Conectores padrão em LakeFlow Connect
Esta página descreve os conectores padrão em Databricks LakeFlow Connect, que oferecem níveis mais altos de personalização de ingestão pipeline em comparação com os conectores gerenciar.
Camadas da pilha ETL
Alguns conectores operam em um nível da pilha ETL. Por exemplo, Databricks oferece conectores totalmente gerenciáveis para aplicativos corporativos como o Salesforce e bancos de dados como SQL Server. Outros conectores operam em múltiplas camadas da pilha ETL. Por exemplo, você pode usar conectores padrão tanto na transmissão estruturada para personalização completa quanto no pipeline declarativo LakeFlow Spark para uma experiência mais gerenciada.
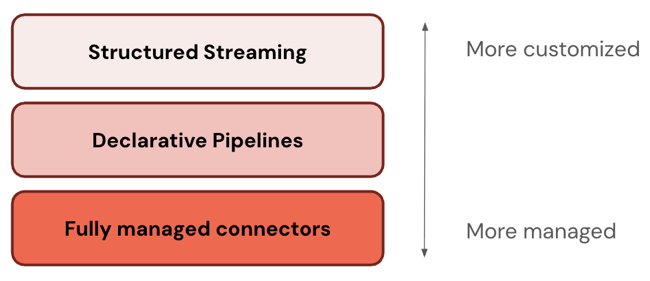
Databricks recomenda começar com a camada mais gerenciável. Se ele não atender aos seus requisitos (por exemplo, se não for compatível com sua fonte de dados), passe para a próxima camada.
A tabela a seguir descreve as três camadas do produto de ingestão, ordenadas da mais personalizável para a mais gerenciável:
Camada | Descrição |
|---|---|
Apache Spark A transmissão estruturada é um mecanismo de transmissão que oferece tolerância a falhas de ponta a ponta com garantias de processamento exatamente único usando Spark APIs. | |
O pipeline declarativo LakeFlow Spark baseia-se na transmissão estruturada, oferecendo uma estrutura declarativa para a criação de pipeline de dados. Você pode definir as transformações a serem realizadas em seus dados, e o pipeline declarativo LakeFlow Spark gerencia orquestração, monitoramento, qualidade de dados, erros e muito mais. Portanto, oferece mais automação e menos custos indiretos do que a transmissão estruturada. | |
conectores gerenciados construídos no pipeline declarativo LakeFlow Spark , oferecendo ainda mais automação para a fonte de dados mais popular. Eles ampliam a funcionalidade do pipeline declarativo LakeFlow Spark para incluir também autenticação específica da fonte, CDC Detecção de Criptografia de Conteúdo), tratamento de casos extremos, manutenção API a longo prazo, novas tentativas automatizadas, evolução automatizada do esquema e assim por diante. Portanto, oferecem ainda mais automação para qualquer fonte de dados compatível. |
Escolha um conector
A tabela a seguir lista os conectores de ingestão padrão por fonte de dados e nível de personalização do site pipeline. Para obter uma experiência de ingestão totalmente automatizada, use os conectores gerenciar.
Os exemplos de SQL para ingestão incremental do armazenamento de objetos na nuvem usam a sintaxe CREATE STREAMING TABLE. Ele oferece aos usuários de SQL uma experiência de ingestão dimensionável e robusta, portanto, é a alternativa recomendada para COPY INTO.
Origem | Mais personalização | Alguma personalização | Mais automação |
|---|---|---|---|
Armazenamento de objetos na nuvem | Auto Loader com transmissão estruturada
| Auto Loader com pipeline declarativo LakeFlow Spark
| Auto Loader com Databricks SQL
|
Servidores SFTP | Ingerir arquivos de servidores SFTP (Python, SQL) | N/A | N/A |
Apache Kafka | transmissão estruturada com Kafka source
| Pipeline declarativo LakeFlow Spark com fonte Kafka
| Databricks SQL com fonte Kafka
|
Amazon Kinesis | transmissão estruturada com a fonte Kinesis
| Pipeline declarativo LakeFlow Spark com fonte Kinesis
| Databricks SQL com fonte Kinesis
|
Google Pub/Sub | transmissão estruturada com fonte Pub/Sub
| Pipeline declarativo LakeFlow Spark com fonte Pub/Sub
| Databricks SQL com fonte Pub/Sub
|
Apache Pulsar | transmissão estruturada com fonte Pulsar
| Pipeline declarativo LakeFlow Spark com fonte Pulsar
| Databricks SQL com fonte Pulsar
|
Programa de ingestão
O senhor pode configurar o pipeline de ingestão para execução em uma programação recorrente ou contínua.