referência de configuração de computação
A organização deste artigo pressupõe que o senhor esteja usando o formulário simples compute UI. Para obter uma visão geral das atualizações do formulário simples, consulte Use o formulário simples para gerenciar compute.
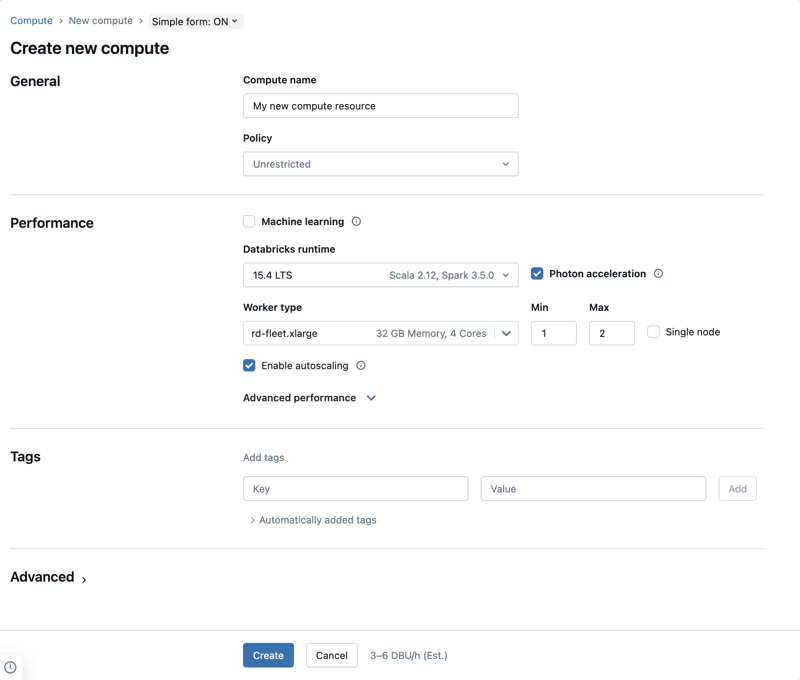
Este artigo explica as definições de configuração disponíveis ao criar um novo recurso multifuncional ou Job compute. A maioria dos usuários cria o recurso compute usando as políticas atribuídas, o que limita as definições configuráveis. Se você não vê uma configuração específica na sua interface do usuário, é porque a política que você selecionou não permite que você defina essa configuração.
Para obter recomendações sobre como configurar o site compute para sua carga de trabalho, consulte recomendações de configuração de computação.
As configurações e as ferramentas de gerenciamento descritas neste artigo se aplicam a todos os fins e ao Job compute. Para obter mais considerações sobre a configuração do Job compute, consulte Configurar compute para o Job.
Criar um novo recurso para todos os fins compute
Para criar um novo recurso de compute de uso geral:
- Na barra lateral do workspace, clique em Compute .
- Clique no botão Criar compute .
- Configure o recurso de compute.
- Clique em Criar .
Seu novo recurso de compute iniciará automaticamente e estará pronto para uso em breve.
política de computação
As políticas são um conjunto de regras usadas para limitar as opções de configuração disponíveis aos usuários quando eles criam o recurso compute. Se um usuário não tiver o direito de criação de cluster irrestrito , ele só poderá criar o recurso compute usando as políticas concedidas.
Para criar recursos de compute de acordo com uma política, selecione uma política no menu suspenso Política .
Por padrão, todos os usuários têm acesso à política Compute Pessoal , permitindo que eles criem recursos de compute de máquina única. Se você precisar de acesso ao Compute Pessoal ou a quaisquer políticas adicionais, entre em contato com o administrador do seu workspace.
Configurações de desempenho
As seguintes configurações aparecem na seção de desempenho do formulário simples compute UI:
- Databricks Runtime versões
- Use a aceleração Photon
- tipo de nó de trabalho
- Nó único compute
- Ativar dimensionamento automático
- Configurações avançadas de desempenho
Databricks Runtime versões
Databricks Runtime é o conjunto de componentes principais que são executados em seu site compute. Selecione o tempo de execução usando o menu suspenso Databricks Runtime Version . Para obter detalhes sobre versões específicas do site Databricks Runtime, consulte Databricks Runtime notas sobre versões e compatibilidade. Todas as versões incluem o Apache Spark. A Databricks recomenda o seguinte:
- Para compute de uso geral, utilize a versão mais recente para garantir que você tenha as otimizações mais recentes e a compatibilidade mais atualizada entre seu código e os pacotes pré-carregados.
- Para o Job compute que executa cargas de trabalho operacionais, considere o uso da versão do Long Term Support (LTS) Databricks Runtime. O uso da versão LTS garantirá que o senhor não tenha problemas de compatibilidade e poderá testar exaustivamente sua carga de trabalho antes de fazer o upgrade.
- Para casos de uso de ciência de dados e machine learning, considere a versão Databricks Runtime ML.
Use a aceleração Photon
O Photon está habilitado por padrão no compute executando o Databricks Runtime 9.1 LTS e superior.
Para ativar ou desativar a aceleração do Photon, marque a caixa de seleção Use Photon Acceleration (Usar aceleração do ). Para saber mais sobre o Photon, consulte O que é o Photon?
tipo de nó de trabalho
Um recurso compute consiste em um nó driver e zero ou mais nós worker. O senhor pode escolher tipos de instância de provedor de nuvem separados para os nós driver e worker, embora em default o nó driver use o mesmo tipo de instância que o nó worker. A configuração do nó do driver está abaixo da seção Desempenho avançado .
Diferentes famílias de tipos de instância se adaptam a diferentes casos de uso, como cargas de trabalho com uso intensivo de memória ou de computação. Você também pode selecionar um pool para usar como nó de worker ou driver.
Não use um pool com instâncias pontuais como seu tipo de driver. Selecione um tipo de motorista sob demanda para evitar que seu motorista seja recuperado. Consulte Conectar ao pool.
No compute multinó, os nós worker executam os executores do Spark e outros serviços necessários para um recurso de compute funcionando corretamente. Quando você distribui sua carga de trabalho com o Spark, todo o processamento distribuído acontece nos nós worker. O Databricks executa um executor por nó worker. Portanto, os termos executor e worker são usados alternadamente no contexto da arquitetura do Databricks.
Para executar um trabalho do Spark, você precisa de pelo menos um nó de worker. Se o recurso de compute tiver zero workers, você poderá executar comandos não Spark no nó do driver, mas os comandos Spark falharão.
Tipos de nós flexíveis
Se o seu workspace tiver tipos de nós flexíveis ativados, você poderá usar tipos de nós flexíveis para o seu recurso compute . Os tipos de nós flexíveis permitem que seu recurso compute utilize tipos de instância alternativos e compatíveis quando o tipo de instância especificado não estiver disponível. Esse comportamento melhora a confiabilidade do lançamento compute , reduzindo as falhas de capacidade durante os lançamentos compute . Consulte Melhorar a confiabilidade de inicialização compute usando tipos de nós flexíveis.
endereços IP do nó de trabalho
Databricks lança worker nós com dois endereços IP privados cada. O endereço IP privado primário do nó hospeda o tráfego interno da Databricks. O endereço IP privado secundário é usado pelo contêiner Spark para comunicação intra-cluster. Esse modelo permite que o Databricks forneça isolamento entre vários recursos do compute no mesmo workspace.
Tipos de instância de GPU
Para tarefas computacionalmente desafiadoras que exigem alto desempenho, como as associadas à aprendizagem profunda, o site Databricks suporta o recurso compute que é acelerado com unidades de processamento gráfico (GPUs). Para obter mais informações, consulte GPU-enabled compute.
A Databricks não oferece mais suporte à inicialização de compute usando instâncias Amazon EC2 P2.
Tipos de instância do AWS Graviton
O Databricks oferece suporte a instâncias do AWS Graviton. Essas instâncias usam processadores Graviton projetados pela AWS com base na arquitetura de conjunto de instruções Arm64. A AWS afirma que os tipos de instância com esses processadores têm a melhor relação preço/desempenho de todos os tipos de instância no Amazon EC2. Para usar os tipos de instância do Graviton, selecione um dos tipos de instância do AWS Graviton disponíveis para o tipo de worker , tipo de driver ou ambos.
A Databricks oferece suporte a compute habilitado para AWS Graviton:
- Em Databricks Runtime 9.1 LTS e acima para nãoPhoton, e Databricks Runtime 10.2 (EoS) e acima para Photon.
- No Databricks Runtime 15.4 LTS para aprendizado de máquina para o Databricks Runtime para aprendizado de máquina.
- Em todas as regiões da AWS. Observe, no entanto, que nem todos os tipos de instância estão disponíveis em todas as regiões. Se você selecionar um tipo de instância que não está disponível na região de um workspace, a criação do compute falhará.
- Para processadores AWS Graviton2 e Graviton3.
O pipeline declarativo LakeFlow Spark não é compatível com compute habilitada para Graviton .
Limitações do ARM64 ISA
- Alterações de precisão de ponto flutuante: operações típicas como adicionar, subtrair, multiplicar e dividir não têm alteração na precisão. Para funções de triângulo único, como
sinecos, o limite superior da diferença de precisão para instâncias da Intel é1.11e-16. - Compatibilidade com terceiros: a alteração no ISA pode ter algum impacto na compatibilidade com ferramentas e bibliotecas de terceiros.
- Compute de instâncias mistas: a Databricks não suporta a mistura de tipos de instância AWS Graviton e não AWS Graviton, pois cada tipo requer um Databricks Runtime diferente.
Graviton limitações
Os seguintes recursos não são compatíveis com os tipos de instância AWS Graviton:
- UDFs em Python (UDFs em Python estão disponíveis no Databricks Runtime 15.2 e versões superiores)
- Databricks Container Services
- Pipeline declarativo LakeFlow Spark
- Databricks SQL
- Databricks on AWS GovCloud
- Acesso a arquivos do workspace, incluindo aqueles em pastas Git, a partir de terminais web.
Tipos de instância do AWS Fleet
Se o seu workspace foi criado antes de maio de 2023, as permissões do IAM role talvez precisem ser atualizadas para permitir o acesso aos tipos de instância da frota. Para obter mais informações, consulte Ativar tipos de instância de frota.
Um tipo de instância de frota é um tipo de instância variável que é resolvido automaticamente para o melhor tipo de instância disponível do mesmo tamanho.
Por exemplo, se você selecionar o tipo de instância de frota m-fleet.xlarge, seu nó será resolvido para qualquer tipo de instância de propósito geral .xlarge que tiver a melhor capacidade de spot e preço naquele momento. O tipo de instância para o qual seu recurso de compute é resolvido sempre terá a mesma memória e número de núcleos que o tipo de instância de frota que você escolheu.
Os tipos de instância de frota usam AWS o Spot Placement Score do API para escolher a zona de disponibilidade melhor e com maior probabilidade de sucesso para o seu compute recurso no startup momento.
Limitações da frota
- Se o senhor atualizar a porcentagem de lance da instância spot usando API ou JSON, isso não terá efeito quando o tipo de nó worker for definido como um tipo de instância de frota. Isso ocorre porque não há uma única instância sob demanda para usar como ponto de referência para o preço à vista.
- Instâncias de frota não suportam instâncias de GPU.
- Uma pequena porcentagem de espaços de trabalho mais antigos ainda não é compatível com os tipos de instância de frota. Se esse for o caso do seu workspace, o senhor verá um erro indicando isso ao tentar criar compute ou uma instância pool usando um tipo de instância de frota. Estamos trabalhando para oferecer suporte a esses espaços de trabalho restantes.
Nó único compute
A caixa de seleção Single node (Nó único ) permite que o senhor crie um único nó compute recurso.
O compute de nó único destina-se a jobs que usam pequenas quantidades de dados ou cargas de trabalho não distribuídas, como bibliotecas de aprendizado de máquina de nó único. O compute multinó deve ser usado para jobs maiores com cargas de trabalho distribuídas.
Propriedades de um único nó
Um recurso de compute de nó único tem as seguintes propriedades:
- Executa o Spark localmente.
- O driver atua como mestre e worker, sem nós worker.
- Gera uma thread executor por núcleo lógico no recurso de compute, menos 1 núcleo para o driver.
- Salva todas as saídas de log
stderr,stdoutelog4jno log do driver. - Não pode ser convertido em um recurso de vários nós compute.
Seleção de um ou vários nós
Considere seu caso de uso ao decidir entre compute de nó único ou multinó:
-
O processamento de dados em grande escala esgotará os recursos em um recurso de compute de nó único. Para essas cargas de trabalho, a Databricks recomenda o uso de compute multinó.
-
Um recurso de vários nós compute não pode ser dimensionado para 0 trabalhador. Em vez disso, use o nó único compute.
-
O agendamento de GPU não está habilitado no compute de nó único.
-
Em compute de nó único, o Spark não consegue ler arquivos Parquet com uma coluna UDT. A seguinte mensagem de erro é exibida:
ConsoleThe Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Para contornar esse problema, desative o leitor Parquet nativo:
Pythonspark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Habilitar a autoescala
Quando a opção Ativar autoscale está marcada, você pode fornecer um número mínimo e máximo de workers para o recurso de compute. O Databricks então escolhe o número apropriado de workers necessários para executar seu job.
Para definir o número mínimo e máximo de trabalhadores que seu recurso compute irá autoscale entre, use os campos Min e Max ao lado do tipo de trabalhador dropdown.
Se o senhor não ativar a autoescala, deverá inserir um número fixo de trabalhadores no campo trabalhador ao lado do tipo de trabalhador dropdown.
Quando o recurso de compute está em execução, a página de detalhes de compute exibe o número de workers alocados. Você pode comparar o número de workers alocados com a configuração do worker e fazer os ajustes necessários.
Benefícios da autoescala
Com o autoscale, o Databricks realoca dinamicamente o trabalhador para o account de acordo com as características do seu trabalho. Certas partes do seu pipeline podem exigir mais computação do que outras, e o Databricks adiciona automaticamente um trabalhador adicional durante essas fases do seu trabalho (e os remove quando não são mais necessários).
O autoscale facilita a obtenção de alta utilização porque o senhor não precisa provisionar o compute para corresponder a uma carga de trabalho. Isso se aplica especialmente a cargas de trabalho cujos requisitos mudam com o tempo (como explorar um site dataset ao longo de um dia), mas também pode se aplicar a uma carga de trabalho única e mais curta cujos requisitos de provisionamento são desconhecidos. Assim, a autoescala oferece duas vantagens:
- As cargas de trabalho podem ser executadas mais rapidamente em comparação com um recurso de compute subprovisionado de tamanho constante.
- O autoscale pode reduzir os custos gerais em comparação com um recurso de compute de tamanho estático.
Dependendo do tamanho constante do recurso de compute e da carga de trabalho, o autoscale oferece um ou ambos os benefícios ao mesmo tempo. O tamanho do compute pode ficar abaixo do número mínimo de workers selecionados quando o provedor de nuvem encerra as instâncias. Nesse caso, o Databricks tenta continuamente provisionar novamente as instâncias para manter o número mínimo de workers.
O autoscale não está disponível para jobs spark-submit.
O dimensionamento automático de computação tem limitações na redução do tamanho cluster para cargas de trabalho de transmissão estruturada. Databricks recomenda o uso do pipeline declarativo LakeFlow Spark com escalonamento automático aprimorado para cargas de trabalho de transmissão. Consulte Otimizar a utilização cluster do pipeline declarativo LakeFlow Spark com escalonamento automático.
Como a autoescala se comporta
Workspace no plano Premium ou superior usam autoscale otimizado. Workspaces no plano de preços padrão usam autoscale padrão.
O autoscale otimizado tem as seguintes características:
- Aumenta de mínimo a máximo em 2 passos.
- Pode reduzir a escala, mesmo se o recurso de compute não estiver ocioso, observando o estado do arquivo shuffle.
- Reduz com base em uma porcentagem dos nós atuais.
- No compute de job, reduz a escala se o recurso de compute estiver subutilizado nos últimos 40 segundos.
- No compute de uso geral, reduz a escala se o recurso de compute estiver subutilizado nos últimos 150 segundos
- A propriedade de configuração
spark.databricks.aggressiveWindowDownSdo Spark especifica em segundos com que frequência o cálculo toma decisões de redução de escala. Aumentar o valor faz com que o compute diminua mais lentamente. O valor máximo é 600.
O autoscale padrão é usado em workspaces de plano padrão. O autoscale padrão tem as seguintes características:
- Começa adicionando 8 nós. Então escala exponencialmente, realizando tantos passos quantos forem necessários para atingir o máximo.
- Reduz quando 90% dos nós não estão ocupados por 10 minutos e o compute está ocioso há pelo menos 30 segundos.
- Reduz exponencialmente, começando com 1 nó.
autoscale com piscina
Se estiver anexando seu recurso de compute a um pool, considere o seguinte:
-
Certifique-se de que o tamanho do compute solicitado seja menor ou igual ao número mínimo de instâncias do parado no pool. Se for maior, o tempo de compute startup será equivalente ao de compute que não usa um pool.
-
Certifique-se de que o tamanho máximo do compute seja menor ou igual à capacidade máxima do pool. Se for maior, a criação do compute falhará.
exemplo de autoescala
Se você reconfigurar um recurso de compute estático para autoscale, o Databricks redimensiona imediatamente o recurso de compute dentro dos limites mínimo e máximo e, em seguida, inicia o autoscale. Como exemplo, a tabela a seguir demonstra o que acontece com um recurso de compute com um determinado tamanho inicial se você reconfigurar o recurso de compute para autoscale entre 5 e 10 nós.
Tamanho inicial | Tamanho após a reconfiguração |
|---|---|
6 | 6 |
12 | 10 |
3 | 5 |
Configurações avançadas de desempenho
As seguintes configurações aparecem na seção Advanced desempenho no formulário simples compute UI.
Instâncias pontuais
O senhor pode especificar se deseja usar instâncias pontuais marcando a caixa de seleção Usar instância pontual em Desempenho avançado . Veja os preços spot da AWS.
A primeira instância sempre estará sob demanda (o nó do driver está sempre sob demanda) e as instâncias subsequentes serão instâncias spot.
Rescisão automática
O senhor pode definir o encerramento automático para compute na seção Desempenho avançado . Durante a criação do site compute, especifique um período de inatividade em minutos após o qual o senhor deseja que o recurso compute seja encerrado.
Se a diferença entre a hora atual e a última execução de comando no recurso compute for maior do que o período de inatividade especificado, o site Databricks encerrará automaticamente esse recurso compute. Para obter mais informações sobre o encerramento do site compute, consulte Terminate a compute.
Tipo de motorista
O senhor pode selecionar o tipo de driver na seção Desempenho avançado . O nó do driver mantém as informações de estado de todos os notebooks anexados ao recurso compute. O nó driver também mantém o SparkContext, interpreta todos os comandos que o senhor executa a partir de um Notebook ou de uma biblioteca no recurso compute e executa o mestre Apache Spark que coordena o executor Spark.
O valor padrão do tipo de nó do driver é o mesmo que o tipo de nó do worker. Você pode escolher um tipo de nó de driver maior com mais memória se estiver planejando collect() muitos dados de workers do Spark e analisá-los no notebook.
Como o nó do driver mantém todas as informações de estado dos notebooks conectados, desanexe os notebooks não utilizados do nó do driver.
Etiquetas
As tags permitem que o senhor monitore facilmente o custo do recurso compute usado por vários grupos da sua organização. Especifique as tags como par key-value quando o senhor criar o compute, e o Databricks aplicará essas tags aos recursos de nuvem, como VMs e volumes de disco, bem como ao uso do Databricks logs.
Para compute iniciado a partir de pools, as tags personalizadas são aplicadas apenas aos relatórios de uso de DBU e não se propagam para os recursos da nuvem.
Para obter informações detalhadas sobre como os tipos de tags pool e compute funcionam juntos, consulte Usar tags para atribuir e rastrear o uso
Para adicionar tags ao seu recurso de compute:
- Na seção Tags , adicione um par key-value para cada tag personalizada.
- Clique em Adicionar .
Configurações avançadas
As seguintes configurações aparecem na seção Advanced (Avançado ) do formulário simples compute UI:
- Modos de acesso
- Perfiis de instância
- Zonas de disponibilidade
- Blocos de capacidade da AWS
- Ativar dimensionamento automático do armazenamento local
- Volumes do EBS
- Criptografia de disco local
- Configuração do Spark
- Variáveis de ambiente
- computar log delivery
Modos de acesso
O modo de acesso é um recurso de segurança que determina quem pode usar o recurso compute e os dados que podem ser acessados usando o recurso compute. Cada recurso do site compute em Databricks tem um modo de acesso. As configurações do modo de acesso podem ser encontradas na seção Advanced (Avançado ) do formulário simples compute UI.
A seleção do modo de acesso é feita automaticamente pelo site default, o que significa que o modo de acesso é escolhido automaticamente para o senhor com base no site selecionado Databricks Runtime. O padrão automático é Standard , a menos que um tempo de execução machine learning ou um Databricks Runtimes inferior a 14.3 seja selecionado; nesse caso, o Dedicated é usado.
A Databricks recomenda que o senhor use o modo de acesso padrão, a menos que a funcionalidade necessária não seja suportada.
Modo de acesso | Descrição | Idiomas suportados |
|---|---|---|
Standard | Pode ser usado por vários usuários com isolamento de dados entre os usuários. | Python, SQL, Scala |
Dedicado | Pode ser atribuído e usado por um único usuário ou grupo. | Python, SQL, Scala, R |
Para obter informações detalhadas sobre o suporte à funcionalidade de cada um desses modos de acesso, consulte Requisitos e limitações do Standard compute e Requisitos e limitações do Dedicated compute.
Em Databricks Runtime 13.3 LTS e acima, o script de inicialização e a biblioteca são suportados por todos os modos de acesso. Os requisitos e os níveis de suporte variam. Consulte Onde o script de inicialização pode ser instalado? e biblioteca com escopo de computação.
perfil da instância
Databricks recomenda usar os locais externos de Unity Catalog para se conectar a S3 em vez do perfil da instância. Unity Catalog simplifica a segurança e a governança de seus dados, fornecendo um local central para administrar e auditar o acesso aos dados em vários espaços de trabalho em seu account. Consulte Conectar-se ao armazenamento de objetos na nuvem usando o Unity Catalog.
Para acessar com segurança o AWS recurso sem usar a chave AWS, o senhor pode iniciar o Databricks compute com o perfil da instância. Consulte o tutorial: Configure o acesso S3 com um instance profile para obter informações sobre como criar e configurar o perfil da instância. Depois de criar um instance profile, o senhor o seleciona na lista suspensa do perfil da instância .
Após iniciar seu recurso de compute, verifique se você pode acessar o bucket S3 usando o seguinte comando. Se o comando for bem-sucedido, esse recurso de compute poderá acessar o bucket S3.
dbutils.fs.ls("s3a://<s3-bucket-name>/")
Quando um recurso compute é iniciado com um instance profile, qualquer pessoa que tenha permissões de anexação a esse recurso compute pode acessar o recurso subjacente controlado por essa função. Para se proteger contra acesso indesejado, use as permissões de computação para restringir as permissões ao recurso compute.
Zonas de disponibilidade
Para localizar a configuração da zona de disponibilidade, abra a seção Advanced e clique em Instances (Instâncias ) tab. Essa configuração permite que o senhor especifique qual zona de disponibilidade (AZ) deseja que o recurso compute use. Em default, essa configuração é definida como automática , em que a AZ é selecionada automaticamente com base nos IPs disponíveis nas sub-redes workspace. O Auto-AZ tenta novamente em outras zonas de disponibilidade se o AWS retornar erros de capacidade insuficiente.
A opção "auto" para AZ funciona apenas na inicialização do compute. Após o recurso de compute ser iniciado, todos os nós permanecem na zona de disponibilidade original até que o recurso de compute seja encerrado ou reiniciado.
A escolha de uma AZ específica para o recurso compute é útil principalmente se a sua organização tiver adquirido instâncias reservadas em zonas de disponibilidade específicas. Leia mais sobre as zonas de disponibilidade do AWS na documentação do AWS.
HA (zona de alta disponibilidade) é uma configuração de AZ obsoleta. O HA resolve ser automático em segundo plano.
Blocos de capacidade da AWS
Os blocos de capacidadeAWS permitem que você reserve capacidade compute para um período específico em uma AZ específica. Para usar Blocos de Capacidade com Databricks compute, configure seu recurso compute com uma tag e zona de disponibilidade específicas.
-
Compre um bloco de capacidade no seu portal da AWS. Para obter detalhes, consulte a documentação da AWS sobre a compra de um Bloco de Capacidade.
- Certifique-se de que o número total de instâncias seja suficiente para o uso esperado.
- Observe a zona de disponibilidade que a AWS atribui à sua reserva do Bloco de Capacidade.
- Verifique se seu workspace tem uma sub-rede na mesma zona de disponibilidade que o Bloco de Capacidade.
- Copie o ID do bloco de capacidade da AWS para uso na configuração do Databricks.
-
Quando chegar o momento de ativação da reserva do bloco de capacidade, crie um recurso compute Databricks com as seguintes configurações:
-
Adicione uma tag com o seguinte:
- chave :
X-Databricks-AwsCapacityBlockId - Valor : Seu ID de bloco de capacidade da AWS Configure todos os nós para usar instâncias sob demanda:
- chave :
-
Em Desempenho avançado , desmarque a caixa de seleção Usar instâncias pontuais .
-
Em Avançado > Instâncias , selecione a zona de disponibilidade específica atribuída ao seu Bloco de Capacidade.
-
-
Conclua sua configuração compute e clique em Criar .
Os Blocos de Capacidade devem estar ativos antes que você possa iniciar o recurso compute usando-os. Verifique o horário de ativação da sua reserva do Capacity Block no portal da AWS.
Ativar o armazenamento local de escala automática
Para configurar a opção Enable autoscale local storage (Ativar armazenamento local de autoescala ), abra a seção Advanced (Avançado ) e clique em Instances (Instâncias ) tab.
Se o senhor não quiser alocar um número fixo de volumes EBS no momento da criação do site compute, use o armazenamento local de escala automática. Com o armazenamento local de escala automática, o siteDatabricks monitora a quantidade de espaço livre em disco disponível compute Spark no worker do site. Se um worker começar a ficar com pouco espaço em disco, o Databricks anexará automaticamente um novo volume EBS ao worker antes que ele fique sem espaço em disco. Os volumes do EBS são anexados até um limite de 5 TB de espaço total em disco por instância (incluindo o armazenamento local da instância).
Os volumes EBS anexados a uma instância são desanexados somente quando a instância é devolvida ao AWS. Ou seja, os volumes EBS nunca são desvinculados de uma instância enquanto ela fizer parte de uma instância em execução compute. Para reduzir o uso do EBS, o site Databricks recomenda o uso desse recurso em compute configurado com autoscale compute ou encerramento automático.
A Databricks usa volumes do Amazon EBS GP3 para ampliar o armazenamento local de uma instância. O limite de capacidade dodefault AWS para esses volumes é de 50 TiB. Para evitar atingir esse limite, os administradores devem solicitar um aumento desse limite com base em seus requisitos de uso.
Volumes do EBS
Esta seção descreve as configurações padrão de volume EBS para nós worker, como adicionar volumes de shuffle e como configurar o compute para que o Databricks aloque automaticamente volumes EBS.
Para configurar os volumes EBS, o site compute não deve estar habilitado para o armazenamento local de autoescala. Clique em Instances (Instâncias ) tab em Advanced (Avançado ) na configuração compute e selecione uma opção na lista EBS Volume Type (Tipo de volume EBS ) dropdown.
volumes padrão do EBS
O Databricks provisiona volumes EBS para cada nó de trabalho da seguinte forma:
- Um volume raiz de instância EBS criptografado de 30 GB usado pelo sistema operacional do host e pelos serviços internos do Databricks.
- Um volume raiz de contêiner EBS criptografado de 150 GB usado pelo worker do Spark. Isso hospeda serviços e logs do Spark.
- (somente HIPAA) um volume de log de worker do EBS criptografado de 75 GB que armazena logs para serviços internos do Databricks.
Adicionar volumes aleatórios do EBS
Para adicionar volumes aleatórios, selecione SSD de uso geral na lista suspensa Tipo de volume do EBS .
Por padrão, as saídas de shuffle do Spark vão para o disco local da instância. Para tipos de instância que não possuem um disco local, ou se você deseja aumentar seu espaço de armazenamento de shuffle do Spark, você pode especificar volumes EBS adicionais. Isso é particularmente útil para evitar erros de falta de espaço em disco quando você executa jobs do Spark que produzem grandes saídas de shuffle.
A Databricks criptografa esses volumes EBS para instâncias on-demand e spot. Leia mais sobre os volumes EBS da AWS.
Opcionalmente, criptografe os volumes do Databricks EBS com um gerenciador de clientes key
Opcionalmente, você pode criptografar os volumes EBS do compute com uma chave gerenciada pelo cliente.
Consulte Chave de gerenciar clientes para criptografia.
Limites do AWS EBS
Certifique-se de que seus limites de AWS EBS sejam altos o suficiente para satisfazer os requisitos de tempo de execução para todos os workers em todos os seus computes implantados. Para obter informações sobre os limites padrão de EBS e como alterá-los, consulte Limites do Amazon Elastic Block Store (EBS).
Tipo de volume do AWS EBS SSD
Selecione gp2 ou gp3 para o tipo de volume do AWS EBS SSD. Para fazer isso, consulte gerenciar SSD storage. A Databricks recomenda que o senhor mude para o gp3 por causa da economia de custos em comparação com o gp2.
Em default, a configuração Databricks define o IOPS e a Taxa de transferência IOPS do volume gp3 para corresponder ao desempenho máximo de um volume gp2 com o mesmo tamanho de volume.
Para obter informações técnicas sobre gp2 e gp3, consulte Tipos de volume do Amazon EBS.
Criptografia de disco local
Visualização
Esse recurso está em Public Preview.
Alguns tipos de instância que o senhor usa para executar o compute podem ter discos conectados localmente. Databricks pode armazenar dados aleatórios ou dados efêmeros nesses discos conectados localmente. Para garantir que todos os dados em repouso sejam criptografados para todos os tipos de armazenamento, inclusive os dados embaralhados que são armazenados temporariamente nos discos locais do recurso compute, o senhor pode ativar a criptografia de disco local.
Suas cargas de trabalho podem ser executadas mais lentamente devido ao impacto no desempenho da leitura e gravação de dados criptografados de e para volumes locais.
Quando a criptografia de disco local está habilitada, o Databricks gera uma chave de criptografia localmente, que é única para cada nó de compute e é usada para criptografar todos os dados armazenados em discos locais. O escopo da chave é local para cada nó de compute e é destruído junto com o próprio nó de compute. Durante sua vida útil, a chave reside na memória para criptografia e descriptografia e é armazenada criptografada no disco.
Para ativar a criptografia de disco local, o senhor deve usar o clustering API. Durante a criação ou edição do site compute, defina enable_local_disk_encryption como true.
Configuração do Spark
Para ajustar os jobs do Spark, você pode fornecer propriedades de configuração personalizadas do Spark.
-
Na página de configuração compute, clique no botão Advanced .
-
Clique na tab Spark .
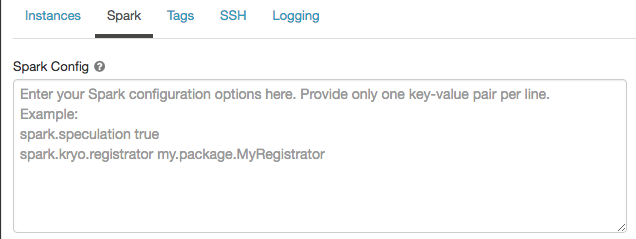
Na configuração do Spark , insira as propriedades de configuração como um par key-value por linha.
Quando o senhor configura compute usando o clustering API, define as propriedades de Spark no campo spark_conf em create clustering API ou Update clustering API.
Para impor as configurações de Spark em compute, os administradores de workspace podem usar as políticas decompute.
Recuperar uma propriedade de configuração do Spark a partir de um segredo
Databricks recomenda o armazenamento de informações confidenciais, como senhas, em um segredo em vez de texto simples. Para fazer referência a um segredo na configuração do Spark, use a seguinte sintaxe:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Por exemplo, para definir uma propriedade de configuração do Spark chamada password para o valor do segredo armazenado em secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Para obter mais informações, consulte gerenciar segredos.
variável de ambiente
Configure a variável de ambiente personalizada que o senhor pode acessar a partir do script de inicialização em execução no recurso compute. Databricks também fornece variáveis de ambiente predefinidas que o senhor pode usar no script de inicialização. O senhor não pode substituir essas variáveis de ambiente predefinidas.
-
Na página de configuração compute, clique no botão Advanced .
-
Clique na tab Spark .
-
Defina as variáveis de ambiente no campo Variáveis de ambiente .
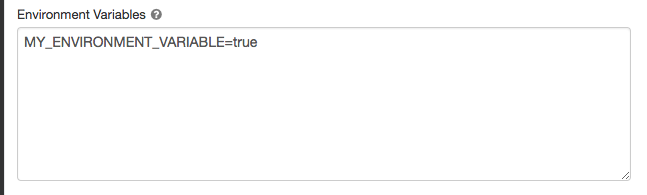
O senhor também pode definir variáveis de ambiente usando o campo spark_env_vars na API de criação de clusters ou na API de atualização de clusters.
computar log delivery
Quando o senhor cria um compute multifuncional ou de trabalho, pode especificar um local para fornecer o clustering logs para o nó driver Spark, nós worker e eventos. Os registros são entregues a cada cinco minutos e arquivados a cada hora no destino escolhido. Databricks entregará todos os logs gerados até que o recurso compute seja encerrado.
Para configurar o local de entrega de log:
- Na página compute, clique no botão Advanced (Avançado ).
- Clique na tab Logging .
- Selecione um tipo de destino.
- Digite o caminho do registro .
Para armazenar o logs, o Databricks cria uma subpasta no caminho escolhido do log com o nome cluster_id do compute.
Por exemplo, se o caminho de log especificado for /Volumes/catalog/schema/volume, os logs de 06308418893214 serão entregues em
/Volumes/catalog/schema/volume/06308418893214.
O envio de logs para volumes está em versão prévia pública e é compatível apenas com compute habilitada para Unity Catalog nos modos de acesso Standard ou Dedicated . No modo de acesso padrão, verifique se o proprietáriocluster pode upload arquivos para o volume. No modo de acesso dedicado, certifique-se de que o usuário ou grupo atribuído possa upload arquivos para o volume. Consulte as operações Criar, excluir ou atualizar arquivos em Privilégios para volumes Unity Catalog.
Destinos do bucket S3
Se o senhor escolher um destino S3, deverá configurar o recurso compute com um instance profile que possa acessar o bucket.
Esse instance profile deve ter as permissões PutObject e PutObjectAcl. Um exemplo do site instance profile
foi incluído para sua conveniência. Consulte o tutorial: Configure o acesso S3 com um instance profile para obter instruções sobre como configurar um instance profile.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>"]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:PutObjectAcl", "s3:GetObject", "s3:DeleteObject"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>/*"]
}
]
}
Esse recurso também está disponível na API REST. Consulte a API de clusters.