レガシービジュアライゼーション
この記事では、従来の Databricks 視覚化について説明します。SQLエディターまたはノートブックでビジュアライゼーションを作成する場合の現在のビジュアライゼーション サポートについては、 DatabricksノートブックおよびSQLエディターのビジュアライゼーション」を参照してください。 AI/BIダッシュボードでの視覚化の操作の詳細については、 AI/BI dashboard視覚化の種類」を参照してください。
Databricks は、Python と R の視覚化ライブラリもネイティブにサポートしており、サードパーティのライブラリをインストールして使用できます。
従来のビジュアライゼーションの作成
結果セルから従来のビジュアライゼーションを作成するには、「 + 」をクリックし、「 レガシービジュアライゼーション 」を選択します。
従来のビジュアライゼーションは、豊富なプロット タイプのセットをサポートしています。
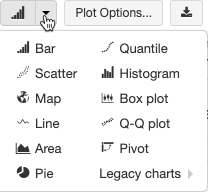
従来のグラフの種類を選択して構成する
棒グラフを選択するには、棒グラフ アイコン ![]() をクリックします。
をクリックします。

別のプロット![]() タイプを選択するには、バー チャート の右側にある
タイプを選択するには、バー チャート の右側にある![]() [] をクリックし、プロット タイプを選択します。
[] をクリックし、プロット タイプを選択します。
レガシーチャートツールバー
折れ線グラフと横棒グラフの両方に、クライアント側の豊富なインタラクションをサポートする組み込みツールバーがあります。
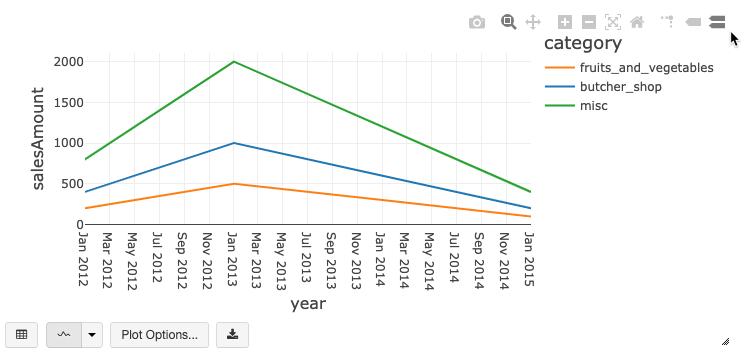
グラフを設定するには、[ プロット オプション... ] をクリックします。
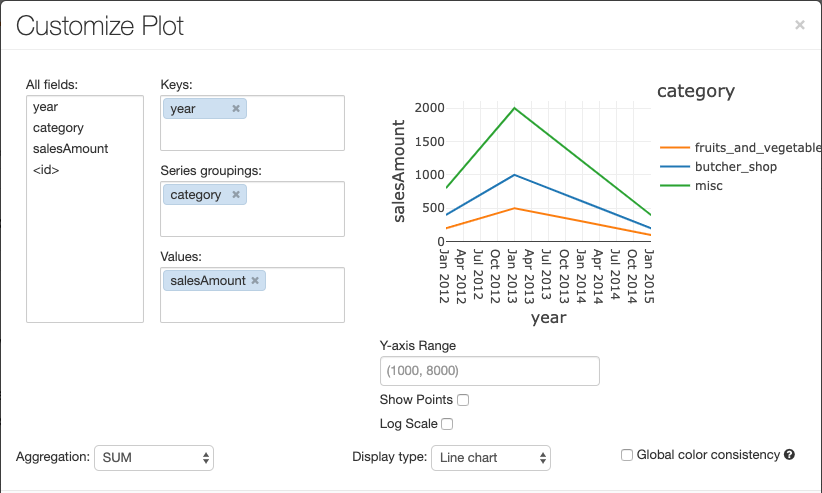
折れ線グラフには、Y 軸の範囲の設定、ポイントの表示と非表示、対数スケールでの Y 軸の表示など、いくつかのカスタム グラフ オプションがあります。
従来のグラフの種類に関する情報については、以下を参照してください。
グラフ間での色の一貫性
Databricks では、従来のグラフ間で 2 種類の色の一貫性 (シリーズ セットとグローバル) がサポートされています。
Series Set Color Consistencyは、シリーズが
同じ値で順序が異なる (たとえば、A = ["Apple", "Orange", "Banana"] と B =
["Orange", "Banana", "Apple"])。値はプロット前にソートされるため、両方の凡例がソートされます
同じ方法(["Apple", "Banana", "Orange"])で、同じ値に同じ色が与えられます。しかし
シリーズC = ["Orange", "Banana"]の場合、セットと色が一致しません
Aは、セットが同じではないからです。並べ替えアルゴリズムは、最初の色を "Banana" に割り当てます。
セットCですが、セットAでは2番目の色が「バナナ」になります。これらのシリーズを色の一貫性を持たせたい場合は、
グラフの色の一貫性をグローバルに指定できます。
グローバル カラーの一貫性では、値に関係なく、各値は常に同じ色にマップされます シリーズは持っています。各グラフでこれを有効にするには、[ グローバル色の一貫性 ] チェックボックスをオンにします。

この一貫性を実現するために、Databricks は値から色に直接ハッシュします。 避けるために 衝突 (2 つの値がまったく同じ色になる場合)、ハッシュは大量の色のセットになります。 これには、見栄えの良い色や簡単に区別できる色が保証されないという副作用があります。 多くの色で、非常によく似た外観のものがあるはずです。
機械学習の視覚化
標準のグラフ タイプに加えて、従来のビジュアライゼーションでは、次の機械学習トレーニング パラメーターと結果がサポートされています。
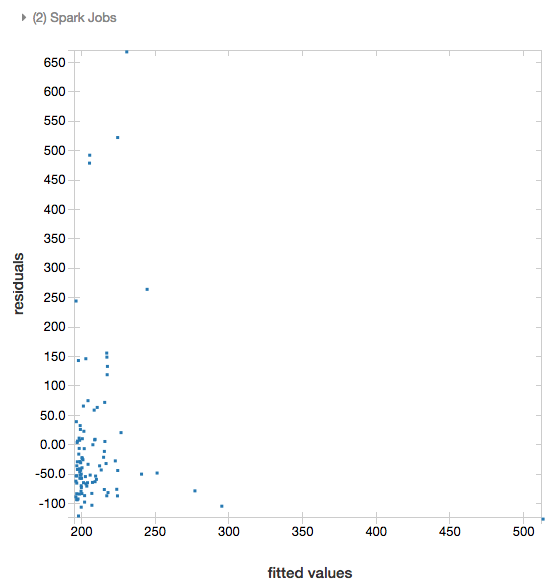
残 差
線形回帰とロジスティック回帰では、 適合値と残差 のプロットをレンダリングできます。 このプロットを取得するには、モデルと データフレーム を指定します。
次の例では、都市人口から住宅販売価格データへの線形回帰を実行し、残差と適合データを表示します。
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
ROC曲線
ロジスティック回帰では、 ROC 曲線をレンダリングできます。 このプロットを取得するには、モデル、 fit メソッドに入力される準備済みデータ、およびパラメーター "ROC"を指定します。
次の例では、個人のさまざまな属性から、個人が年間 <=50K または >50k を稼ぐかどうかを予測する分類器を開発します。 Adult データセットは国勢調査データから取得され、48842 人の個人とその年収に関する情報で構成されています。
このセクションのコード例では、ワンホット エンコードを使用しています。
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
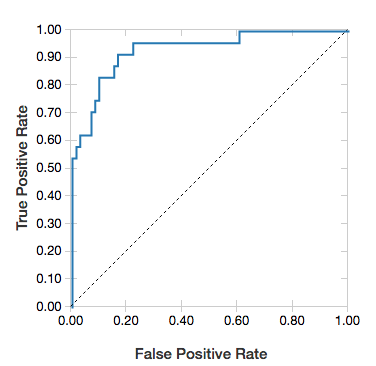
残差を表示するには、 "ROC" パラメーターを省略します。
display(lrModel, preppedDataDF)

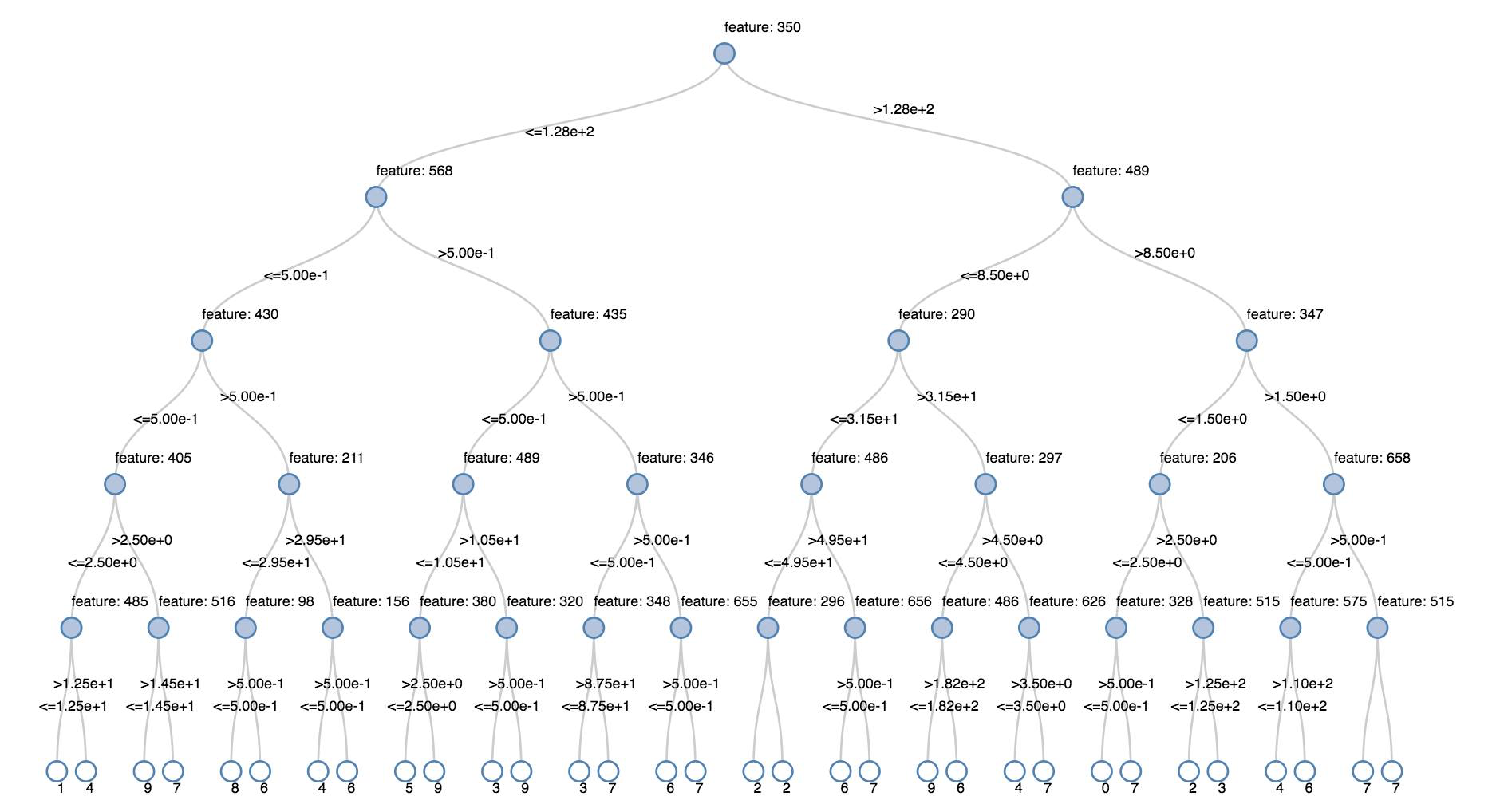
決定木
従来のビジュアライゼーションは、決定木のレンダリングをサポートします。
この視覚化を取得するには、決定木モデルを指定します。
次の例では、手書きの数字の画像の MNIST データセットから数字 (0 から 9) を認識するようにツリーをトレーニングし、ツリーを表示します。
- Python
- Scala
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
構造化ストリーミング データフレーム
ストリーミング クエリの結果をリアルタイムで視覚化するには、Scala と Python で構造化ストリーミング データフレーム display ことができます。
- Python
- Scala
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display 次のオプション・パラメーターをサポートします。
streamName: ストリーミング クエリ名。trigger(Scala) とprocessingTime(Python): ストリーミング クエリの実行頻度を定義します。 指定しない場合、前の処理が完了するとすぐに、新しいデータが利用可能かどうかがチェックされます。 本番運用のコストを削減するために、Databricks は常に トリガー間隔を設定することをおすすめします。デフォルトのトリガー間隔は 500 ミリ秒です。checkpointLocation: システムがすべてのチェックポイント情報を書き込む場所。 指定しない場合、DBFS に一時的なチェックポイント・ロケーションが自動的に生成されます。 ストリームが中断したところからデータの処理を続行するには、チェックポイントの場所を指定する必要があります。 Databricks 、本番運用では 、常にcheckpointLocationオプションを指定することを推奨しています。
- Python
- Scala
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
これらのパラメーターの詳細については、「 ストリーミング クエリの開始」を参照してください。
displayHTML 機能
Databricks プログラミング言語ノートブック (Python、R、Scala) は、 displayHTML 関数を使用した HTML グラフィックスをサポートしています。
関数には、任意の HTML、CSS、または JavaScript コードを渡すことができます。 この関数は、D3 などの JavaScript ライブラリを使用した対話型グラフィックスをサポートします。
displayHTMLの使用例については、以下を参照してください。
displayHTML iframe はドメイン databricksusercontent.comから提供され、iframe サンドボックスには allow-same-origin 属性が含まれます。databricksusercontent.com はブラウザからアクセスできる必要があります。 現在、企業ネットワークによってブロックされている場合は、許可リストに追加する必要があります。
画像
イメージ データ型を含む列は、リッチ HTML としてレンダリングされます。 Databricks は、Spark ImageSchema に一致するDataFrame列の画像サムネイルのレンダリングを試みます。サムネイルレンダリングは、 spark.read.format('image') 機能を通じて正常に読み取られた画像に対して機能します。 他の方法で生成された画像値の場合、 Databricks は 1、3、または 4 チャンネル画像 (各チャンネルが 1 バイトで構成される) のレンダリングをサポートしますが、次の制約があります。
- One-チャンネル images :
modeフィールドは 0 にする必要があります。height、width、およびnChannelsフィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。 - 3 チャンネル画像 :
modeフィールドは 16 に等しくなければなりません。height、width、およびnChannelsフィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。dataフィールド ピクセル データは 3 バイトのチャンクで含まれ、チャンネルの順序(blue, green, red)各ピクセル。 - 4 チャンネル画像 :
modeフィールドは 24 に等しくなければなりません。height、width、およびnChannelsフィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。dataフィールド ピクセル データは 4 バイトのチャンクで、チャンネルの順序は [(blue, green, red, alpha)ピクセルごとに。
例
いくつかの画像を含むフォルダがあるとします。

画像を データフレーム に読み込んでから データフレーム を表示すると、Databricks は画像のサムネイルをレンダリングします。
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Python での視覚化
このセクションの内容:
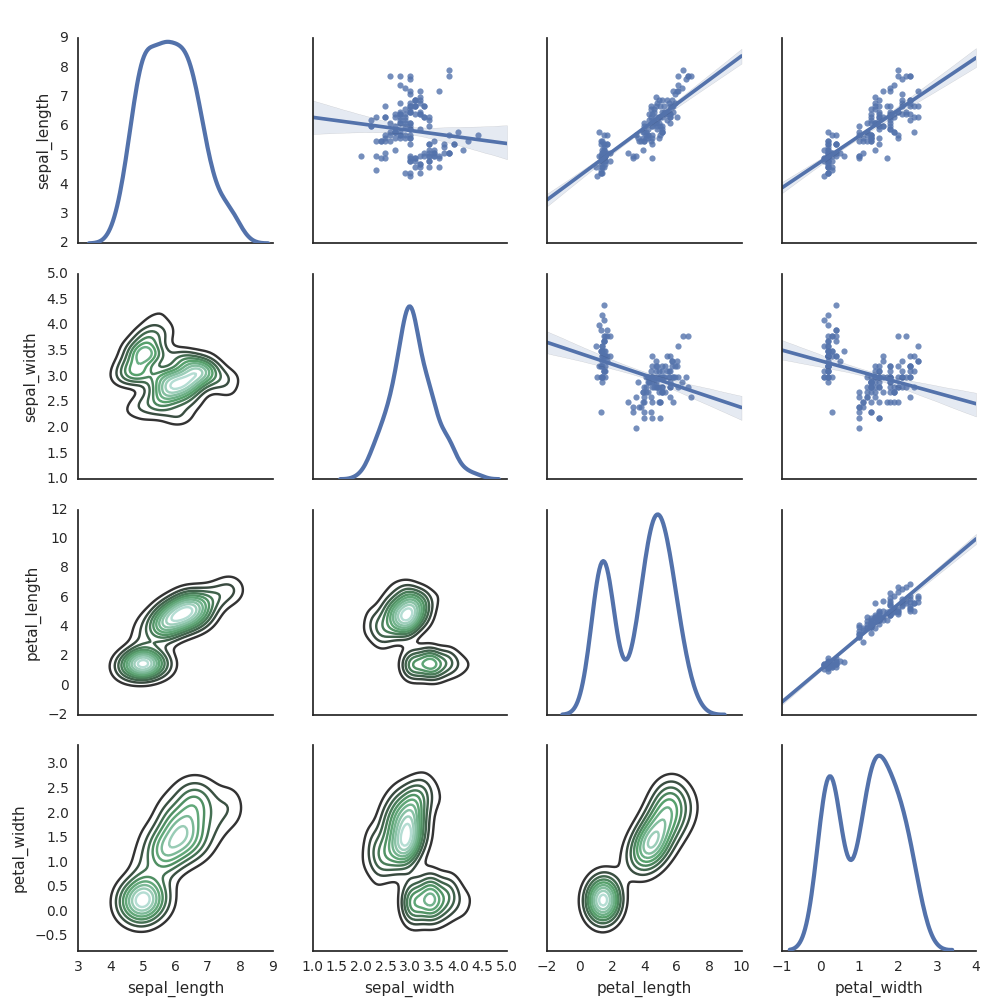
シーボーン
他の Python ライブラリを使用してプロットを生成することもできます。 Databricks Runtime には、 seaborn 視覚化ライブラリが含まれています。 seaborn プロットを作成するには、ライブラリをインポートし、プロットを作成して、プロットを display 関数に渡します。
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
その他の Python ライブラリ
R での視覚化
R でデータをプロットするには、次のように display 関数を使用します。
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
デフォルトの R プロット 関数を使用できます。
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
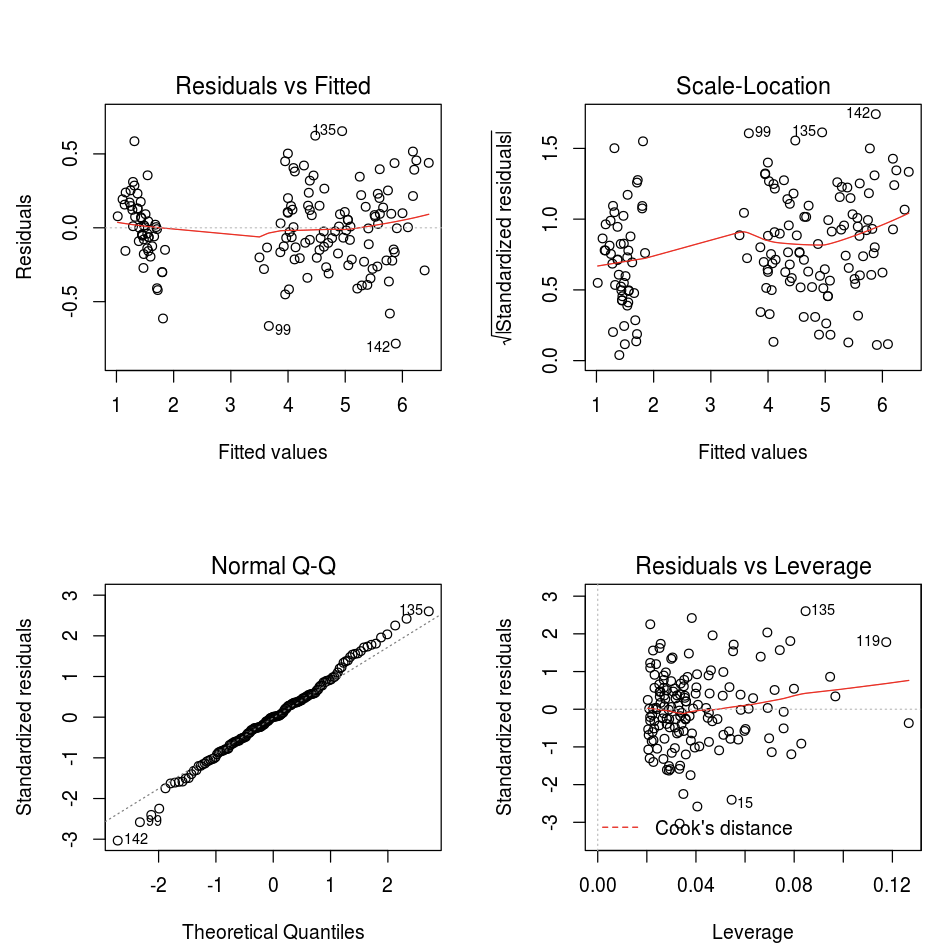
任意の R 視覚化パッケージを使用することもできます。 R ノートブックは、結果のプロットを .png としてキャプチャし、インラインで表示します。
このセクションの内容:
格子
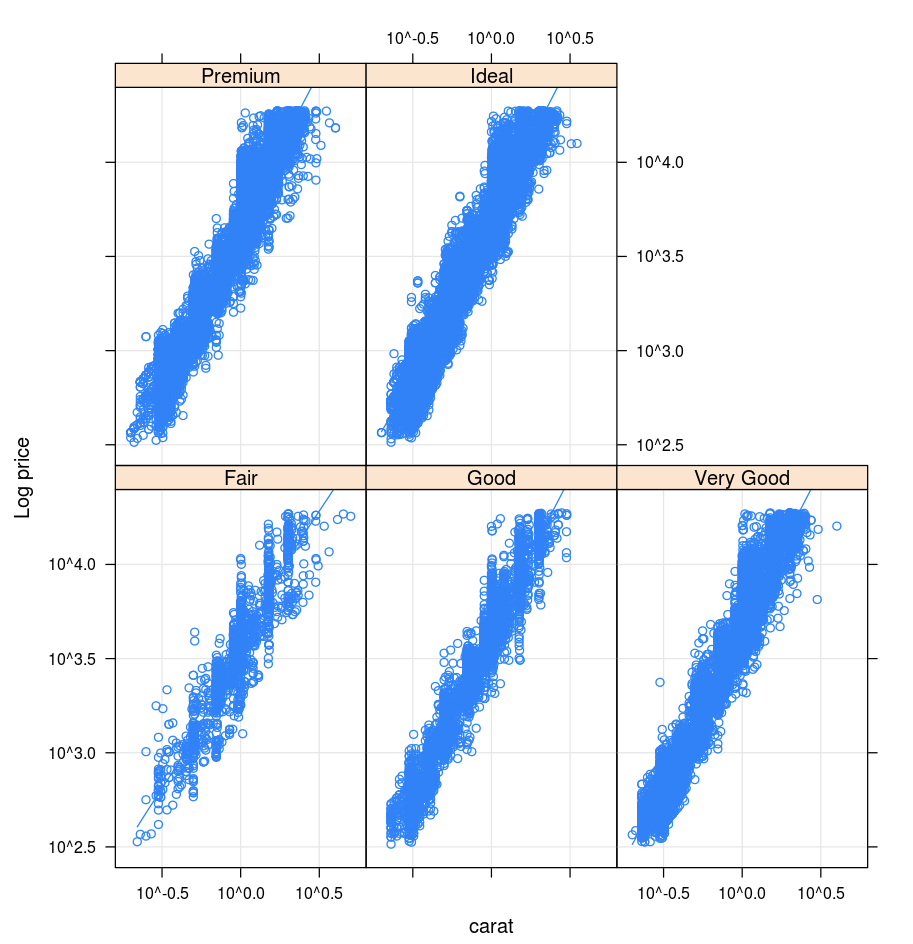
Lattice パッケージは、トレリスグラフ (1 つ以上の他の変数を条件として、変数または変数間の関係を表示するグラフ) をサポートしています。
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
ダンデファ
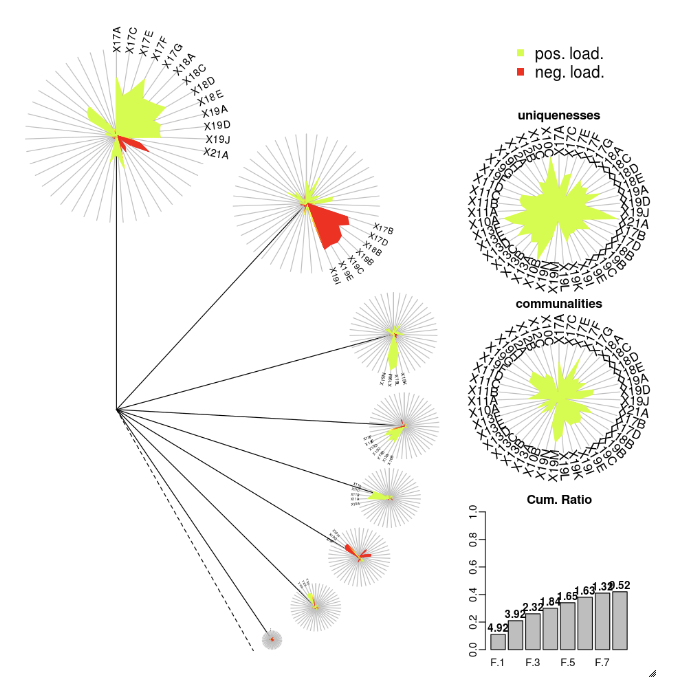
DandEFA パッケージはタンポポプロットをサポートしています。
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Plotly Rパッケージは、Rのhtmlwidgetsに依存しています。インストール手順とノートブックについては、 htmlwidgetsを参照してください。
その他の R ライブラリ
Scala でのビジュアライゼーション
Scala でデータをプロットするには、次のように display 関数を使用します。
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Python と Scala のディープダイブノートブック
Python の視覚化の詳細については、ノートブックを参照してください。
Scala の視覚化の詳細については、ノートブックを参照してください。