executar um arquivo em um clustering ou um arquivo ou Notebook como um Job em Databricks usando a extensão Databricks para Visual Studio Code
A extensão Databricks para Visual Studio Code permite que o senhor execute seu código Python em um clustering ou seu código Python, R, Scala, ou SQL ou Notebook como um Job em Databricks.
Esta informação pressupõe que o senhor já tenha instalado e configurado a extensão Databricks para o Visual Studio Code. Consulte Instalar a extensão Databricks para o Visual Studio Code.
Para depurar o código ou o Notebook no Visual Studio Code, use Databricks Connect. Consulte Depurar código usando Databricks Connect para a extensão Databricks do Visual Studio Code e executar e depurar células do Notebook com Databricks Connect usando a extensão Databricks do Visual Studio Code.
executar um arquivo Python em um clustering
Esse recurso não está disponível quando o senhor usa o site serverless compute.
Para executar um arquivo Python em um clustering Databricks usando a extensão Databricks para o Visual Studio Code, com a extensão e o projeto abertos:
- Abra o arquivo Python que o senhor deseja executar no clustering.
- Siga um destes procedimentos:
-
Na barra de título do editor de arquivos, clique no ícone Databrickse, em seguida, clique em upload e execute File .
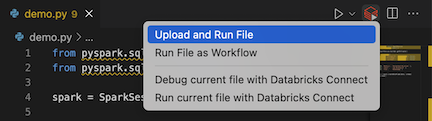
-
No Explorer view (Exibir > Explorer ), clique com o botão direito do mouse no arquivo e selecione execução em Databricks > upload e execução de arquivo no menu de contexto.
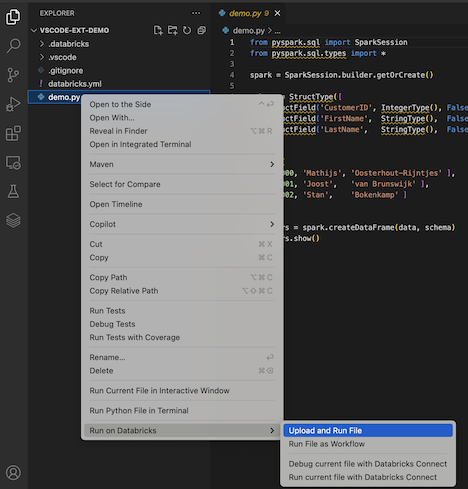
-
A execução do arquivo no clustering e a saída estão disponíveis no Console de dep uração (consulte > Console de depuração ).
executar a Python file as a Job
Para executar um arquivo Python como um trabalho Databricks usando a extensão Databricks para o Visual Studio Code, com a extensão e o projeto abertos:
- Abra o arquivo Python que o senhor deseja executar como um trabalho.
- Siga um destes procedimentos:
-
Na barra de título do editor de arquivos, clique no ícone executar em Databricks e, em seguida, clique em executar File as fluxo de trabalho .
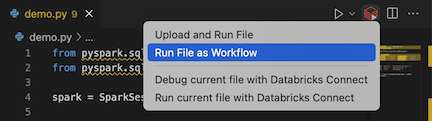
-
No Explorer view (Exibir > Explorer ), clique com o botão direito do mouse no arquivo e selecione executar em Databricks > executar arquivo como fluxo de trabalho no menu de contexto.
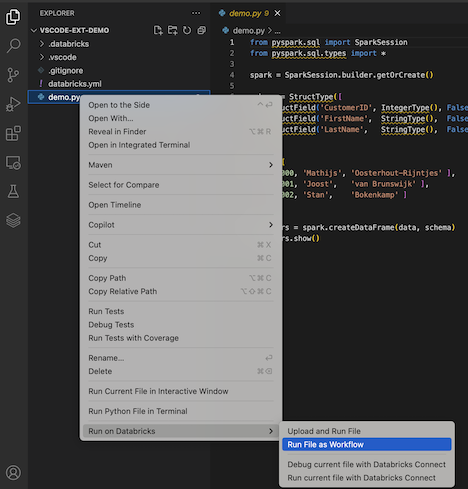
-
Um novo editor tab aparece, com o título Databricks Job execução . O arquivo é executado como um trabalho no site workspace e qualquer saída é impressa na tab área de saída do novo editor.
Para obter view informações sobre a execução do trabalho, clique no link ID da execução da tarefa no novo editor de execuçãoDatabricks Job tab. O site workspace é aberto e os detalhes da execução do trabalho são exibidos em workspace.
executar um Python, R, Scala, ou SQL Notebook como um trabalho
Para executar um Notebook como um Databricks Job usando a extensão Databricks para o Visual Studio Code, com a extensão e o projeto abertos:
- Abra o Notebook que o senhor deseja executar como um Job.
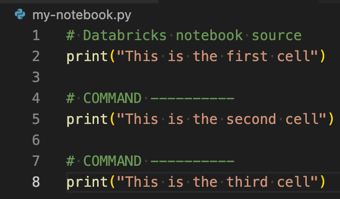
Para transformar um arquivo Python, R, Scala ou SQL em um Databricks Notebook, adicione o comentário # Databricks notebook source no início do arquivo e adicione o comentário # COMMAND ---------- antes de cada célula. Para obter mais informações, consulte Converter um arquivo em um Notebook.
-
Siga um destes procedimentos:
- Na barra de título do editor de arquivos do Notebook, clique no ícone executar em Databricks e, em seguida, clique em executar File as fluxo de trabalho .
Se a execução em Databricks as fluxo de trabalho não estiver disponível, consulte Criar uma configuração de execução personalizada.
- No Explorer view (Exibir > Explorer ), clique com o botão direito do mouse no arquivo do Notebook e selecione executar em Databricks > executar arquivo como fluxo de trabalho no menu de contexto.
Um novo editor tab aparece, com o título Databricks Job execução . A execução do Notebook como um trabalho no site workspace. O Notebook e sua saída são exibidos no novo editor tab's Output area.
Para obter view informações sobre a execução da tarefa, clique no link ID da execução da tarefa no editor de execuçãoDatabricks Job tab. O site workspace é aberto e os detalhes da execução do trabalho são exibidos em workspace.
Criar uma configuração de execução personalizada
Uma configuração de execução personalizada para a extensão Databricks do Visual Studio Code permite que o senhor passe argumentos personalizados para um Job ou um Notebook, ou crie configurações de execução diferentes para arquivos diferentes.
Para criar uma configuração de execução personalizada, clique em execução > Add Configuration no menu principal do Visual Studio Code. Em seguida, selecione Databricks para uma configuração de execução baseada em clustering ou Databricks: fluxo de trabalho para uma configuração de execução baseada em Job.
Por exemplo, a configuração de execução personalizada a seguir modifica o arquivo de execução como fluxo de trabalho launch comando para passar o argumento --prod para o trabalho:
{
"version": "0.2.0",
"configurations": [
{
"type": "databricks-workflow",
"request": "launch",
"name": "Run on Databricks as Workflow",
"program": "${file}",
"parameters": {},
"args": ["--prod"]
}
]
}
Adicione "databricks": true à sua configuração "type": "python" se você quiser usar a configuração do Python e aproveitar a autenticação do Databricks Connect que faz parte da configuração da extensão.
Usando configurações de execução personalizadas, o senhor também pode passar argumentos de linha de comando e executar seu código apenas pressionando F5 . Para obter mais informações, consulte Configurações de inicialização na documentação do Visual Studio Code.