MLOps fluxo de trabalho on Databricks
Este artigo descreve como o senhor pode usar o MLOps na plataforma Databricks para otimizar o desempenho e a eficiência de longo prazo de seus sistemas de aprendizado de máquina (ML). Ele inclui recomendações gerais para uma arquitetura de MLOps e descreve um fluxo de trabalho generalizado usando a plataforma Databricks que o senhor pode usar como modelo para o seu processo de desenvolvimento de ML até a produção. Para modificações desse fluxo de trabalho para aplicativos LLMOps, consulte o fluxo de trabalho LLMOps.
Para obter mais detalhes, consulte The Big Book of MLOps.
O que é MLOps?
O MLOps é um conjunto de processos e etapas automatizadas para gerenciar códigos, dados e modelos para melhorar o desempenho, a estabilidade e a eficiência de longo prazo dos sistemas de ML. Ele combina DevOps, DataOps e ModelOps.
ML ativos, como código, dados e modelos, são desenvolvidos em estágios que progridem desde os estágios iniciais de desenvolvimento, que não têm limitações rígidas de acesso e não são rigorosamente testados, passando por um estágio intermediário de testes, até um estágio final de produção que é rigorosamente controlado. A plataforma Databricks permite que o senhor gerencie esses ativos em uma única plataforma com controle de acesso unificado. O senhor pode desenvolver aplicativos de dados e aplicativos de ML na mesma plataforma, reduzindo os riscos e os atrasos associados à movimentação de dados.
Recomendações gerais para MLOps
Esta seção inclui algumas recomendações gerais para MLOps em Databricks com links para mais informações.
Crie um ambiente separado para cada estágio
Um ambiente de execução é o local em que modelos e dados são criados ou consumidos pelo código. Cada ambiente de execução consiste em instâncias do compute, seus tempos de execução e biblioteca, além do trabalho automatizado.
A Databricks recomenda a criação de ambientes separados para os diferentes estágios do código de ML e o desenvolvimento de modelos com transições claramente definidas entre os estágios. O fluxo de trabalho descrito neste artigo segue esse processo, usando os nomes comuns para os estágios:
Outras configurações também podem ser usadas para atender às necessidades específicas da sua organização.
Controle de acesso e controle de versão
O controle de acesso e o controle de versão são key componentes de qualquer processo de software operações. A Databricks recomenda o seguinte:
- Use o Git para controle de versão. O pipeline e o código devem ser armazenados em Git para controle de versão. Mover a lógica de ML entre os estágios pode ser interpretado como mover o código do ramo de desenvolvimento para o ramo de preparação e para o ramo de lançamento. Use as pastasDatabricks Git para integrar-se ao seu provedor Git e sincronizar o Notebook e o código-fonte com o espaço de trabalho Databricks. A Databricks também fornece ferramentas adicionais para integração com o Git e controle de versão; consulte Ferramentas de desenvolvimento local.
- Armazene dados em uma arquitetura lakehouse usando tabelas Delta. Os dados devem ser armazenados em uma arquiteturalakehouse em sua nuvem account. As tabelas de dados brutos e de recursos devem ser armazenadas como tabelasDelta com controles de acesso para determinar quem pode lê-las e modificá-las.
- desenvolvimento de modelos gerenciais com MLflow . O senhor pode usar o MLflow para acompanhar o processo de desenvolvimento do modelo e salvar o código Snapshot, os parâmetros do modelo, as métricas e outros metadados.
- Use Models no Unity Catalog para gerenciar o ciclo de vida do modelo. Use os modelos no Unity Catalog para gerenciar o controle de versão, a governança e o status da implantação do modelo.
código implantado, não modelos
Na maioria das situações, a Databricks recomenda que, durante o processo de desenvolvimento de ML, o senhor promova o código , e não os modelos , de um ambiente para o outro. A mudança do projeto ativo dessa forma garante que todo o código no processo de desenvolvimento do ML passe pelos mesmos processos de revisão de código e teste de integração. Também garante que a versão de produção do modelo seja treinada no código de produção. Para uma discussão mais detalhada das opções e vantagens e desvantagens, consulte Padrões de implantação de modelos.
Recomendado MLOps fluxo de trabalho
As seções a seguir descrevem um fluxo de trabalho típico de MLOps, abrangendo cada um dos três estágios: desenvolvimento, preparação e produção.
Esta seção usa os termos "cientista de dados" e "engenheiro de ML" como personas arquetípicas; funções e responsabilidades específicas no fluxo de trabalho de MLOps variam entre equipes e organizações.
Estágio de desenvolvimento
O foco do estágio de desenvolvimento é a experimentação. data scientists desenvolver recurso e modelos e executar experimentos para otimizar o desempenho do modelo. O resultado do processo de desenvolvimento é o código ML pipeline que pode incluir computação de recursos, treinamento de modelos, inferência e monitoramento.
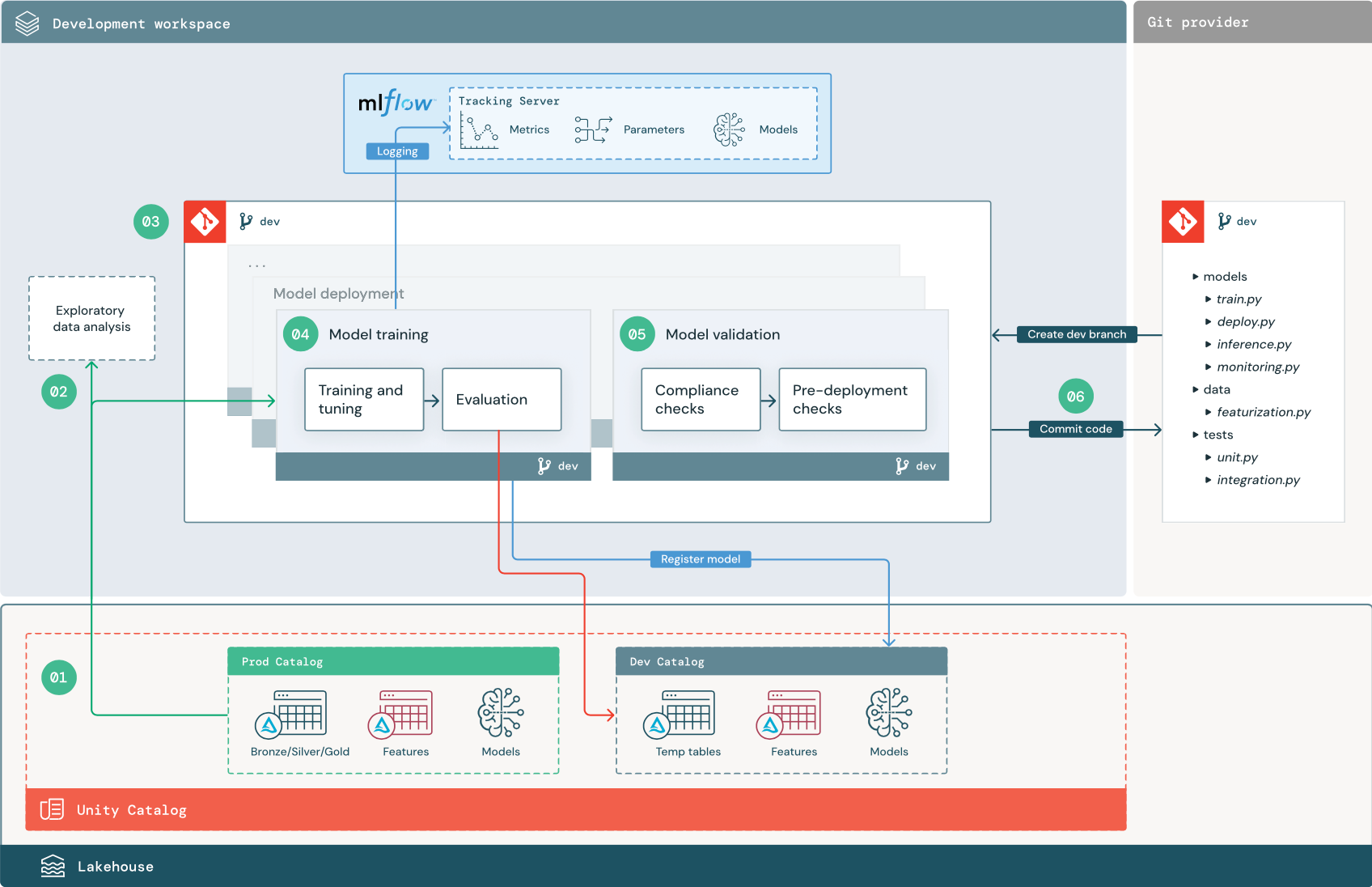
As etapas numeradas correspondem aos números mostrados no diagrama.
1. fonte de dados
O ambiente de desenvolvimento é representado pelo catálogo dev no Unity Catalog. data scientists têm acesso de leitura e gravação ao catálogo de desenvolvimento, pois criam dados temporários e tabelas de recurso no catálogo de desenvolvimento workspace. Os modelos criados na fase de desenvolvimento são registrados no catálogo de desenvolvedores.
Idealmente, data scientists trabalhando no desenvolvimento workspace também tem acesso somente leitura aos dados de produção no catálogo prod. Ao permitir que o site data scientists tenha acesso de leitura aos dados de produção, tabelas de inferência e tabelas métricas no catálogo de produtos, o senhor pode analisar as previsões e o desempenho do modelo de produção atual. data scientists também deve ser capaz de carregar modelos de produção para experimentação e análise.
Se não for possível conceder acesso somente leitura ao catálogo prod, um instantâneo dos dados de produção poderá ser gravado no catálogo dev para permitir que o site data scientists desenvolva e avalie o código do projeto.
2. Análise exploratória de dados (EDA)
data scientists explorar e analisar dados em um processo interativo e iterativo usando o Notebook. O objetivo é avaliar se os dados disponíveis têm o potencial de resolver o problema do negócio. Nessa etapa, o cientista de dados começa a identificar as etapas de preparação e caracterização de dados para o treinamento do modelo. Esse processo ad hoc geralmente não faz parte de um pipeline que será implantado em outros ambientes de execução.
AutoML acelera esse processo ao gerar modelos de linha de base para um dataset. AutoML executa e registra um conjunto de testes e fornece um Python Notebook com o código-fonte de cada execução de teste, para que o usuário possa revisar, reproduzir e modificar o código. AutoML também calcula estatísticas resumidas no site dataset e salva essas informações em um Notebook que pode ser revisado pelo usuário.
3. Código
O repositório de código contém todos os pipelines, módulos e outros arquivos de projeto para um projeto ML. data scientists criar um pipeline novo ou atualizado em uma ramificação de desenvolvimento ("dev") do repositório do projeto. A partir de EDA e das fases iniciais de um projeto, data scientists deve trabalhar em um repositório para compartilhar o código e acompanhar as alterações.
4. Modelo de trem (desenvolvimento)
data scientists Desenvolver o modelo de treinamento pipeline no ambiente de desenvolvimento usando tabelas dos catálogos dev ou prod.
Este site pipeline inclui 2 tarefas:
-
treinamento e afinação. Os modelos do processo de treinamento registraram parâmetros, métricas e artefatos no servidor de acompanhamento MLflow. Após o treinamento e o ajuste dos hiperparâmetros, o artefato do modelo final é registrado no servidor de acompanhamento para registrar um link entre o modelo, os dados de entrada nos quais ele foi treinado e o código usado para gerá-lo.
-
Avaliação. Avalie a qualidade do modelo testando dados armazenados. Os resultados desses testes são registrados no servidor de acompanhamento MLflow. O objetivo da avaliação é determinar se o modelo recém-desenvolvido tem um desempenho melhor do que o modelo de produção atual. Com permissões suficientes, qualquer modelo de produção registrado no catálogo prod pode ser carregado no site de desenvolvimento workspace e comparado com um modelo recém-treinado.
Se os requisitos de governança da sua organização incluírem informações adicionais sobre o modelo, o senhor poderá salvá-las usando MLflow acompanhamento. Os artefatos típicos são descrições de texto simples e interpretações de modelos, como o graficar produzido pelo SHAP. Requisitos específicos de governança podem vir de um diretor de governança de dados ou de partes interessadas do negócio.
O resultado do treinamento do modelo pipeline é um artefato do modelo ML armazenado no servidor de acompanhamento MLflow para o ambiente de desenvolvimento. Se o pipeline for executado no staging ou na produção workspace, o artefato do modelo será armazenado no servidor de acompanhamento MLflow para esse workspace.
Quando o treinamento do modelo estiver concluído, registre o modelo em Unity Catalog. Configure seu código pipeline para registrar o modelo no catálogo correspondente ao ambiente em que o modelo pipeline foi executado; neste exemplo, o catálogo dev.
Com a arquitetura recomendada, o senhor implantou um Databricks fluxo de trabalho multitarefa em que a primeira tarefa é o treinamento do modelo pipeline, seguido pela validação do modelo e pela tarefa de implantação do modelo. A tarefa de treinamento do modelo produz um URI de modelo que a tarefa de validação do modelo pode usar. O senhor pode usar valores de tarefa para passar esse URI para o modelo.
5. Validar e implantar o modelo (desenvolvimento)
Além do modelo de treinamento pipeline, outros pipelines, como o pipeline de validação e implantação de modelos, são desenvolvidos no ambiente de desenvolvimento.
-
Validação do modelo. A validação do modelo pipeline obtém o URI do modelo do modelo de treinamento pipeline, carrega o modelo de Unity Catalog e executa verificações de validação.
As verificações de validação dependem do contexto. Elas podem incluir verificações fundamentais, como a confirmação do formato e dos metadados necessários, e verificações mais complexas que podem ser necessárias para indústrias altamente regulamentadas, como verificações predefinidas do site compliance e a confirmação do desempenho do modelo em fatias de dados selecionadas.
A principal função do pipeline de validação do modelo é determinar se um modelo deve prosseguir para a etapa de implementação. Se o modelo passar nas verificações de pré-implantação, ele poderá receber o alias "Challenger" no Unity Catalog. Se as verificações falharem, o processo será encerrado. É possível configurar o fluxo de trabalho para notificar os usuários sobre uma falha de validação. Consulte Adicionar notificações em um trabalho.
-
Implantação do modelo. O pipeline de implantação de modelos normalmente promove diretamente o modelo "Challenger" recém-treinado ao status de "Champion" usando uma atualização de alias, ou facilita uma comparação entre o modelo "Champion" existente e o novo modelo "Challenger". Este pipeline também pode configurar qualquer infraestrutura de inferência necessária, como o endpoint servindo modelo. Para obter uma discussão detalhada sobre as etapas envolvidas no pipeline de implantação do modelo, consulte Produção.
6. Confirmar o código
Depois de desenvolver o código para treinamento, validação, implantação e outros pipelines, o cientista de dados ou o engenheiro do ML envia as alterações do branch de desenvolvimento para o controle de origem.
Estágio de encenação
O foco desta passo é testar o código ML pipelines para garantir que esteja pronto para produção. Todo o código ML pipelines é testado neste estágio, incluindo código para treinamento de modelo, bem como pipelines de engenharia de recursos, código de inferência e assim por diante.
Os engenheiros de ML criam um pipeline de CI para implementar a execução dos testes de unidade e integração nesta passo. A saída do processo de encenação é um ramo de liberação que aciona o sistema CI/CD para iniciar a fase de produção.
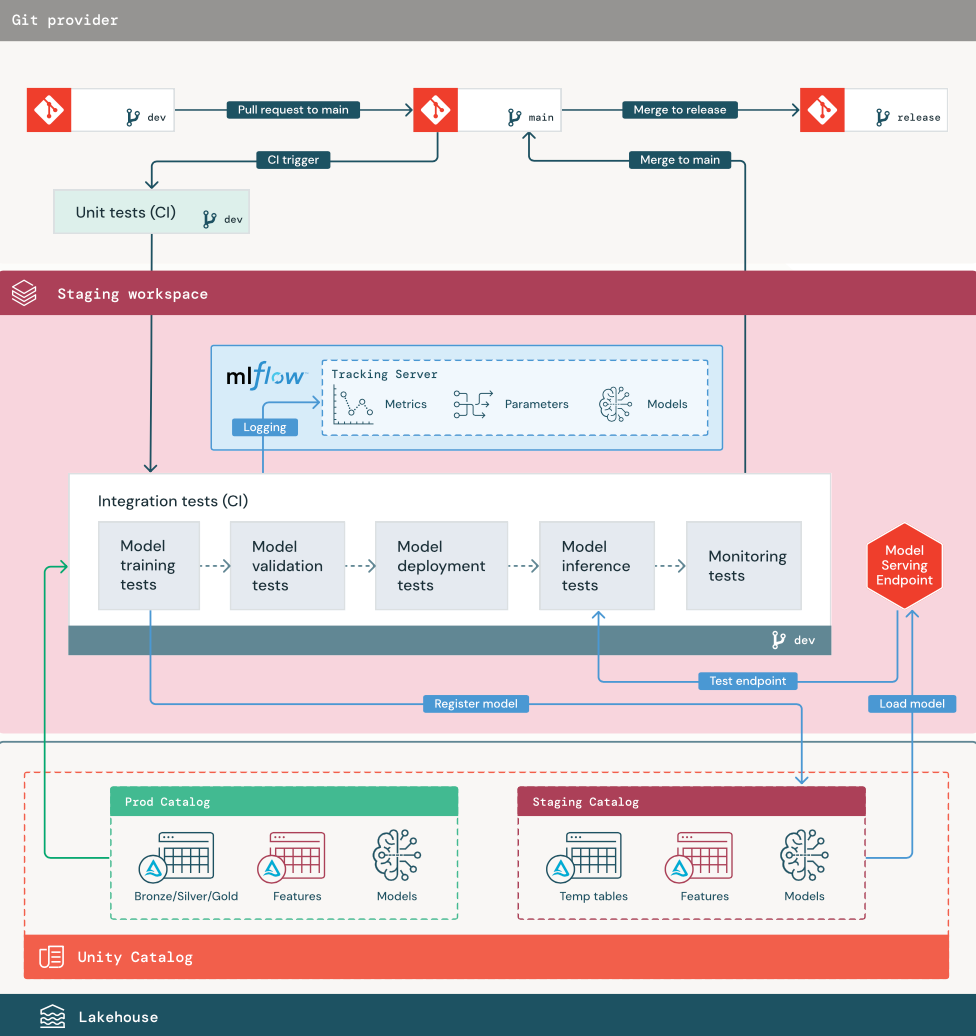
1. Dados
O ambiente de preparação deve ter seu próprio catálogo em Unity Catalog para testar o pipeline ML e registrar os modelos em Unity Catalog. Esse catálogo é mostrado como o catálogo de “preparação” no diagrama. Os ativos gravados neste catálogo são geralmente temporários e mantidos apenas até a conclusão do teste. O ambiente de desenvolvimento também pode exigir acesso ao catálogo de preparação para fins de depuração.
2. código de mesclagem
data scientists Desenvolver o modelo de treinamento pipeline no ambiente de desenvolvimento usando tabelas dos catálogos de desenvolvimento ou produção.
-
Solicitação pull. O processo de implantação começa quando uma pull request é criada na ramificação principal do projeto no controle de origem.
-
Testes unitários (CI). O pull request cria automaticamente o código-fonte e aciona testes de unidade. Se os testes de unidade falharem, a solicitação pull será rejeitada.
Os testes de unidade fazem parte do processo de desenvolvimento de software e são continuamente executados e adicionados à base de código durante o desenvolvimento de qualquer código. A execução de testes de unidade como parte de um pipeline de CI garante que as alterações feitas em uma ramificação de desenvolvimento não prejudiquem a funcionalidade existente.
3. Testes de integração (CI)
Em seguida, o processo de CI executa os testes de integração. Os testes de integração executam todos os pipelines (incluindo engenharia de recursos, treinamento de modelos, inferência e monitoramento) para garantir que funcionem corretamente em conjunto. O ambiente de teste deve corresponder ao ambiente de produção da forma mais adequada possível.
Se o senhor estiver implantando um aplicativo ML com inferência de tempo real, deverá criar e testar a infraestrutura de serviço no ambiente de preparação. Isso envolve o acionamento do pipeline de implantação do modelo, que cria um endpoint de serviço no ambiente de preparação e carrega um modelo.
Para reduzir o tempo necessário para a execução de testes de integração, algumas etapas podem ser negociadas entre a fidelidade do teste e a velocidade ou o custo. Por exemplo, se os modelos forem caros ou demorados para serem treinados, o senhor poderá usar pequenos subconjuntos de dados ou executar menos iterações de treinamento. Para o modelo de serviço, dependendo dos requisitos de produção, o senhor pode fazer testes de carga de escala completa em testes de integração ou pode apenas testar pequenos trabalhos em lote ou solicitações para um site temporário endpoint.
4. mesclar com a ramificação de preparação
Se todos os testes forem aprovados, o novo código será mesclado na ramificação principal do projeto. Se os testes falharem, o sistema CI/CD deverá notificar os usuários e publicar os resultados na solicitação pull.
O senhor pode programar testes de integração periódicos na ramificação principal. Essa é uma boa ideia se o branch for atualizado frequentemente com pull requests concorrente de vários usuários.
5. Crie uma ramificação de lançamento
Depois que os testes de CI forem aprovados e a ramificação de desenvolvimento for mesclada à ramificação principal, o engenheiro do ML cria uma ramificação de lançamento, que aciona o sistema CI/CD para atualizar o trabalho de produção.
Etapa de produção
ML Os engenheiros possuem o ambiente de produção em que o pipeline ML é implantado e executado. Esses pipelines acionam o treinamento de modelos, validam e implantam novas versões de modelos, publicam previsões em tabelas ou aplicativos downstream e monitoram todo o processo para evitar a degradação e a instabilidade do desempenho.
data scientists Normalmente, o senhor não tem acesso de gravação ou compute no ambiente de produção. No entanto, é importante que eles tenham visibilidade dos resultados dos testes, dos artefatos registrados nos modelos, do status da produção pipeline e das tabelas de monitoramento. Essa visibilidade permite identificar e diagnosticar problemas na produção e comparar o desempenho de novos modelos com os modelos atualmente em produção. O senhor pode conceder a data scientists acesso somente leitura ao ativo no catálogo de produção para esses fins.
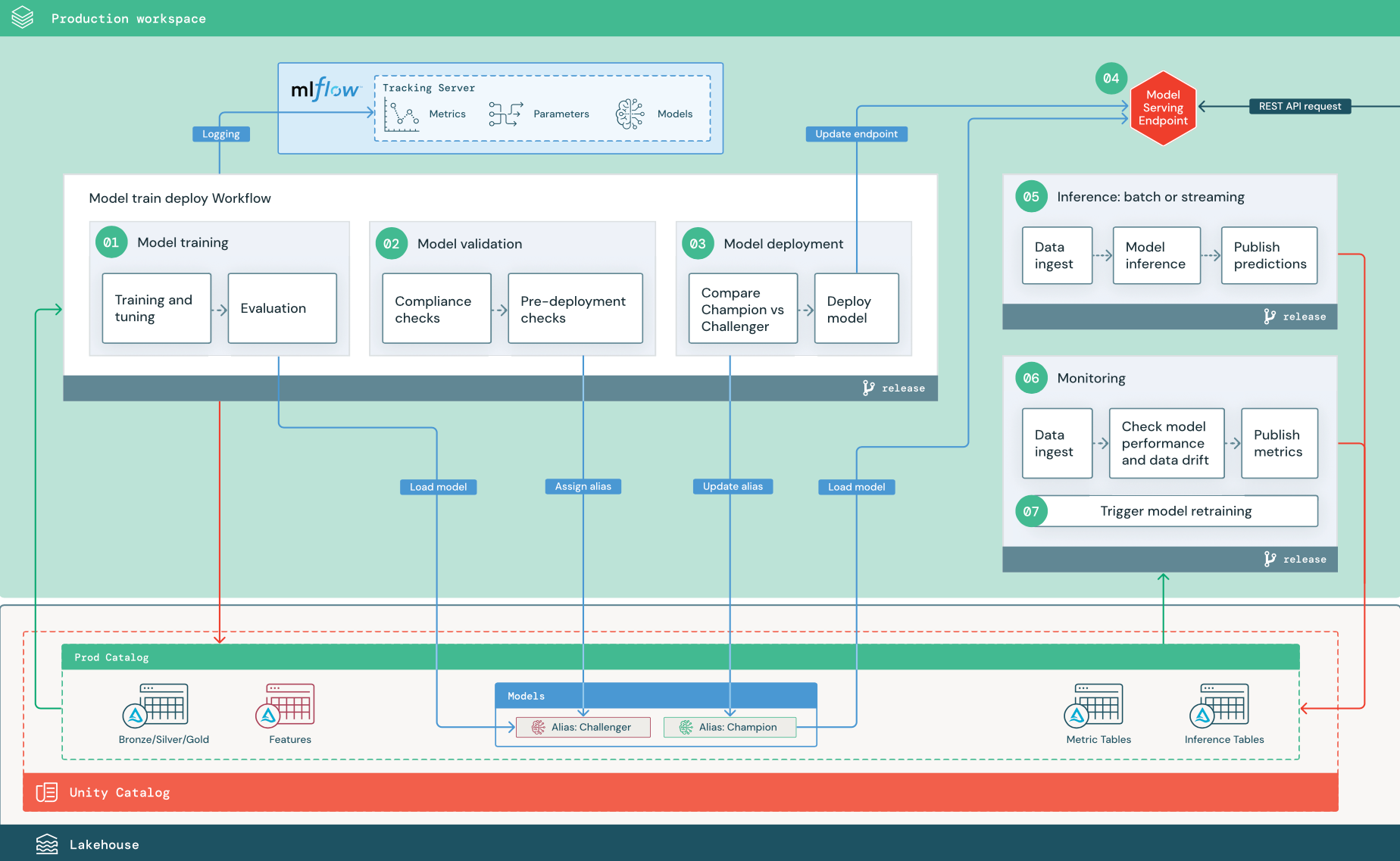
As etapas numeradas correspondem aos números mostrados no diagrama.
1. Modelo de trem
Esse pipeline pode ser acionado por alterações no código ou por um trabalho de reciclagem automatizado. Nesta etapa, as tabelas do catálogo de produção são usadas nas etapas a seguir.
-
treinamento e afinação. Durante o processo de treinamento, o logs é registrado no ambiente de produção MLflow servidor de acompanhamento. Esses logs incluem métricas de modelos, parâmetros, tags e o próprio modelo. Se o senhor usar tabelas de recurso, o modelo será registrado no site MLflow usando o cliente Databricks recurso Store, que agrupa o modelo com informações de pesquisa de recurso que são usadas no momento da inferência.
Durante o desenvolvimento, o site data scientists pode testar muitos algoritmos e hiperparâmetros. No código de treinamento de produção, é comum considerar apenas as opções com melhor desempenho. Limitar o ajuste dessa forma economiza tempo e pode reduzir a variação do ajuste no treinamento automatizado.
Se o site data scientists tiver acesso somente de leitura ao catálogo de produção, ele poderá determinar o conjunto ideal de hiperparâmetros para um modelo. Nesse caso, o pipeline de treinamento do modelo implantado na produção pode ser executado usando o conjunto selecionado de hiperparâmetros, normalmente incluído no pipeline como um arquivo de configuração.
-
Avaliação. A qualidade do modelo é avaliada por testes em dados de produção retidos. Os resultados desses testes são logs no servidor de acompanhamento do MLflow. Esta passo usa as métricas de avaliação especificadas pelo cientista de dados na passo de desenvolvimento. Essas métricas podem incluir código personalizado.
-
Modelo de registro. Quando o treinamento do modelo é concluído, o artefato do modelo é salvo como uma versão do modelo registrado no caminho do modelo especificado no catálogo de produção no Unity Catalog. A tarefa de treinamento do modelo produz um URI de modelo que a tarefa de validação do modelo pode usar. O senhor pode usar valores de tarefa para passar esse URI para o modelo.
2. Validar modelo
Esse pipeline usa o URI do modelo da Etapa 1 e carrega o modelo do Unity Catalog. Em seguida, ele executa uma série de verificações de validação. Essas verificações dependem de sua organização e do caso de uso e podem incluir itens como validações básicas de formato e metadados, avaliações de desempenho em fatias de dados selecionadas e compliance requisitos organizacionais, como verificações de compliance para tags ou documentação.
Se o modelo passar com êxito em todas as verificações de validação, o senhor poderá atribuir o alias "Challenger" à versão do modelo no Unity Catalog. Se o modelo não passar em todas as verificações de validação, o processo será encerrado e os usuários poderão ser notificados automaticamente. O senhor pode usar tags para adicionar atributos key-value, dependendo do resultado dessas verificações de validação. Por exemplo, o senhor pode criar uma tag "model_validation_status" e definir o valor como "PENDING" à medida que os testes são executados e, em seguida, atualizá-la para "PASSED" ou "FAILED" quando o pipeline for concluído.
Como o modelo está registrado em Unity Catalog, data scientists que trabalha no ambiente de desenvolvimento pode carregar essa versão do modelo do catálogo de produção para investigar se o modelo falha na validação. Independentemente do resultado, os resultados são registrados para o modelo registrado no catálogo de produção usando a anotação para a versão do modelo.
3. modelo implantado
Assim como o pipeline de validação, o pipeline de implementação do modelo depende de sua organização e do caso de uso. Esta seção presume que você atribuiu ao modelo recém-validado o alias “Challenger” e que o modelo de produção existente recebeu o alias “Champion”. A primeira etapa antes de implantar o novo modelo é confirmar que seu desempenho é, no mínimo, tão bom quanto o do modelo de produção atual.
-
Compare o modelo “CHALLENGER” com o modelo “CHAMPION”. Você pode realizar essa comparação offline ou online. Uma comparação off-line avalia os dois modelos em relação a um conjunto de dados retidos e acompanha os resultados usando o servidor de acompanhamento MLflow. Para o tempo real servindo o modelo, talvez o senhor queira realizar comparações on-line de longa duração, como testes A/B ou uma implementação gradual do novo modelo. Se a versão do modelo “Challenger” tiver um desempenho melhor na comparação, ela substituirá o alias “Champion” atual.
Mosaic AI Model Serving e o perfil de dados permitem coletar e monitorar automaticamente tabelas de inferência que contêm dados de requisição e resposta para um endpoint.
Se não houver um modelo "Campeão" existente, o senhor pode comparar o modelo "Desafiador" com uma heurística de negócios ou outro limite como linha de base.
O processo descrito aqui é totalmente automatizado. Se forem necessárias etapas de aprovação manual, o senhor poderá configurá-las usando notificações de fluxo de trabalho ou retornos de chamada de CI/CD do pipeline de implantação do modelo.
-
modelo implantado. lotes ou pipeline de inferência de transmissão pode ser configurado para usar o modelo com o alias "Champion". Para casos de uso reais de tempo, o senhor deve configurar a infraestrutura para implantar o modelo como um REST API endpoint. O senhor pode criar e gerenciar esse endpoint usando o Mosaic AI Model Serving. Se um endpoint já estiver em uso para o modelo atual, o senhor pode atualizar o endpoint com o novo modelo. O Mosaic AI Model Serving executa uma atualização sem tempo de inatividade, mantendo a configuração existente em execução até que a nova esteja pronta.
4. servindo modelo
Ao configurar um modelo servindo endpoint, o senhor especifica o nome do modelo em Unity Catalog e a versão a ser servida. Se a versão do modelo foi treinada usando recurso de tabelas em Unity Catalog, o modelo armazena as dependências para o recurso e as funções. O servindo modelo usa automaticamente esse gráfico de dependência para procurar recursos em lojas on-line apropriadas no momento da inferência. Essa abordagem também pode ser usada para aplicar funções de pré-processamento de dados ou para compute recurso on-demand durante a pontuação do modelo.
O senhor pode criar um único endpoint com vários modelos e especificar a divisão do tráfego do endpoint entre esses modelos, o que lhe permite realizar comparações on-line entre "Campeão" e "Desafiante".
5. Inferência: lotes ou transmissão
A inferência pipeline lê os dados mais recentes do catálogo de produção, executa funções para compute recurso on-demand, carrega o modelo "Champion", pontua os dados e retorna as previsões. A inferência de lotes ou transmissão é, em geral, a opção mais econômica para casos de uso com maior taxa de transferência e maior latência. keyPara cenários em que são necessárias previsões de baixa latência, mas as previsões podem ser computadas off-line, essas previsões de lotes podem ser publicadas em um armazenamento de valores on-line, como o DynamoDB ou o Cosmos DB.
O modelo registrado no Unity Catalog é referenciado por seu alias. O pipeline de inferência está configurado para carregar e aplicar a versão do modelo "Champion". Se a versão "Champion" for atualizada para uma nova versão do modelo, o pipeline de inferência usará automaticamente a nova versão em sua próxima execução. Dessa forma, a etapa de implantação do modelo é desacoplada do pipeline de inferência.
O trabalho em lote normalmente publica previsões em tabelas do catálogo de produção, em arquivos simples ou em uma conexão JDBC. Transmissão O trabalho normalmente publica previsões em tabelas Unity Catalog ou em filas de mensagens como Apache Kafka.
6. perfil de dados
A análise de perfil de dados monitora propriedades estatísticas, como deriva de dados e desempenho do modelo, tanto dos dados de entrada quanto das previsões do modelo. Você pode criar alertas com base nesses dados ou publicá-los em painéis.
- ingestão de dados. Este pipeline lê em logs from lotes, transmissão, ou inferência on-line.
- Verificar a precisão e a deriva dos dados. O pipeline computacionaliza informações sobre os dados de entrada, as previsões do modelo e o desempenho da infraestrutura. data scientists especificam as métricas de dados e modelos durante o desenvolvimento, enquanto os engenheiros ML especificam as métricas de infraestrutura. Você também pode definir métricas personalizadas.
- Publique métricas e faça alertas. O pipeline grava em tabelas no catálogo de produção para análise e geração de relatórios. O senhor deve configurar essas tabelas para que possam ser lidas no ambiente de desenvolvimento para que o site data scientists tenha acesso para análise. O senhor pode usar o site Databricks SQL para criar painéis de monitoramento para acompanhar o desempenho do modelo e configurar o Job de monitoramento ou a ferramenta de painel para emitir uma notificação quando uma métrica exceder um limite especificado.
- Reciclagem do modelo Trigger. Quando as métricas de monitoramento indicam problemas de desempenho ou alterações nos dados de entrada, o cientista de dados pode precisar desenvolver uma nova versão do modelo. O senhor pode configurar o alerta SQL para notificar data scientists quando isso acontecer.
7. Reciclagem
Essa arquitetura suporta o retreinamento automático usando o mesmo pipeline de treinamento de modelo acima. A Databricks recomenda começar com o retreinamento programado e periódico e passar para o retreinamento acionado quando necessário.
- Programado. Se novos dados estiverem disponíveis regularmente, o senhor poderá criar um trabalho programado para executar o código de treinamento do modelo com base nos últimos dados disponíveis. Consulte Automatização de trabalhos com programas e acionadores
- Acionado. Se o monitoramento pipeline puder identificar problemas de desempenho do modelo e enviar um alerta, ele também poderá acionar o retreinamento. Por exemplo, se a distribuição dos dados de entrada mudar significativamente ou se o desempenho do modelo piorar, o retreinamento e a reimplantação automáticos podem aumentar o desempenho do modelo com o mínimo de intervenção humana. Isso pode ser feito por meio de um SQL alerta para verificar se uma métrica é anômala (por exemplo, verificar o desvio ou a qualidade do modelo em relação a um limite). O alerta pode ser configurado para usar um destino de webhook, que pode posteriormente acionar o fluxo de trabalho de treinamento.
Se o retreinamento pipeline ou outro pipeline apresentar problemas de desempenho, o cientista de dados talvez precise retornar ao ambiente de desenvolvimento para fazer mais experimentos e resolver os problemas.