Melhore a qualidade da cadeia RAG
Este artigo aborda como o senhor pode melhorar a qualidade do aplicativo RAG usando componentes da cadeia RAG.
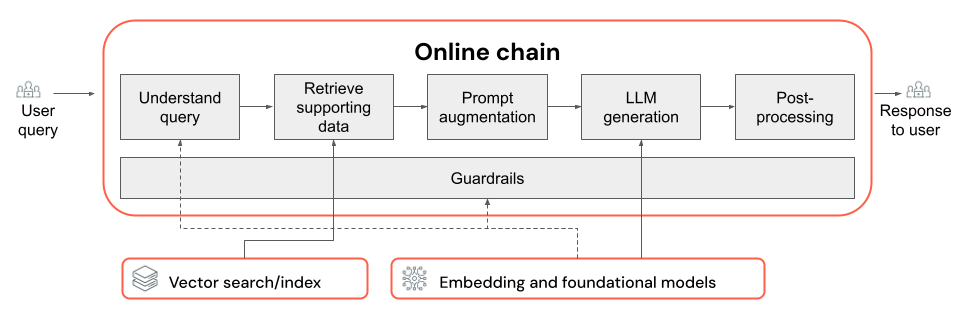
A cadeia RAG recebe uma consulta do usuário como entrada, recupera informações relevantes com base nessa consulta e gera uma resposta apropriada com base nos dados recuperados. Embora as etapas exatas de uma cadeia RAG possam variar muito, dependendo do caso de uso e dos requisitos, a seguir estão os key componentes a serem considerados ao criar sua cadeia RAG:
- Compreensão de consultas: Analisar e transformar as consultas dos usuários para melhor representar a intenção e extrair informações relevantes, como filtros ou palavras-chave, para aprimorar o processo de recuperação.
- Recuperação: Encontrar as partes mais relevantes da informação em uma consulta de recuperação. No caso de dados não estruturados, isso normalmente envolve uma ou uma combinação de pesquisa semântica ou baseada em palavras-chave.
- Aumento do prompt: Combinação de uma consulta do usuário com informações recuperadas e instruções para orientar o LLM a gerar respostas de alta qualidade.
- LLM: selecionar o modelo mais adequado (e os parâmetros do modelo) para seu aplicativo a fim de otimizar/equilibrar o desempenho, a latência e o custo.
- Pós-processamento e barreiras de proteção: Aplicação de etapas adicionais de processamento e medidas de segurança para garantir que as respostas geradas pelo LLM estejam dentro do tópico, sejam factualmente consistentes e sigam diretrizes ou restrições específicas.
Implementar iterativamente as correções de qualidade & para avaliar mostra como iterar os componentes de uma cadeia.
Compreensão da consulta
Usar a consulta do usuário diretamente como uma consulta de recuperação pode funcionar para algumas consultas. No entanto, geralmente é benéfico reformular a consulta antes da etapa de recuperação. A compreensão da consulta compreende uma etapa (ou série de etapas) no início de uma cadeia para analisar e transformar as consultas do usuário para representar melhor a intenção, extrair informações relevantes e, por fim, ajudar no processo de recuperação subsequente. As abordagens para transformar uma consulta do usuário para melhorar a recuperação incluem:
-
Reescrita de consultas: a reescrita de consultas envolve a tradução de uma consulta do usuário em uma ou mais consultas que representem melhor a intenção original. O objetivo é reformular a consulta de forma a aumentar a probabilidade de a etapa de recuperação encontrar os documentos mais relevantes. Isso pode ser particularmente útil ao lidar com consultas complexas ou ambíguas que podem não corresponder diretamente à terminologia usada nos documentos de recuperação.
Exemplos:
- Parafraseando a história da conversa em um bate-papo com vários turnos
- Corrigindo erros de ortografia na consulta do usuário
- Substituindo palavras ou frases na consulta do usuário por sinônimos para capturar uma variedade maior de documentos relevantes
A reescrita da consulta deve ser feita em conjunto com as alterações no componente de recuperação
-
Extração de filtro: em alguns casos, as consultas do usuário podem conter filtros ou critérios específicos que podem ser usados para restringir os resultados da pesquisa. A extração de filtros envolve identificar e extrair esses filtros da consulta e passá-los para a etapa de recuperação como parâmetros adicionais. Isso pode ajudar a melhorar a relevância dos documentos recuperados, concentrando-se em subconjuntos específicos dos dados disponíveis.
Exemplos:
- Extração de períodos de tempo específicos mencionados na consulta, como "artigos dos últimos 6 meses" ou "relatórios de 2023".
- Identificar menções de produtos, serviços ou categorias específicas na consulta, como "Databricks Professional service" ou "laptops".
- Extraindo entidades geográficas da consulta, como nomes de cidades ou códigos de países.
A extração de filtros deve ser feita em conjunto com alterações nos componentes do pipeline de dados de extração de metadados e da cadeia de recuperação. A etapa de extração de metadados deve garantir que os campos de metadados relevantes estejam disponíveis para cada documento/bloco, e a etapa de recuperação deve ser implementada para aceitar e aplicar filtros extraídos.
Além da reescrita da consulta e da extração de filtros, outra consideração importante na compreensão da consulta é se deve ser usada uma única chamada ao LLM ou várias chamadas. Embora o uso de uma única chamada com um prompt cuidadosamente elaborado possa ser eficiente, há casos em que a divisão do processo de compreensão da consulta em várias chamadas ao LLM pode levar a melhores resultados. A propósito, essa é uma regra geral aplicável quando você está tentando implementar várias etapas lógicas complexas em um único prompt.
Por exemplo, o senhor pode usar uma chamada LLM para classificar a intenção da consulta, outra para extrair entidades relevantes e uma terceira para reescrever a consulta com base nas informações extraídas. Embora essa abordagem possa adicionar alguma latência ao processo geral, ela pode permitir um controle mais refinado e potencialmente melhorar a qualidade dos documentos recuperados.
Compreensão de consultas em várias etapas para um bot de suporte
Veja como um componente de compreensão de consultas em várias etapas pode procurar um bot de suporte ao cliente:
- Classificação da intenção: Use um LLM para classificar a consulta do usuário em categorias predefinidas, como "informações sobre o produto", "solução de problemas" ou "gerenciamento doaccount ".
- Extração de entidades: Com base na intenção identificada, use outra chamada LLM para extrair entidades relevantes da consulta, como nomes de produtos, erros relatados ou números account.
- Reescrita de consultas: Use a intenção e as entidades extraídas para reescrever a consulta original em um formato mais específico e direcionado, por exemplo, "Minha cadeia RAG não está conseguindo ser implantada no modelo servindo, estou vendo o seguinte erro...".
Recuperação
O componente de recuperação da cadeia RAG é responsável por encontrar os blocos de informações mais relevantes em uma consulta de recuperação. No contexto de dados não estruturados, a recuperação normalmente envolve uma ou uma combinação de pesquisa semântica, pesquisa baseada em palavras-chave e filtragem de metadados. A escolha da estratégia de recuperação depende dos requisitos específicos do seu aplicativo, da natureza dos dados e dos tipos de consultas que você espera processar. Vamos comparar essas opções:
- Pesquisa semântica: a pesquisa semântica usa um modelo de incorporação para converter cada pedaço de texto em uma representação vetorial que captura seu significado semântico. Ao comparar a representação vetorial da consulta de recuperação com as representações vetoriais dos blocos, a pesquisa semântica pode recuperar documentos conceitualmente semelhantes, mesmo que eles não contenham as palavras-chave exatas da consulta.
- Pesquisa baseada em palavras-chave: a pesquisa baseada em palavras-chave determina a relevância dos documentos analisando a frequência e a distribuição de palavras compartilhadas entre a consulta de recuperação e os documentos indexados. Quanto mais vezes as mesmas palavras aparecerem na consulta e em um documento, maior será a pontuação de relevância atribuída a esse documento.
- Pesquisa híbrida: a pesquisa híbrida combina os pontos fortes da pesquisa semântica e baseada em palavras-chave, empregando um processo de recuperação em duas etapas. Primeiro, ele realiza uma pesquisa semântica para recuperar um conjunto de documentos conceitualmente relevantes. Em seguida, ele aplica a pesquisa baseada em palavras-chave nesse conjunto reduzido para refinar ainda mais os resultados com base nas correspondências exatas de palavras-chave. Finalmente, ele combina as pontuações das duas etapas para classificar os documentos.
Compare estratégias de recuperação
A tabela a seguir compara cada uma dessas estratégias de recuperação entre si:
Busca semântica | Busca por palavra-chave | Pesquisa híbrida | |
|---|---|---|---|
Explicação simples | Se os mesmos conceitos aparecerem na consulta e em um documento em potencial, eles serão relevantes. | Se as mesmas palavras aparecerem na consulta e em um documento em potencial, elas são relevantes. Quanto mais palavras da consulta no documento, mais relevante esse documento é. | executa AMBAS uma pesquisa semântica e uma pesquisa por palavra-chave e, em seguida, combina os resultados. |
Exemplo de caso de uso | Suporte ao cliente em que as dúvidas dos usuários são diferentes das palavras nos manuais do produto. Exemplo: “como faço para ligar meu telefone?” e a seção manual é chamada de “alternar a alimentação”. | Suporte ao cliente onde as consultas contêm termos técnicos específicos e não descritivos. Exemplo: “o que o modelo HD7-8D faz?” | Consultas de suporte ao cliente que combinavam termos semânticos e técnicos. Exemplo: “como faço para ligar meu HD7-8D?” |
Abordagens técnicas | Usa incorporações para representar texto em um espaço vetorial contínuo, permitindo a pesquisa semântica. | Baseia-se em métodos discretos baseados em tokens, como bag-of-words, TF-IDF, BM25 para correspondência de palavras-chave. | Use uma abordagem de reclassificação para combinar os resultados, como fusão recíproca de classificação ou um modelo de reclassificação. |
Pontos fortes | Recuperação de informações contextualmente semelhantes a uma consulta, mesmo que as palavras exatas não sejam usadas. | Cenários que exigem correspondências precisas de palavras-chave, ideais para consultas focadas em termos específicos, como nomes de produtos. | Combina o melhor das duas abordagens. |
Formas de aprimorar o processo de recuperação
Além dessas estratégias básicas de recuperação, existem várias técnicas que você pode aplicar para aprimorar ainda mais o processo de recuperação:
- Expansão da consulta: a expansão da consulta pode ajudar a capturar uma variedade maior de documentos relevantes usando várias variações da consulta de recuperação. Isso pode ser feito conduzindo pesquisas individuais para cada consulta expandida ou usando uma concatenação de todas as consultas de pesquisa expandidas em uma única consulta de recuperação.
A expansão da consulta deve ser feita em conjunto com as alterações no componente de compreensão da consulta (cadeia RAG). As várias variações de uma consulta de recuperação geralmente são geradas nesta etapa.
- Reclassificação: depois de recuperar um conjunto inicial de partes, aplique critérios de classificação adicionais (por exemplo, classificar por hora) ou um modelo de reordenação para reordenar os resultados. A nova classificação pode ajudar a priorizar as partes mais relevantes de acordo com uma consulta de recuperação específica. O ranqueamento com modelos de codificadores cruzados, como o mxbai-rerank e o ColBERTv2, pode gerar um aumento no desempenho da recuperação.
- Filtragem de metadados: use filtros de metadados extraídos da etapa de compreensão da consulta para restringir o espaço de pesquisa com base em critérios específicos. Os filtros de metadados podem incluir atributos como tipo de documento, data de criação, autor ou tags específicas do domínio. Ao combinar filtros de metadados com pesquisa semântica ou baseada em palavras-chave, você pode criar uma recuperação mais direcionada e eficiente.
A filtragem de metadados deve ser feita em conjunto com alterações nos componentes de compreensão da consulta (cadeia RAG) e extração de metadados (pipeline de dados).
Aumento imediato
O aumento do prompt é a etapa em que a consulta do usuário é combinada com as informações e instruções recuperadas em um prompt padrão para orientar o modelo de linguagem a gerar respostas de alta qualidade. A iteração desse padrão para otimizar o prompt fornecido ao LLM (também conhecido como engenharia de prompt ) é necessária para garantir que o modelo seja orientado para produzir respostas precisas, fundamentadas e coerentes.
Há um guia completo para a engenharia de prompts, mas aqui estão algumas considerações que o senhor deve ter em mente quando estiver trabalhando com o padrão de prompts:
-
Forneça exemplos
- Inclua exemplos de consultas bem formadas e suas respostas ideais correspondentes dentro do próprio padrão do prompt(aprendizado de poucas tentativas). Isso ajuda o modelo a entender o formato, o estilo e o conteúdo desejados das respostas.
- Uma forma útil de apresentar bons exemplos é identificar os tipos de consultas que sua cadeia enfrenta. Crie respostas padrão ouro para essas consultas e inclua-as como exemplos no prompt.
- Certifique-se de que os exemplos fornecidos representem as consultas dos usuários que você espera no momento da inferência. Procure cobrir uma ampla gama de consultas esperadas para ajudar o modelo a generalizar melhor.
-
Parametrize seu padrão de prompt
- Projete seu padrão de prompt para ser flexível, parametrizando-o para incorporar informações adicionais além dos dados recuperados e da consulta do usuário. Podem ser variáveis como data atual, contexto do usuário ou outros metadados relevantes.
- A injeção dessas variáveis no prompt no momento da inferência pode permitir respostas mais personalizadas ou sensíveis ao contexto.
-
Considere a inspiração da cadeia de pensamento
- Para consultas complexas em que as respostas diretas não são facilmente aparentes, considere a solicitação da Cadeia de Pensamento (CoT). Essa estratégia de engenharia de prompt divide perguntas complicadas em etapas mais simples e sequenciais, orientando o LLM por meio de um processo de raciocínio lógico.
- Ao solicitar que o modelo “pense no problema passo a passo”, você o incentiva a fornecer respostas mais detalhadas e fundamentadas, que podem ser particularmente eficazes para lidar com consultas abertas ou de várias etapas.
-
As solicitações podem não ser transferidas entre os modelos
- Reconheça que os prompts geralmente não são transferidos perfeitamente entre diferentes modelos de linguagem. Cada modelo tem suas próprias características exclusivas, nas quais um prompt que funciona bem para um modelo pode não ser tão eficaz para outro.
- Experimente diferentes formatos e durações de prompts, consulte guias on-line (como o OpenAI Cookbook ou Anthropic cookbook) e esteja preparado para adaptar e refinar seus prompts ao alternar entre modelos.
LLM
O componente de geração da cadeia RAG pega o prompt padrão aumentado da etapa anterior e o passa para um LLM. Ao selecionar e otimizar um LLM para o componente de geração de uma cadeia RAG, considere os seguintes fatores, que são igualmente aplicáveis a quaisquer outras etapas que envolvam chamadas de LLM:
-
Experimente diferentes modelos prontos para uso.
- Cada modelo tem suas próprias propriedades, pontos fortes e fracos. Alguns modelos podem ter uma compreensão melhor de determinados domínios ou ter um desempenho melhor em tarefas específicas.
- Conforme mencionado anteriormente, lembre-se de que a escolha do modelo também pode influenciar o processo de engenharia de prompts, pois modelos diferentes podem responder de forma diferente aos mesmos prompts.
- Se houver várias etapas em sua cadeia que exijam um LLM, como chamadas para compreensão de consultas além da etapa de geração, considere o uso de modelos diferentes para etapas diferentes. Modelos mais caros e de uso geral podem ser um exagero para tarefas como determinar a intenção de uma consulta do usuário.
-
Comece pequeno e aumente conforme necessário.
- Embora possa ser tentador escolher imediatamente os modelos mais potentes e capazes disponíveis (por exemplo, GPT-4, Claude), geralmente é mais eficiente começar com modelos menores e mais leves.
- Em muitos casos, alternativas de código aberto menores, como o Llama 3, podem fornecer resultados satisfatórios a um custo menor e com tempos de inferência mais rápidos. Esses modelos podem ser particularmente eficazes para tarefas que não exigem raciocínio altamente complexo ou amplo conhecimento do mundo.
- Ao desenvolver e refinar sua cadeia RAG, avalie continuamente o desempenho e as limitações do modelo escolhido. Se você achar que o modelo tem dificuldades com certos tipos de consultas ou não fornece respostas suficientemente detalhadas ou precisas, considere escalar para um modelo mais eficiente.
- Monitore o impacto da mudança de modelos em key métricas como qualidade de resposta, latência e custo para garantir que o senhor esteja atingindo o equilíbrio certo para os requisitos do seu caso de uso específico.
-
Otimize os parâmetros do modelo
- Experimente diferentes configurações de parâmetros para encontrar o equilíbrio ideal entre qualidade de resposta, diversidade e coerência. Por exemplo, ajustar a temperatura pode controlar a aleatoriedade do texto gerado, enquanto max_tokens pode limitar o comprimento da resposta.
- O senhor deve estar ciente de que as configurações ideais dos parâmetros podem variar de acordo com a tarefa específica, o prompt e o estilo de saída desejado. Teste e refine iterativamente essas configurações com base na avaliação das respostas geradas.
-
Ajuste fino específico da tarefa
- Ao refinar o desempenho, considere o ajuste fino de modelos menores para subtarefas específicas dentro da cadeia de RAGs, como a compreensão de consultas.
- Ao treinar modelos especializados para tarefas individuais com a cadeia RAG, o senhor pode potencialmente melhorar o desempenho geral, reduzir a latência e diminuir os custos de inferência em comparação com o uso de um único modelo grande para todas as tarefas.
-
Pré-treinamento contínuo
- Se o seu aplicativo RAG lidar com um domínio especializado ou exigir conhecimento que não esteja bem representado no LLM pré-treinado, considere a possibilidade de realizar um pré-treinamento contínuo (CPT) em dados específicos do domínio.
- O pré-treinamento contínuo pode melhorar a compreensão de um modelo sobre terminologia específica ou conceitos exclusivos do seu domínio. Por sua vez, isso pode reduzir a necessidade de uma extensa engenharia imediata ou de poucos exemplos.
Pós-processamento e grades de proteção
Depois que o LLM gera uma resposta, muitas vezes é necessário aplicar técnicas de pós-processamento ou guardrails para garantir que o resultado atenda aos requisitos de formato, estilo e conteúdo desejados. Essa etapa final (ou várias etapas) na cadeia pode ajudar a manter a consistência e a qualidade nas respostas geradas. Se você estiver implementando o pós-processamento e as barreiras de proteção, considere algumas das seguintes opções:
-
Impondo o formato de saída
- Dependendo do seu caso de uso, o senhor pode exigir que as respostas geradas sigam um formato específico, como um padrão estruturado ou um tipo de arquivo específico (como JSON, HTML, Markdown e assim por diante).
- Se for necessária uma saída estruturada, bibliotecas como Instructor ou Outlines são bons pontos de partida para implementar esse tipo de etapa de validação.
- Ao desenvolver, reserve um tempo para garantir que a etapa de pós-processamento seja flexível o suficiente para lidar com variações nas respostas geradas, mantendo o formato exigido.
-
Mantendo a consistência do estilo
- Se seu aplicativo RAG tiver diretrizes de estilo ou requisitos de tom específicos (por exemplo, formal versus casual, conciso versus detalhado), uma etapa de pós-processamento pode verificar e aplicar esses atributos de estilo nas respostas geradas.
-
Filtros de conteúdo e grades de segurança
- Dependendo da natureza do seu aplicativo RAG e dos possíveis riscos associados ao conteúdo gerado, pode ser importante implementar filtros de conteúdo ou grades de proteção para evitar a saída de informações inadequadas, ofensivas ou prejudiciais.
- Considere o uso de modelos como o Llama Guard ou APIs projetadas especificamente para moderação e segurança de conteúdo, como a API de moderação da OpenAI, para implementar proteções de segurança.
-
Lidando com alucinações
- A defesa contra alucinações também pode ser implementada como uma etapa de pós-processamento. Isso pode envolver a referência cruzada da saída gerada com os documentos recuperados ou o uso de LLMs adicionais para validar a precisão factual da resposta.
- Desenvolva mecanismos de fallback para lidar com casos em que a resposta gerada não atenda aos requisitos de precisão factual, como a geração de respostas alternativas ou o fornecimento de isenções de responsabilidade ao usuário.
-
Tratamento de erros
- Em qualquer etapa de pós-processamento, implemente mecanismos para lidar com os casos em que a etapa encontra um problema ou falha em gerar uma resposta satisfatória. Isso pode envolver a geração de uma resposta em default ou o encaminhamento do problema a um operador humano para análise manual.