できるサブネットはアベイラビリティゾーンごとに1つだけです。
1つのサブネットを複数のワークスペースで共有するか、両方のサブネットをワークスペースで共有するかを選択できます。たとえば、同じVPCを共有する2つのワークスペースを持つことができます。あるワークスペースではサブネットAとBを使用し、別のワークスペースではサブネットAとCを使用することができます。複数のワークスペース間でサブネットを共有する場合は、使用量に応じて拡張できる大きさになるようにVPCとサブネットのサイズを設定してください。
Databricksは、ノードごとに2つのIPアドレス(1つは管理トラフィック用、もう1つはSparkアプリケーション用)を割り当てます。各サブネットのインスタンスの合計数は、使用可能なIPアドレスの数の半分になります。
各サブネットには、/17~/26のネットマスクが必要です。
追加のサブネット要件
- サブネットはプライベートにする必要があります。
- サブネットは、NATゲートウェイやインターネットゲートウェイ、またはその他の同様のカスタマーマネージドアプライアンスインフラストラクチャを使用して、パブリックネットワークへのアウトバウンドアクセスが可能であることが必要です。
- NAT ゲートウェイは、クワッドゼロ(
0.0.0.0/0) トラフィックをインターネットゲートウェイ またはその他の顧客管理アプライアンスインフラストラクチャにルーティングする独自のサブネットに設定する必要があります。
ワークスペースには、VPC からパブリックネットワークへのアウトバウンドアクセスが必要です。 IP アクセス リストを設定する場合は、それらのパブリック ネットワークを許可リストに追加する必要があります。 ワークスペースの IP アクセス リストの構成を参照してください。
サブネットルートテーブル
ワークスペースサブネットのルートテーブルには、適切なネットワークデバイスをターゲットとするクアッドゼロ(0.0.0.0/0)トラフィックが必要です。クアッドゼロトラフィックはNATゲートウェイまたは独自のマネージドNATデバイスまたはプロキシアプライアンスをターゲットにする必要があります。
Databricks では、許可リストに 0.0.0.0/0 を追加するためにサブネットが必要です。これは、優先される最初のルールである必要があります。エグレス トラフィックを制御するには、エグレス ファイアウォールまたはプロキシ アプライアンスを使用してほとんどのトラフィックをブロックしますが、Databricks が接続する必要がある URL を許可します。「ファイアウォールと送信アクセスの構成」を参照してください。
これはあくまでも基本的なガイドラインです。お客様の設定要件は異なる場合があります。ご質問がある場合は、Databricksアカウントチームにお問い合わせください。
セキュリティグループ
Databricksワークスペースは、少なくとも1つのAWSセキュリティグループと5つ以下のセキュリティグループにアクセスできる必要があります。新しいセキュリティグループを作成するのではなく、既存のセキュリティグループを再利用することができます。ただし、Databricksでは、ワークスペースごとに一意のサブネットとセキュリティグループを使用することをお勧めします。
セキュリティグループには、次のルールが必要です:
エグレス(アウトバウンド):
- ワークスペースセキュリティグループへのすべてのTCPおよびUDPアクセスを許可します(内部トラフィック用)
- 次のポートで
0.0.0.0/0へのTCPアクセスを許可します:- 443:Databricksインフラストラクチャ、クラウドデータソース、ライブラリリポジトリ用。
- 3306:メタストア用。
- 53: カスタムDNSを使用する場合のDNS解決用
- 6666: セキュリティで保護されたクラスター接続用。 これは、 PrivateLink を使用する場合にのみ必要です。
- 2443: FIPS 暗号化をサポートします。 コンプライアンス セキュリティ プロファイルを有効にする場合にのみ必要です。
- 5432: クラシック コンピュート プレーンからLakebaseへの接続用。
- 8443、8445: Databricksコンピュート プレーンからDatabricksコントロール プレーンAPIへの内部呼び出し用。
- 8444: Unity Catalogのログ記録とDatabricksへのリネージデータストリーミング用。
- 8446~8451:将来の使用のために予約済み。
イングレス(インバウンド): すべてのワークスペースに必要です(これらは個別のルールにすることも、1つにまとめることもできます):
- トラフィックソースが同じセキュリティグループを使用する場合、すべてのポートでTCPを許可します
- トラフィックソースが同じセキュリティグループを使用する場合、すべてのポートでUDPを許可します
サブネットレベルのネットワーク ACL
サブネットレベルのネットワークACLは、いかなるトラフィックに対してもイングレスまたはエグレスを拒否してはなりません。Databricksは、ワークスペースの作成時に次のルールを検証します:
エグレス(アウトバウンド):
- 内部トラフィックに対して、ワークスペースVPC CIDRへのすべてのトラフィックを許可します
- 次のポートで
0.0.0.0/0へのTCPアクセスを許可します:- 443:Databricksインフラストラクチャ、クラウドデータソース、ライブラリリポジトリ用。
- 3306:メタストア用。
- 6666: PrivateLink を使用する場合にのみ必要
- 8443、8445: Databricksコンピュート プレーンからDatabricksコントロール プレーンAPIへの内部呼び出し用
- 8444: Unity CatalogのロギングとDatabricksへのリネージ データ ストリーミング
- 次のポートで
アウトバウンドトラフィックに対して追加のALLOWまたはDENYルールを設定する場合は、Databricksが要求するルールを最高の優先度(最も小さいルール番号)に設定して、それらが優先されるようにします。
イングレス(インバウンド):
ALLOW ALL from Source 0.0.0.0/0。このルールは優先される必要があります。
Databricks では、 0.0.0.0/0 を許可リストに追加するために、サブネットレベルのネットワーク ACL が必要です。 エグレス トラフィックを制御するには、エグレス ファイアウォールまたはプロキシ アプライアンスを使用してほとんどのトラフィックをブロックしますが、Databricks が接続する必要がある URL を許可します。 ファイアウォールと送信アクセスの構成を参照してください。
AWS PrivateLink のサポート
このVPCを使用しているワークスペースでAWS PrivateLinkを有効にする場合は、次のことを行います:
- VPCで、 DNSホスト名 と DNS解決 の両方の設定が有効になっていることを確認します。
- VPC エンドポイント用の追加サブネットの作成 (推奨されますが必須ではありません) と VPC エンドポイント用の追加セキュリティ グループの作成に関するガイダンスについては、 「Databricks への従来のプライベート接続を構成する」の記事を参照してください。
VPC を作成する
VPCの作成に使用できるさまざまなツール:
- AWSコンソール
- AWS CLI
- Terraform
- Databricksワークスペースの自動作成。ワークスペースの作成時に新しい顧客管理VPCプロビジョニングします。 自動構成によるワークスペースの作成を参照してください
AWSコンソールを使用してVPCと関連オブジェクトを作成および設定するための基本的な手順を以下に示します。詳細な手順については、AWSのドキュメントを参照してください。
これらの基本的な手順がすべての組織に適用されるわけではありません。お客様の設定要件は異なる場合があります。このセクションでは、NAT、ファイアウォール、またはその他のネットワークインフラストラクチャを設定するすべての方法について説明するものではありません。ご不明な点がございましたら、先に進む前にDatabricksアカウントチームにお問い合わせください。
-
AWSのVPCページに移動します。
-
右上のリージョンピッカーを参照してください。必要に応じて、ワークスペースのリージョンに切り替えます。
-
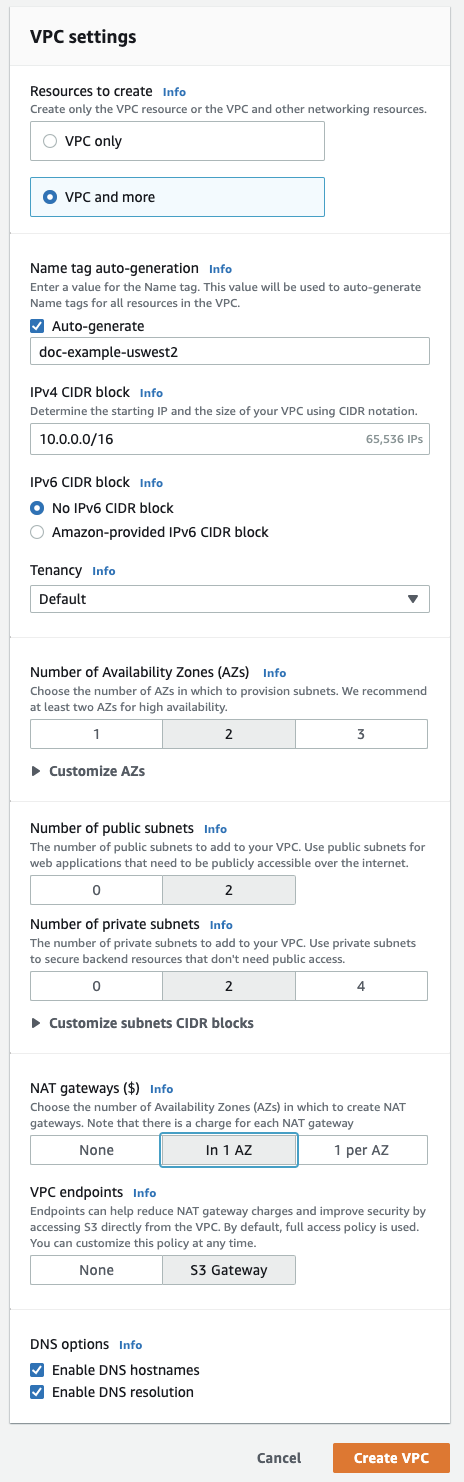
右上にあるオレンジ色のボタン[ VPCを作成する ]をクリックします。
-
[ VPCなど ]をクリックします。
-
[ ネームタグ自動生成 ]に、ワークスペースの名前を入力します。Databricksでは、名前にリージョンを含めることをお勧めしています。
-
必要に応じて、VPCアドレス範囲を変更します。
-
パブリック・サブネットの場合は、「
2」をクリックします。これらのサブネットは Databricks ワークスペースでは直接使用されませんが、このエディターで NAT を有効にするために必要です。 -
プライベートサブネットの場合は、ワークスペースサブネットの最小値として
2をクリックします。必要に応じてさらに追加できます。Databricksワークスペースには、少なくとも2つのプライベートサブネットが必要です。サイズを変更するには、 [サブネットCIDRブロックのカスタマイズ] をクリックします。
-
NATゲートウェイを使用する場合は、 1つのアベイラビリティゾーンで をクリックします。
-
下部にある[ DNSホスト名を有効化 ]フィールドと[ DNS解決を有効化 ]フィールドが有効になっていることを確認します。
-
[ VPCを作成する ]をクリックします。
-
新しいVPCを表示しているときに、左側のナビゲーションアイテムをクリックして、VPCの関連設定を更新します。[ VPCでフィルタリング ]フィールドで新しいVPCを選択することで、関連オブジェクトを見つけやすくなります。
-
[サブネット] をクリックし、AWS が 1 と 2 とラベル付けした プライベート サブネット (メインワークスペースサブネットの設定に使用するもの) をクリックします。VPC 要件で指定されているとおりにサブネットを変更します。
PrivateLink で使用するために追加のプライベート サブネットを作成した場合は、 「Databricks への従来のプライベート接続を構成する」で指定されているようにプライベート サブネット 3 を構成します。
-
セキュリティ グループ をクリックし、セキュリティ グループで指定されているセキュリティ グループを変更します。
バックエンドの PrivateLink 接続を使用する場合は、「 ステップ 1: AWS ネットワークオブジェクトを設定する」セクションの PrivateLink の記事で指定されているように、インバウンドルールとアウトバウンドルールを使用して追加のセキュリティグループを作成します。
-
[ネットワーク ACL] をクリックし、「サブネットレベルのネットワーク ACL」で指定されているとおりにネットワーク ACL を変更します。
-
この記事で後述する任意の設定を行うかどうかを選択してください。
DatabricksにVPCを登録する
VPC を作成し、必要なネットワーク オブジェクトを構成した後、Databricks アカウントのネットワーク構成で、その VPC (VPC、サブネット、セキュリティ グループなどのネットワーク オブジェクトを含む) を参照する必要があります。ネットワーク構成は、アカウント コンソールまたはアカウントAPIを使用して作成できます。
複数のワークスペース間で VPC とサブネットを共有する予定の場合は、使用量に合わせて拡張できる大きさになるように VPC とサブネットのサイズを設定してください。ネットワーク構成オブジェクトをワークスペース間で再利用することはできません。
-
アカウント コンソールで、 [セキュリティ] をクリックします。
-
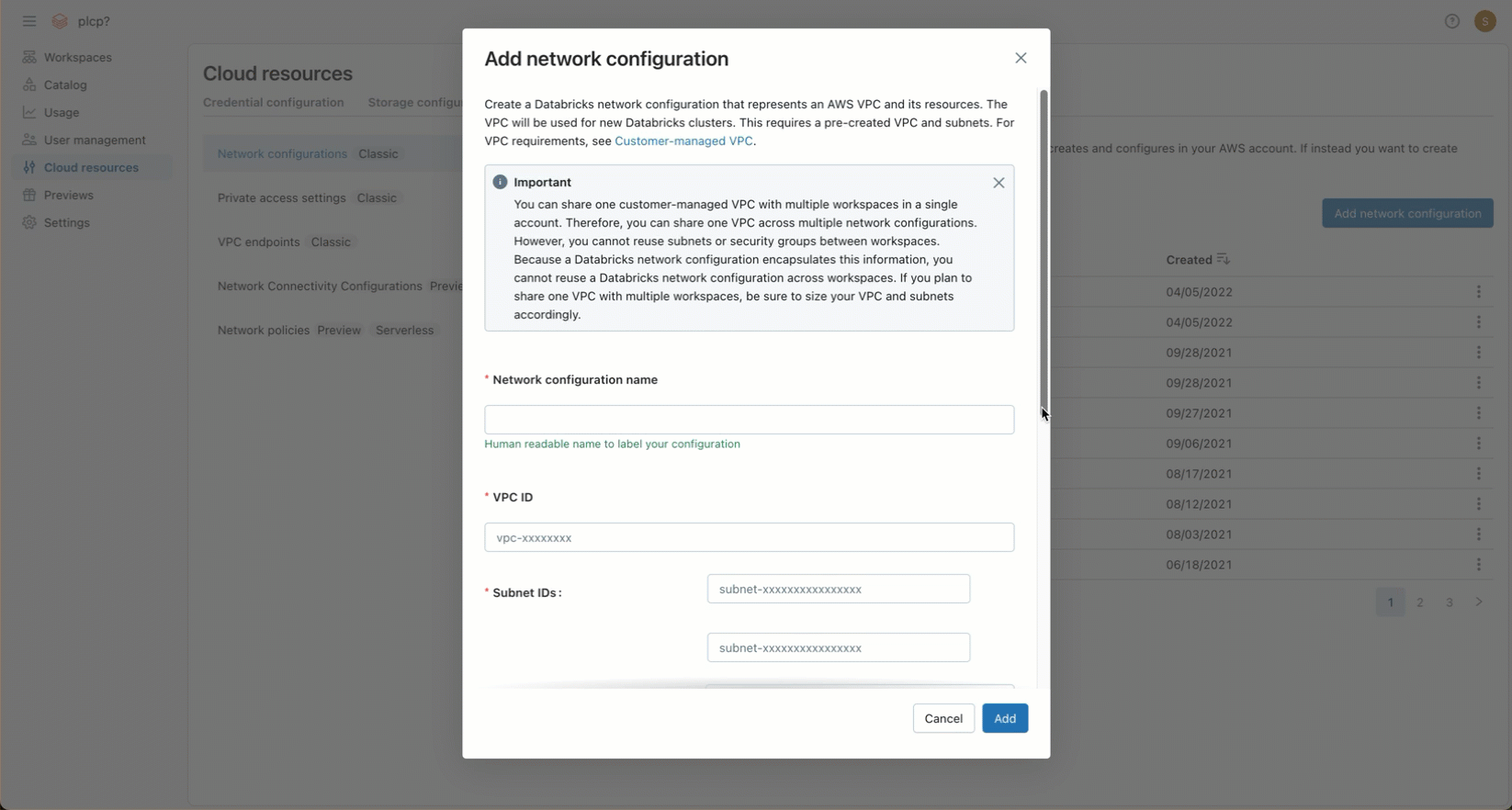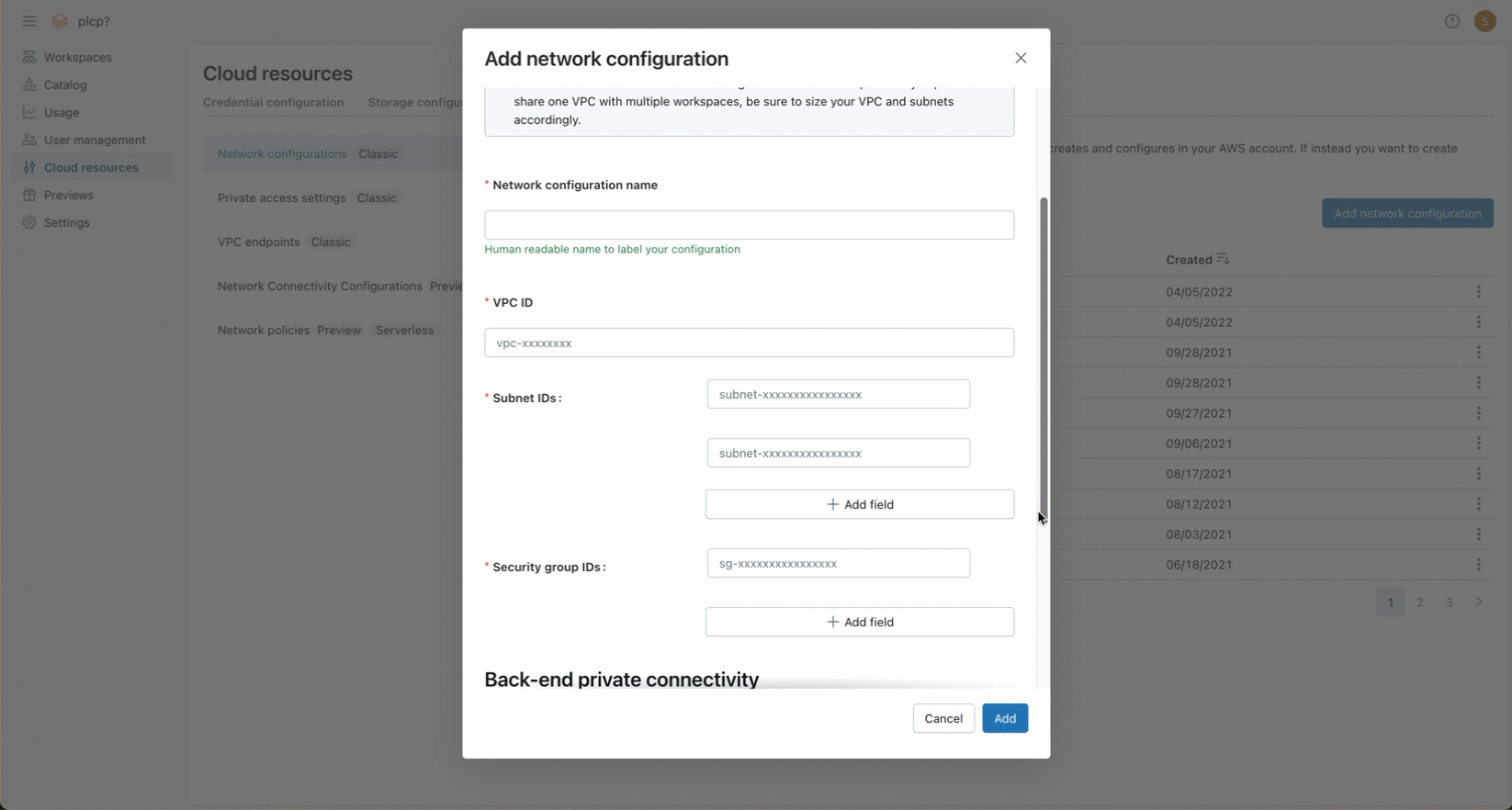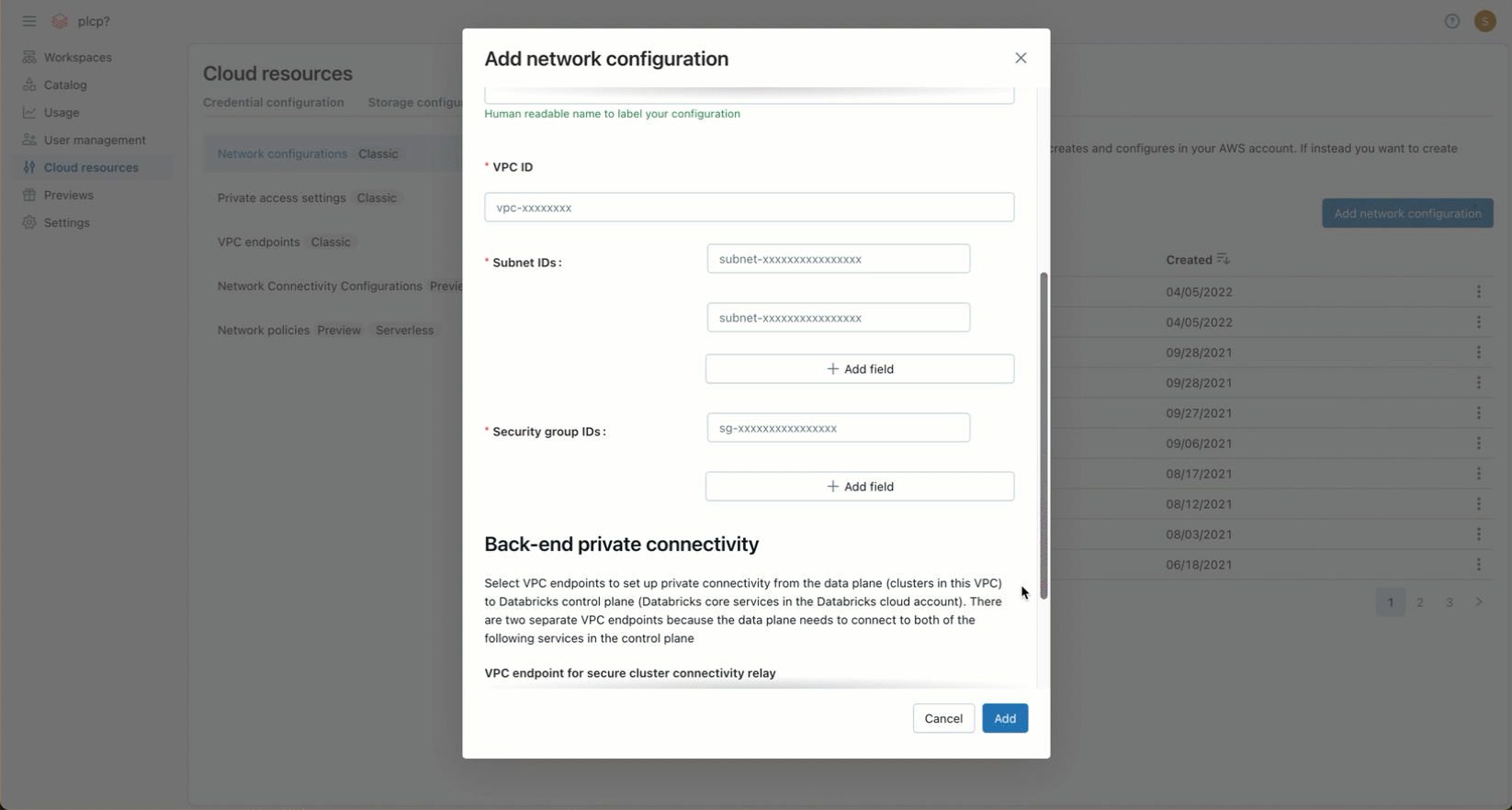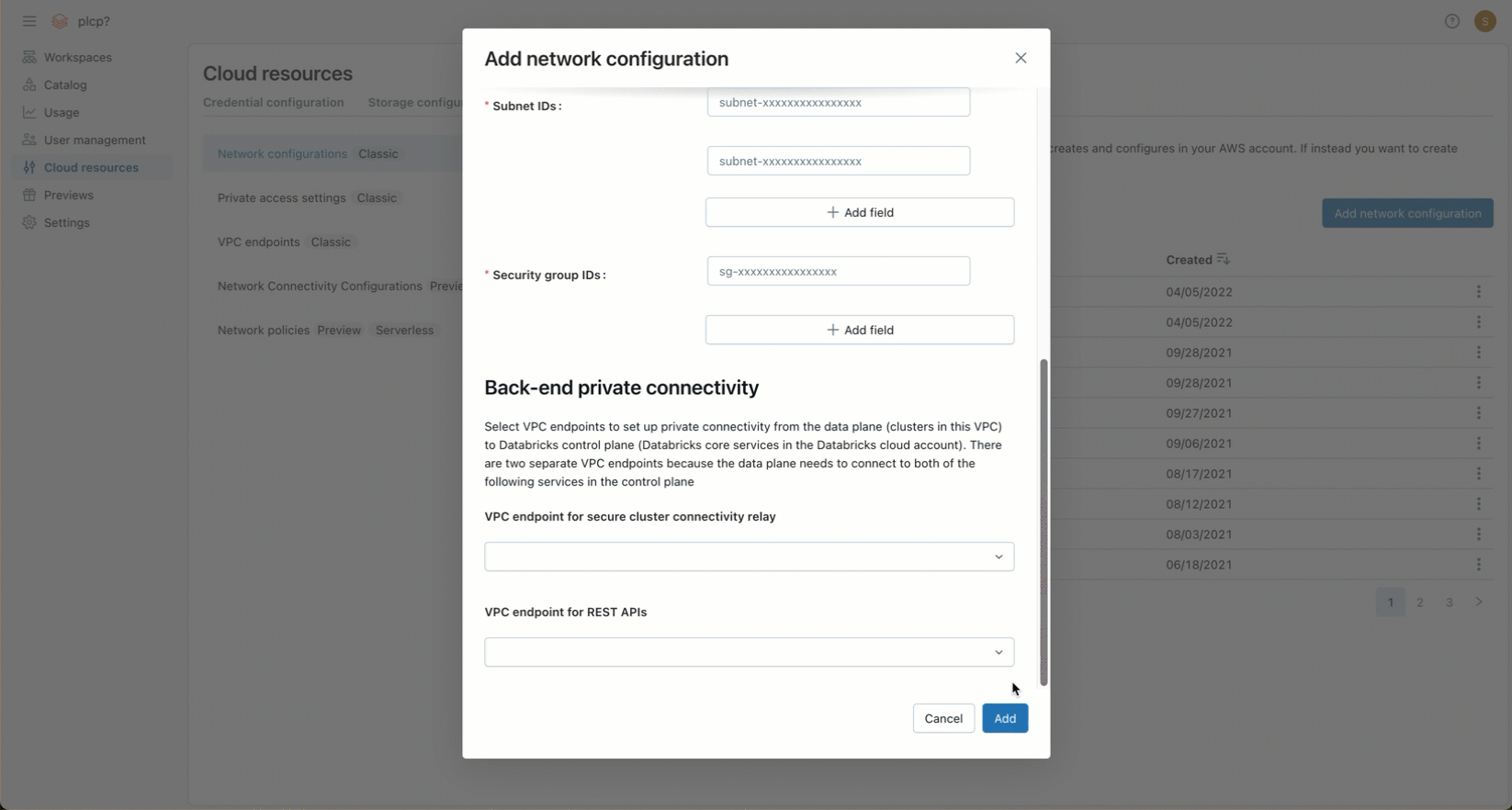
[クラシック ネットワーク構成] セクションで、 [ネットワーク構成の追加] をクリックします。
-
[ネットワーク構成名] フィールドに、新しいネットワーク構成の人間が判読できる名前を入力します。
-
[VPC ID] フィールドにVPC IDを入力します。
-
「サブネット ID」 フィールドに、VPC 内の少なくとも 2 つの AWS サブネットの ID を入力します。ネットワーク構成の要件については、 VPC の要件を参照してください。
-
[セキュリティ グループ ID] フィールドに、少なくとも 1 つのAWSセキュリティ グループの ID を入力します。 ネットワーク構成の要件については、 「セキュリティ グループ」を参照してください。
-
(オプション) AWS PrivateLink バックエンド接続をサポートするには、[ バックエンドプライベート接続 ] 見出しの下のフィールドから 2 つの VPC エンドポイント登録を選択する必要があります。
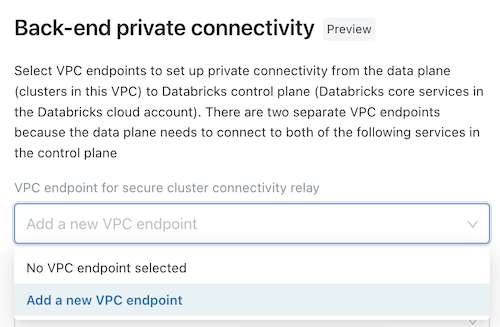
- ワークスペースリージョンに固有の 2 つの AWS VPC エンドポイントをまだ作成していない場合は、ここで作成する必要があります。 ステップ 2: VPC エンドポイントを作成するを参照してください。 AWS コンソールまたはさまざまな自動化ツールを使用できます。
- 各フィールドで、既存の VPC エンドポイント登録を選択するか、 新しい VPC エンドポイント を選択して、既に作成した AWS VPC エンドポイントを参照するエンドポイントをすぐに作成します。 フィールドのガイダンスについては、VPC エンドポイント登録の管理を参照してください。
-
[ 追加 ] をクリックします。
CIDR の更新
あとで元のサブネットと重複するサブネットCIDRの更新が必要となる場合があります。
CIDRおよびその他のワークスペースオブジェクトを更新するには、次のことを行います:
-
更新する必要があるサブネットで実行されているすべての実行中のクラスター(およびその他のコンピュートリソース)を終了します。
-
AWSコンソールを使用して、更新するサブネットを削除します。
-
更新されたCIDR範囲でサブネットを再作成します。
-
2つの新しいサブネットのルートテーブルの関連付けを更新します。各アベイラビリティゾーンのものを既存のサブネットに再利用できます。
このステップをスキップしたり、ルートテーブルを誤って設定したりすると、クラスターの起動に失敗する可能性があります。
-
新しいサブネットで新しいネットワーク設定オブジェクトを作成します。
-
この新しく作成されたネットワーク設定オブジェクトを使用するようにワークスペースを更新します
(推奨)地域エンドポイントの構成
顧客が管理するVPC(オプション)を使用する場合、Databricksでは、AWSサービスへのリージョンVPCエンドポイントのみを使用するようにVPCを構成することを推奨します。リージョンVPCエンドポイントを使用することで、AWSグローバルエンドポイントと比較して、AWSサービスへのより多くの直接接続とコスト削減が可能になります。顧客管理VPCを持つDatabricksワークスペースが到達しなければならないAWSサービスは以下の4つです: STS、S3、Kinesis、RDS。
VPCから RDS サービスへの接続は、デフォルト Databricks レガシ Hive metastoreを使用する場合にのみ必要であり、Unity Catalogメタストアには適用されません。RDS の VPC エンドポイントはありませんが、 デフォルト Databricks レガシ Hive metastoreを使用する代わりに、独自の外部メタストアを構成できます。 外部メタストアは、Hive metastore または AWS Glueを使用して実装できます。
他の3つのサービスについては、クラスターからの関連するリージョン内トラフィックがパブリックネットワークではなく、安全なAWSバックボーンを介して転送できるように、VPCゲートウェイまたはインターフェイスエンドポイントを作成できます:
-
S3 :VPCDatabricksクラスター サブネットから直接アクセスできる ゲートウェイ エンドポイント を作成します。これにより、リージョン内のすべての S3 バケットへのワークスペーストラフィックがエンドポイントルートを使用するようになります。 クロスリージョンバケットにアクセスするには、エグレスアプライアンスで S3 グローバル URL
s3.amazonaws.comへのアクセスを開くか、0.0.0.0/0を AWS インターネットゲートウェイにルーティングします。リージョン エンドポイントが有効になっている DBFS マウント を使用するには:
- クラスター設定で環境変数を設定して、
AWS_REGION=<aws-region-code>を設定する必要があります。 たとえば、ワークスペースがバージニア北部リージョンにデプロイされている場合は、AWS_REGION=us-east-1. すべてのクラスターに適用するには、 クラスターポリシーを使用します。
- クラスター設定で環境変数を設定して、
-
STS :Databricksクラスターサブネットから直接アクセスできるVPCインターフェイスエンドポイントを作成します。このエンドポイントはワークスペースのサブネットに作成できます。Databricksでは、ワークスペースVPC用に作成されたものと同じセキュリティグループを使用することをお勧めします。この構成により、STSへのワークスペーストラフィックはエンドポイントルートを使用するようになります。
-
Kinesis :VPCDatabricksクラスター サブネットから直接アクセスできる インターフェイス エンドポイント を作成します。このエンドポイントは、ワークスペース サブネットに作成できます。 Databricks では、ワークスペース VPC 用に作成されたものと同じセキュリティ グループを使用することをお勧めします。 この設定により、Kinesis へのワークスペーストラフィックはエンドポイントルートを使用します。 このルールの唯一の例外は、AWS リージョンのワークスペース
us-west-1、このリージョンのターゲット Kinesis ストリームはus-west-2リージョンとクロスリージョンであるためです。
ファイアウォールと送信アクセスを構成する
エグレスファイアウォールまたはプロキシアプライアンスを使用して、ほとんどのトラフィックをブロックし、Databricksが接続する必要のあるURLを許可します。
- ファイアウォールまたはプロキシアプライアンスがDatabricksワークスペースVPCと同じVPCにある場合は、トラフィックをルーティングし、次の接続を許可するように設定します。
- ファイアウォールまたはプロキシアプライアンスが別のVPCまたはオンプレミスネットワークにある場合は、最初に
0.0.0.0/0をそのVPCまたはネットワークにルーティングし、次の接続を許可するようにプロキシアプライアンスを設定します。
Databricksでは、宛先をIPアドレスではなく、エグレスインフラストラクチャのドメイン名として指定することを強くお勧めしています。
次の発信接続を許可します。接続タイプごとに、リンクに従ってワークスペースリージョンのIPアドレスまたはドメインを取得してください。
-
Databricks Webアプリケーション :必須。ワークスペースへのREST APIコールにも使用されます。
-
Databricksセキュリティで保護されたクラスター接続(SCC)リレー : 安全なクラスター接続に必要です。
-
AWS S3グローバルURL :DatabricksがルートS3バケットにアクセスするために必要です。リージョンに関係なく、
s3.amazonaws.com:443を使用します。 -
AWS S3 リージョン URL : オプション。 他のリージョンにある可能性のある S3 バケットを使用する場合は、S3 リージョンエンドポイントも許可する必要があります。 AWS はリージョンエンドポイント (
s3.<region-name>.amazonaws.com:443) のドメインとポートを提供していますが、Databricks では、このトラフィックが AWS ネットワークバックボーン上のプライベートトンネルを通過するように、 代わりに VPC エンドポイント を使用することをお勧めします。 「(推奨) リージョンのエンドポイントを構成する」を参照してください。 -
AWS STSグローバルURL :必須。地域に関係なく、次のアドレスとポートを使用します:
sts.amazonaws.com:443 -
AWS STS リージョナル URL : リージョナルエンドポイントへの切り替えが予想されるため、必須です。 VPC エンドポイントを使用します。 (推奨) リージョンのエンドポイントを構成するを参照してください。
-
AWS Kinesis リージョン URL : 必須。 Kinesis エンドポイントは、ソフトウェアの管理とモニタリングに必要なログをキャプチャするために使用されます。 リージョンの URL については、「 Kinesis アドレス」を参照してください。
-
テーブルメタストアRDSリージョンURL(コンピュートプレーンの地域別) :Databricks でデフォルトのHive metastoreを使用する場合は必要です。
Hive metastoreは常にコンピューティングプレーンと同じリージョンにありますが、コントロールプレーンとは異なるリージョンにある可能性があります。
デフォルト Hive metastoreを使用する代わりに、 独自のテーブルメタストアインスタンスを実装することを選択できます。その場合は、ネットワークルーティングを担当します。
-
コントロールプレーンインフラストラクチャ :必須。Databricksサービスの安定性を向上させるために、DatabricksによってスタンバイDatabricksインフラストラクチャに使用されます。
地域のエンドポイントのトラブルシューティング
上記の手順を実行してもVPCエンドポイントが意図したとおりに動作しない場合、たとえば、データソースにアクセスできない場合やトラフィックがエンドポイントをバイパスしている場合、VPCエンドポイントを使用する代わりに、2つの方法のいずれかを使用してS3およびSTSのリージョンエンドポイントのサポートを追加できます。
-
クラスター設定に
AWS_REGION環境変数を追加し、 AWS リージョンに設定します。 すべてのクラスターで有効にするには、 クラスターポリシーを使用します。 この環境変数は、DBFS マウントを使用するように既に構成されている場合があります。 -
必要なApache Spark設定を追加します。以下の方法のうち、いずれか1つを行ってください:
- それぞれのソースノートブックで :
- Scala
- Python
%scala
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
%python
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
-
あるいは、クラスターのApache Spark configで *:
spark.hadoop.fs.s3a.endpoint https://s3.<region>.amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts.<region>.amazonaws.com
- ファイアウォールやインターネットアプライアンスを使用して従来のコンピュートプレーンからの送信を制限する場合は、これらの地域のエンドポイントアドレスを許可リストに追加してください。
すべてのクラスターに対してこれらの値を設定するには、 クラスターポリシーの一部として値を構成します。
(オプション)インスタンスプロファイルを使用したS3へのアクセス
インスタンスプロファイルを使用して S3 マウントにアクセスするには、次の Spark 設定を設定します。
- 各ソースノートブックのどちらか :
- Scala
- Python
%scala
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
%python
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
-
または、 クラスターのApache Spark設定に あります:
spark.hadoop.fs.s3a.endpoint https://s3.<region>.amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts.<region>.amazonaws.com
すべてのクラスターに対してこれらの値を設定するには、 クラスターポリシーの一部として値を構成します。
S3サービスの場合、ノートブックまたはクラスターレベルで追加のリージョンエンドポイント構成を適用することには制限があります。特に、グローバルS3 URLがエグレスファイアウォールまたはプロキシで許可されていても、リージョン間のS3アクセスへのアクセスはブロックされます。Databricksの導入でリージョン間のS3アクセスが必要な場合は、Sparkの設定をノートブックまたはクラスターレベルで適用しないことが重要です。
(オプション)S3 バケットへのアクセスを制限する
S3 からの読み取りと書き込みのほとんどは、コンピュート プレーン内で自己完結型です。ただし、一部の管理操作は、Databricks によって管理されるコントロール プレーンから開始されます。S3 バケットへのアクセスを指定したソース IP アドレスのセットに制限するには、S3 バケットポリシーを作成します。バケットポリシーで、 aws:SourceIp リストに IP アドレスを含めます。VPC エンドポイントを使用する場合は、ポリシーの aws:sourceVpceに追加してアクセスを許可します。Databricks は、Databricks コントロールプレーンと同じリージョンの S3 バケットにアクセスするために VPC ID を使用し、コントロールプレーンから異なるリージョンの S3 バケットにアクセスするために NAT IP を使用します。
S3バケット ポリシーの詳細についてはAmazon S3ドキュメントのバケット ポリシーの例を参照してください。このトピックには、 実際のバケットポリシー の例も含まれています。
バケットポリシーの要件
クラスターが正しく起動し、クラスターに接続できるようにするには、バケットポリシーが次の要件を満たすことが必要です:
-
リージョンのコントロールプレーン NAT IP および VPC ID からのアクセスを許可する必要があります。
-
次のいずれかを実行して、コンピュートプレーンVPCからのアクセスを許可する必要があります:
- (推奨)顧客管理VPCでゲートウェイVPCエンドポイントを設定し、バケットポリシーの
aws:sourceVpceに追加する、または - コンピュートプレーンのNAT IPを
aws:SourceIpリストに追加します。
- (推奨)顧客管理VPCでゲートウェイVPCエンドポイントを設定し、バケットポリシーの
-
Amazon S3のエンドポイントポリシーを使用する場合 、ポリシーには以下を含める必要があります:
-
企業ネットワーク内からの接続性を失わないために 、Databricksでは企業VPNのパブリックIPなど、少なくとも1つの既知の信頼できるIPアドレスからのアクセスを常に許可することを推奨しています。これは、AWSコンソール内でも拒否条件が適用されるためです。
S3バケットポリシー制限を使用して新しいワークスペースをデプロイする場合は、us-westリージョンのコントロールプレーンNAT-IPへのアクセスを許可する必要があります。そうしないと、デプロイは失敗します。ワークスペースがデプロイされたら、us-west情報を削除し、コントロールプレーンのNAT-IPを更新してリージョンを反映できます。
必要な IP とストレージバケット
ワークスペースの S3 バケットへのアクセスを制限するために S3 バケット ポリシーと VPC エンドポイント ポリシーを構成するために必要な IP アドレスとドメインについては、Databricks コントロール プレーンからの送信 IPを参照してください。
バケットポリシーの例
これらの例では、プレースホルダーテキストを使用して、推奨される IP アドレスと必要なストレージバケットを指定する場所を示しています。 要件を確認して、クラスターが正しく開始され、それらに接続できることを確認します。
Databricksコントロールプレーン、コンピュートプレーン、信頼できるIPへのアクセスを制限
このS3バケットポリシーでは、拒否条件を使用して、指定したコントロールプレーン、NATゲートウェイ、および企業VPN IPアドレスからのアクセスを選択的に許可します。プレースホルダーのテキストを環境の値に置き換えます。ポリシーには任意の数のIPアドレスを追加できます。保護するS3バケットごとに1つのポリシーを作成します。
VPC エンドポイントを使用する場合、このポリシーは完全ではありません。 Databricks コントロール プレーン、VPC エンドポイント、信頼できる IP へのアクセスを制限するを参照してください。
{
"Sid": "IPDeny",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::<S3-BUCKET>", "arn:aws:s3:::<S3-BUCKET>/*"],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": ["<CONTROL-PLANE-NAT-IP>", "<DATA-PLANE-NAT-IP>", "<CORPORATE-VPN-IP>"]
}
}
}
Databricksコントロールプレーン、VPCエンドポイント、信頼できるIPへのアクセスを制限
VPCエンドポイントを使用してS3にアクセスする場合は、ポリシーに2つ目の条件を追加する必要があります。この条件は、VPCエンドポイントとVPC IDをaws:sourceVpceリストに追加することで、VPCエンドポイントとVPC IDからのアクセスを許可します。
このバケットは、VPCエンドポイントからのアクセス、コントロールプレーン、指定した企業VPN IPアドレスからのアクセスを選択的に許可します。
VPC エンドポイントを使用する場合は、S3 バケットポリシーの代わりに VPC エンドポイントポリシーを使用できます。 VPC ポリシーでは、ルート S3 バケットと、リージョンの必要なアーティファクト、ログ、共有データセットバケットへのアクセスを許可する必要があります。 リージョンの IP アドレスとドメインについては、「 Databricks サービスと資産の IP アドレスとドメイン」を参照してください。
プレースホルダーのテキストを環境の値に置き換えます。
{
"Sid": "IPDeny",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::<S3-BUCKET>", "arn:aws:s3:::<S3-BUCKET>/*"],
"Condition": {
"NotIpAddressIfExists": {
"aws:SourceIp": ["<CONTROL-PLANE-NAT-IP>", "<CORPORATE-VPN-IP>"]
},
"StringNotEqualsIfExists": {
"aws:sourceVpce": "<VPCE-ID>",
"aws:SourceVPC": "<VPC-ID>"
}
}
}