従来の HIPPA サポートのクラスターを作成および確認する
この記事は、従来の HIPPA コンプライアンス機能に適用されます。 E2 プラットフォームでの HIPPA コンプライアンス機能の概要については、 HIPPA の記事を参照してください。
ワークスペースで従来の HIPPA サポートを使用している場合は、次の手順を使用して、 PHI データを処理するための HIPPA コンプライアンス機能のクラスターを作成および検証します。
-
クラスターを作成する
コンピュート設定リファレンスの指示に従います。構成手順の一部として、 Databricks ランタイム バージョンを選択する必要があります。
Databricks Runtime for Machine Learning には、 MPI (Message Passing Interface) やその他の低レベルの通信プロトコルを使用する高パフォーマンスの分散機械学習パッケージが含まれています。 これらのプロトコルはネットワーク上での暗号化をネイティブにサポートしていないため、これらの ML パッケージは暗号化されていない機密データをネットワーク経由で送信する可能性があります。 これらのパッケージは、ワークフローがこれらのパッケージに依存しない場合、ネットワーク経由のデータ暗号化を変更しません。
これらの ML パッケージによってネットワーク経由で送信されるメッセージは、通常、ML モデル パラメーターまたはトレーニング データに関する要約統計のいずれかです。 したがって、通常、保護された医療情報などの機密データが暗号化されずにネットワーク経由で送信されることは想定されていません。 ただし、これらのパッケージの特定の構成または使用 (特定のモデル デザインなど) により、そのような情報を含むメッセージがネットワーク経由で送信される可能性があります。
次のパッケージが影響を受けます。
-
Horovod、HorovodEstimator、および HorovodRunner
-
分散型 TensorFlow
-
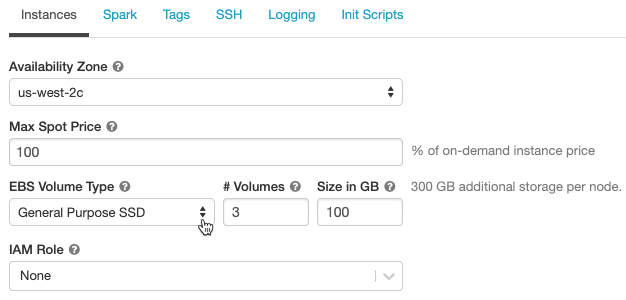
EBS ボリュームを使用したクラスターの設定 (レガシー HIPPA サポート)
EBS ボリュームをプロビジョニングします ( Databricks EBS ボリュームは暗号化されますが、デフォルト ローカル ストレージは暗号化されません)。
-
暗号化が有効になっていることを確認します。
-
ワークスペースにノートブックを作成し、前の手順で作成したクラスターにノートブックをアタッチします。
-
ノートブックで次のコマンドを実行します。
Scala%scala spark.conf.get("spark.ssl.enabled")戻り値が true の場合、暗号化が有効になっているクラスターが正常に作成されています。 そうでない場合は、 help@databricks.com に連絡してください。
-
spark-submit は、HIPAA 準拠のクラスターではサポートされていません。