MLflow 記録済みモデルを使用したモデルの追跡と比較
MLflow 記録済みモデルは、モデルのライフサイクル全体を通じてモデルの進行状況を追跡するのに役立ちます。 モデルをトレーニングするときは、 mlflow.<model-flavor>.log_model() を使用して、一意の ID を使用してすべての重要な情報を結び付ける LoggedModel を作成します。LoggedModelsの力を活用するには、MLflow 3 の使用を開始します。
生成AI アプリケーションの場合、 LoggedModels を作成して、git コミットまたはパラメーターのセットを専用オブジェクトとしてキャプチャし、トレースとメトリクスにリンクできます。ディープラーニングと従来の ML では、 LoggedModels は MLflow の実行から生成されます。これは MLflow の既存の概念であり、モデル コードを実行するジョブと考えることができます。トレーニング実行ではモデルが出力として生成され、評価ランでは既存のモデルを入力として使用して、モデルのパフォーマンスを評価するために使用できるメトリクスやその他の情報が生成されます。
LoggedModelオブジェクトは、モデルのライフサイクル全体を通じて、さまざまな環境間で保持され、メタデータ、メトリクス、パラメーター、モデルの生成に使用されたコードなどのアーティファクトへのリンクが含まれています。記録済みモデル トラッキングを使用すると、モデルを相互に比較し、最もパフォーマンスの高いモデルを見つけ、デバッグ中に情報を追跡できます。
記録済みモデルは、 Unity Catalog モデルレジストリにも登録できるので、 MLflow エクスペリメントやワークスペースのモデル情報を一箇所にまとめることができます。 詳細については、MLflow3でのモデルレジストリの改善を参照してください。
![]()
生成AIおよびディープラーニングモデルの追跡の改善
生成AI とディープラーニング ワークフローは、特に記録済みモデルが提供する詳細な追跡の恩恵を受けます。
生成AI - 統合された評価データとトレースデータ:
- 生成AI モデルは、評価とデプロイ中に、レビューアーのフィードバックデータやトレースなど、追加のメトリクスを生成します。
LoggedModelエンティティを使用すると、モデルによって生成されたすべての情報を 1 つのインターフェイスを使用してクエリできます。
ディープラーニング - 効率的なチェックポイント管理:
- ディープラーニングのトレーニングでは、トレーニング中の特定のポイントでのモデルの状態のスナップショットである複数のチェックポイントが作成されます。
- MLflowはチェックポイントごとに個別の
LoggedModelを作成し、モデルのメトリクスとパフォーマンスデータを含めます。 これにより、チェックポイントを比較および評価して、最もパフォーマンスの高いモデルを効率的に特定できます。
記録済みモデルの作成
記録済みモデルを作成するには、既存の ワークロードと同じlog_model()API MLflowを使用します。次のコード スニペットは、生成AI、ディープラーニング、および従来の ML ワークフローの記録済みモデルを作成する方法を示しています。
実行可能なノートブックの完全な例については、「 ノートブックの例」を参照してください。
- Gen AI
- Deep learning
- Traditional ML
次のコード スニペットは、LangChain エージェントをログに記録する方法を示しています。エージェントのフレーバーに log_model() 方法を使用してください。
# Log the chain with MLflow, specifying its parameters
# As a new feature, the LoggedModel entity is linked to its name and params
model_info = mlflow.langchain.log_model(
lc_model=chain,
name="basic_chain",
params={
"temperature": 0.1,
"max_tokens": 2000,
"prompt_template": str(prompt)
},
model_type="agent",
input_example={"messages": "What is MLflow?"},
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
評価ジョブを開始し、LoggedModelの一意のmodel_idを指定して、メトリクスを記録済みモデルにリンクします。
# Start a run to represent the evaluation job
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# Run the agent evaluation
result = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# Log evaluation metrics and associate with agent
mlflow.log_metrics(
metrics=result.metrics,
dataset=eval_dataset,
# Specify the ID of the agent logged above
model_id=logged_model.model_id
)
次のコード スニペットは、ディープラーニング トレーニング中に記録済みモデルを作成する方法を示しています。 MLflow モデルの種類に適した log_model() メソッドを使用します。
# Start a run to represent the training job
with mlflow.start_run():
# Load the training dataset with MLflow. We will link training metrics to this dataset.
train_dataset: Dataset = mlflow.data.from_pandas(train_df, name="train")
X_train, y_train = prepare_data(train_dataset.df)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(scripted_model.parameters(), lr=0.01)
for epoch in range(101):
X_train, y_train = X_train.to(device), y_train.to(device)
out = scripted_model(X_train)
loss = criterion(out, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Obtain input and output examples for MLflow Model signature creation
with torch.no_grad():
input_example = X_train[:1]
output_example = scripted_model(input_example)
# Log a checkpoint with metrics every 10 epochs
if epoch % 10 == 0:
# Each newly created LoggedModel checkpoint is linked with its
# name, params, and step
model_info = mlflow.pytorch.log_model(
pytorch_model=scripted_model,
name=f"torch-iris-{epoch}",
params={
"n_layers": 3,
"activation": "ReLU",
"criterion": "CrossEntropyLoss",
"optimizer": "Adam"
},
step=epoch,
signature=mlflow.models.infer_signature(
model_input=input_example.cpu().numpy(),
model_output=output_example.cpu().numpy(),
),
input_example=X_train.cpu().numpy(),
)
# Log metric on training dataset at step and link to LoggedModel
mlflow.log_metric(
key="accuracy",
value=compute_accuracy(scripted_model, X_train, y_train),
step=epoch,
model_id=model_info.model_id,
dataset=train_dataset
)
次のコード スニペットは、sklearn モデルをログに記録し、メトリクスを Logged Modelにリンクする方法を示しています。MLflow モデルの種類に適した log_model() メソッドを使用します。
## Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
name="elasticnet",
params={
"alpha": 0.5,
"l1_ratio": 0.5,
},
input_example = train_x
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
# Evaluate the model on the training dataset and log metrics
# These metrics are now linked to the LoggedModel entity
predictions = lr.predict(train_x)
(rmse, mae, r2) = compute_metrics(train_y, predictions)
mlflow.log_metrics(
metrics={
"rmse": rmse,
"r2": r2,
"mae": mae,
},
model_id=logged_model.model_id,
dataset=train_dataset
)
ノートブックの例
たとえば、 LoggedModelsの使用方法を示すノートブックについては、次のページを参照してください。
モデルの表示と進行状況の追跡
記録済みモデルは、ワークスペース UI で表示できます。
- ワークスペースの エクスペリメント タブに移動します。
- エクスペリメントを選択します。 次に、[ モデル ] タブを選択します。
このページには、エクスペリメントに関連付けられているすべての記録済みモデルと、そのメトリクス、パラメーター、アーティファクトが含まれています。
![]()
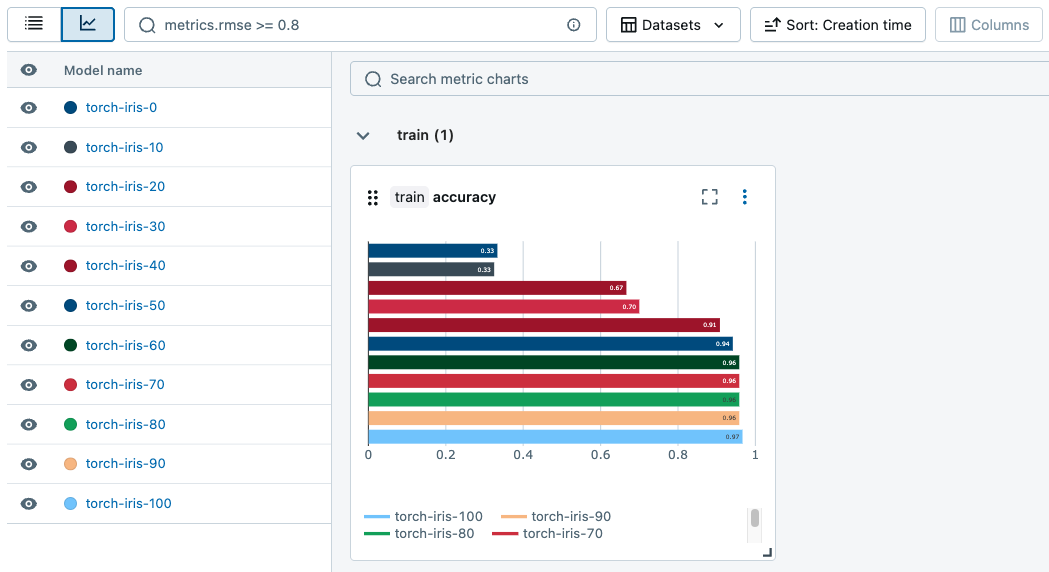
実行全体でメトリクスを追跡するためのチャートを生成できます。
記録済みモデルの検索とフィルタリング
モデル タブでは、属性、パラメーター、タグ、メトリクスに基づいて記録済みモデルを検索およびフィルタリングできます。
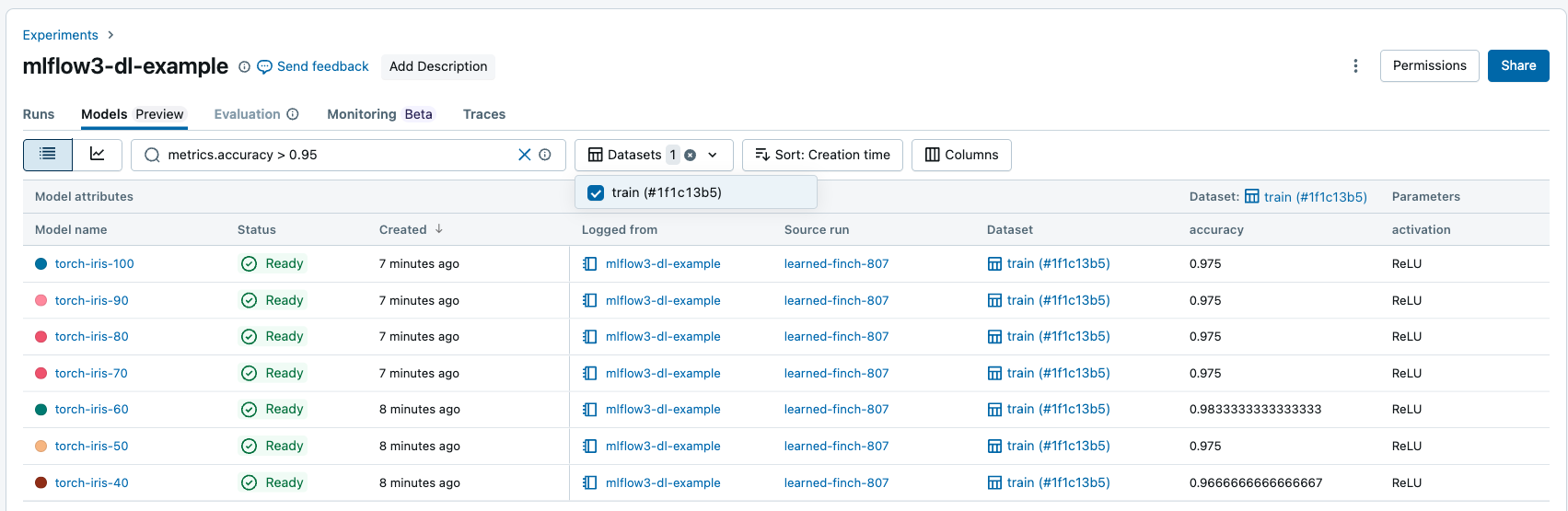
データセット固有のパフォーマンスに基づいてメトリクスをフィルタリングでき、特定のデータセットでメトリクス値が一致するモデルのみが返されます。 データセット フィルターがメトリクス フィルターなしで提供されている場合、それらのデータセットに 任意の メトリクスを持つモデルが返されます。
次の属性に基づいてフィルタリングできます。
model_idmodel_namestatusartifact_uricreation_time(数値)last_updated_time(数値)
次の演算子を使用して、文字列に似た属性、パラメーター、タグを検索およびフィルター処理します。
=、!=、IN、NOT IN
次の比較演算子を使用して、数値属性とメトリクスを検索およびフィルタリングします。
=、!=、>、<、>=、<=
プログラムからの記録済みモデルの検索
記録済みモデルは、次の MLflow APIを使用して検索できます。
## Get a Logged Model using a model_id
mlflow.get_logged_model(model_id = <my-model-id>)
## Get all Logged Models that you have access to
mlflow.search_logged_models()
## Get all Logged Models with a specific name
mlflow.search_logged_models(
filter_string = "model_name = <my-model-name>"
)
## Get all Logged Models created within a certain time range
mlflow.search_logged_models(
filter_string = "creation_time >= <creation_time_start> AND creation_time <= <creation_time_end>"
)
## Get all Logged Models with a specific param value
mlflow.search_logged_models(
filter_string = "params.<param_name> = <param_value_1>"
)
## Get all Logged Models with specific tag values
mlflow.search_logged_models(
filter_string = "tags.<tag_name> IN (<tag_value_1>, <tag_value_2>)"
)
## Get all Logged Models greater than a specific metric value on a dataset, then order by that metric value
mlflow.search_logged_models(
filter_string = "metrics.<metric_name> >= <metric_value>",
datasets = [
{"dataset_name": <dataset_name>, "dataset_digest": <dataset_digest>}
],
order_by = [
{"field_name": metrics.<metric_name>, "dataset_name": <dataset_name>,"dataset_digest": <dataset_digest>}
]
)
詳細情報と追加の 検索 パラメーターについては、 MLflow 3 API の資料を参照してください。
モデルの入力と出力による検索実行
モデル ID で実行を検索すると、入力または出力として記録済みモデルを持つすべての実行を返すことができます。 フィルター文字列の構文の詳細については、「 実行のフィルター処理」を参照してください。
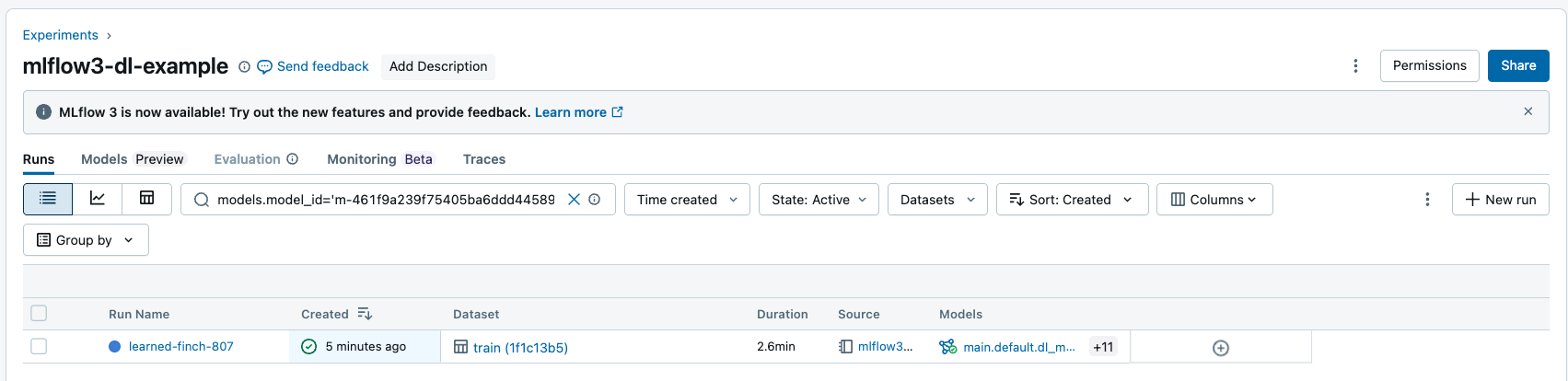
MLflow API を使用して実行を検索できます。
## Get all Runs with a particular model as an input or output by model id
mlflow.search_runs(filter_string = "models.model_id = <my-model-id>")
その他のリソース
MLflow 3 のその他の新機能の詳細については、次の記事を参照してください。