ストリーミングテーブル
ストリーミング テーブルは、ストリーミングまたは増分データ処理の追加サポートを備えたDeltaテーブルです。 ストリーミング テーブルは、パイプライン内の 1 つ以上のフローのターゲットにすることができます。
ストリーミング テーブルは、次の理由からデータ取り込みに適しています。
- 各入力行は 1 回だけ処理され、これにより、ほとんどの取り込みワークロード (つまり、テーブルに行を追加またはアップサートする) がモデル化されます。
- 大量の追加専用データを処理できます。
ストリーミング テーブルは、次の理由により、低遅延のストリーミング変換にも適しています。
- 列と時間の窓を越えた推論
- 大量のデータを処理する
- 低レイテンシ
次の図は、ストリーミング テーブルの仕組みを示しています。

更新のたびに、ストリーミング テーブルに関連付けられたフローは、ストリーミング ソース内の変更された情報を読み取り、新しい情報をそのテーブルに追加します。
ストリーミング テーブルは単一のパイプラインによって定義および更新されます。 パイプラインのソース コードでストリーミング テーブルを明示的に定義します。 パイプラインによって定義されたテーブルは、他のパイプラインによって変更または更新することはできません。複数のフローを定義して 1 つのストリーミング テーブルに追加できます。
Databricks SQL使用してパイプラインの外にストリーミング テーブルを作成すると、 Databricksテーブルの更新に使用されるパイプラインを作成します。 ワークスペースの左側のナビゲーションから [ジョブとパイプライン] を選択すると、パイプラインを表示できます。 ビューに パイプライン タイプ 列を追加できます。パイプラインで定義されたストリーミング テーブルのタイプはETLです。 Databricks SQLで作成されたストリーミング テーブルのタイプはMV/STです。
フローの詳細については、 「 Lakeflow Spark宣言型パイプライン フローを使用してデータを段階的にロードして処理する」を参照してください。
データ取り込みのためのストリーミングテーブル
ストリーミング テーブルは追加専用のデータ ソース用に設計されており、入力は 1 回だけ処理されます。
次の例は、ストリーミング テーブルを使用してクラウド ストレージから新しいファイルを取り込む方法を示しています。
- Python
- SQL
from pyspark import pipelines as dp
# create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
ストリーミング テーブルを作成するには、データセット定義がストリーム タイプである必要があります。 データセット定義でspark.readStream関数を使用すると、ストリーミング データセットが返されます。
-- create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
ストリーミングテーブルにはストリーミングデータセットが必要です。 read_filesの前のSTREAMキーワードは、データセットをストリームとして扱うようにクエリに指示します。
ストリーミング テーブルへのデータのロードの詳細については、 「パイプラインへのデータのロード」を参照してください。
次の図は、追加専用のストリーミング テーブルがどのように機能するかを示しています。
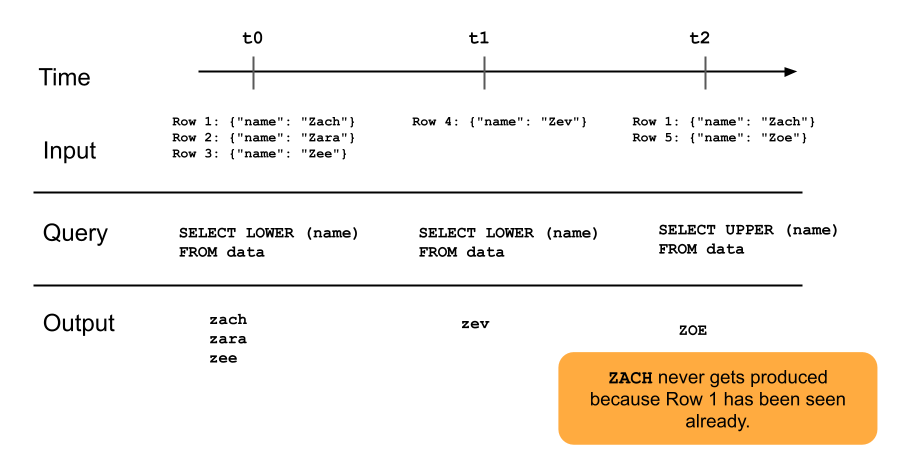
ストリーミング テーブルに既に追加されている行は、その後のパイプラインの更新によって再クエリされることはありません。 クエリを変更すると (たとえば、 SELECT LOWER (name)からSELECT UPPER (name)に)、既存の行は大文字に更新されませんが、新しい行は大文字になります。完全更新をトリガーして、ソース テーブルから以前のすべてのデータを再クエリして、ストリーミング テーブル内のすべての行を更新できます。
ストリーミングテーブルと低遅延ストリーミング
ストリーミング テーブルは、制限された状態を超えた低遅延のストリーミング用に設計されています。 ストリーミング テーブルはチェックポイント管理を使用するため、低遅延のストリーミングに適しています。 ただし、自然に制限されたストリーム、またはウォーターマークで制限されたストリームが想定されています。
自然な境界のあるストリームは、開始と終了が明確に定義されたストリーミング データソースによって生成されます。 自然な境界のあるストリームの例としては、ファイルの最初のバッチが配置された後に新しいファイルが追加されないファイルのディレクトリからデータを読み取る場合があります。 ファイルの数が有限であるため、ストリームには境界があると見なされ、すべてのファイルが処理された後にストリームが終了します。
ウォーターマークを使用してストリームを境界付けることもできます。Spark構造化ストリーミングのウォーターマークは、時間枠が完了したと見なす前にシステムが遅延イベントを待機する時間を指定することで、遅延データの処理に役立つメカニズムです。 ウォーターマークのない無制限のストリームは、メモリ不足のためにパイプラインの失敗を引き起こす可能性があります。
ステートフル ストリーム処理の詳細については、 「ウォーターマークを使用したステートフル処理の最適化」を参照してください。
ストリームスナップショットの結合
ストリーム - スナップショット結合は、ストリームと、ストリームの開始時にスナップショットが作成されるディメンションの間の結合です。 ディメンション テーブルは時点のスナップショットとして扱われ、ストリームの開始後にディメンション テーブルに加えられた変更は、ディメンション テーブルを再ロードまたは更新しない限り反映されないため、ストリームの開始後にディメンションが変更されても、これらの結合は再計算されません。結合における小さな矛盾を許容できる場合、これは妥当な動作です。たとえば、トランザクション数が顧客数よりも桁違いに多い場合には、近似結合が許容されます。
次のコード例では、ディメンション テーブル顧客と、増加し続けるデータセットの 2 つの行トランザクションを結合します。 これら 2 つのデータセット間の結合をsales_reportというテーブルに実現します。外部プロセスが新しい行 ( customer_id=3, name=Zoya ) を追加して顧客テーブルを更新した場合、ストリームの開始時に静的ディメンション テーブルのスナップショットが作成されているため、この新しい行は結合に存在しないことに注意してください。
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
ストリーミングテーブルの制限
ストリーミング テーブルには次の制限があります。
- 限定的な進化: データセット全体を再計算せずにクエリを変更できます。完全に更新しないと、ストリーミング テーブルは各行を 1 回しか参照しないため、異なるクエリが異なる行を処理することになります。 たとえば、クエリのフィールドに
UPPER()を追加すると、変更後に処理される行のみが大文字になります。つまり、データセットで実行されているクエリの以前のバージョンをすべて把握しておく必要があります。変更前に処理された既存の行を再処理するには、完全な更新が必要です。 - 状態管理: ストリーミング テーブルは低レイテンシであるため、ストリーミング テーブルが動作するストリームが自然に制限されているか、ウォーターマークで制限されていることを確認する必要があります。 詳細については、 「ウォーターマークを使用したステートフル処理の最適化」を参照してください。
- 結合は再計算されません: ストリーミングテーブル内の結合は、ディメンションが変更されても再計算されません。 この特性は、「速いが間違っている」シナリオに適しています。ビューを常に正しく表示する場合は、マテリアライズドビューを使用できます。マテリアライズドビューは、ディメンションが変更されたときに結合を自動的に再計算するため、常に正しいビューです。詳細については、 マテリアライズドビューを参照してください。