モデル用のMLflow 3を使い始める
この記事では、従来の機械学習とディープラーニング モデル向けの MLflow 3 の機能に焦点を当てます。MLflow 3 は、トレース、評価、人間からのフィードバック収集など、GenAI アプリケーション開発のための包括的な機能も提供します。詳細については、 GenAI の MLflow 3 を参照してください。
この記事では、機械学習モデルの開発に MLflow 3 を使い始める方法を説明します。モデル用の MLflow 3 をインストールする方法について説明し、開始するためのデモ ノートブックをいくつか含めています。また、モデル用の MLflow 3 の新機能について詳しく説明しているページへのリンクも含まれています。
モデル用の MLflow 3 とは何ですか?
Databricks上のモデル用MLflow 3 は、機械学習モデルの最先端の体験追跡、パフォーマンス評価、本番運用管理を提供します。 MLflow 3 では、コアとなる追跡概念を維持しながら重要な新機能が導入され、MLflow 2.x からの移行が迅速かつ簡単に行えます。
GenAI 向け MLflow 3 とは何ですか?
MLflow 3 for Models に加えて、MLflow 3 for GenAI では、エージェントおよび GenAI アプリケーション開発向けのさまざまな新機能と改善が導入されています。包括的な概要については、 MLflow 3 for GenAI を参照してください。
GenAI 向け MLflow 3 の主要機能は次のとおりです。
- トレースと可観測性 - OpenAI、LangChain、LlamaIndex、Anthropic を含む 20 以上のフレームワークの自動計測機能を備えた GenAI アプリケーションのエンドツーエンドの可観測性
- 評価とモニタリング - 開発から本番運用までの品質を測定および改善するための包括的な GenAI 評価機能。 組み込みLLMジャッジ、カスタマイズ可能なジャッジ、評価データセット管理、および継続モニタリングが含まれます。
- 人間のフィードバック収集 - ドメイン専門家のフィードバックを収集し、エージェントをインタラクティブにテストするためのカスタマイズ可能なレビュー UI。レビューの進行状況を整理および追跡するための構造化されたラベル付けセッションを備えています。
- プロンプト レジストリ - Unity Catalog統合によるプロンプトのバージョン管理、管理、A/B テストの一元化
MLflow 3のモデルはMLflow 2とどう違うのか
Databricks 上のモデル用の MLflow 3 を使用すると、次のことが可能になります。
- 開発ノートブックでのインタラクティブなクエリから本番運用バッチまたは途中のデプロイメントに至るまで、すべての環境にわたるモデルのパフォーマンスを一元的に追跡および分析します。
![]()
- Unity Catalog のモデル バージョン ページと、REST APIのすべてのワークスペースとエクスペリメントで、モデル メトリクスとパラメーターを表示してアクセスします。
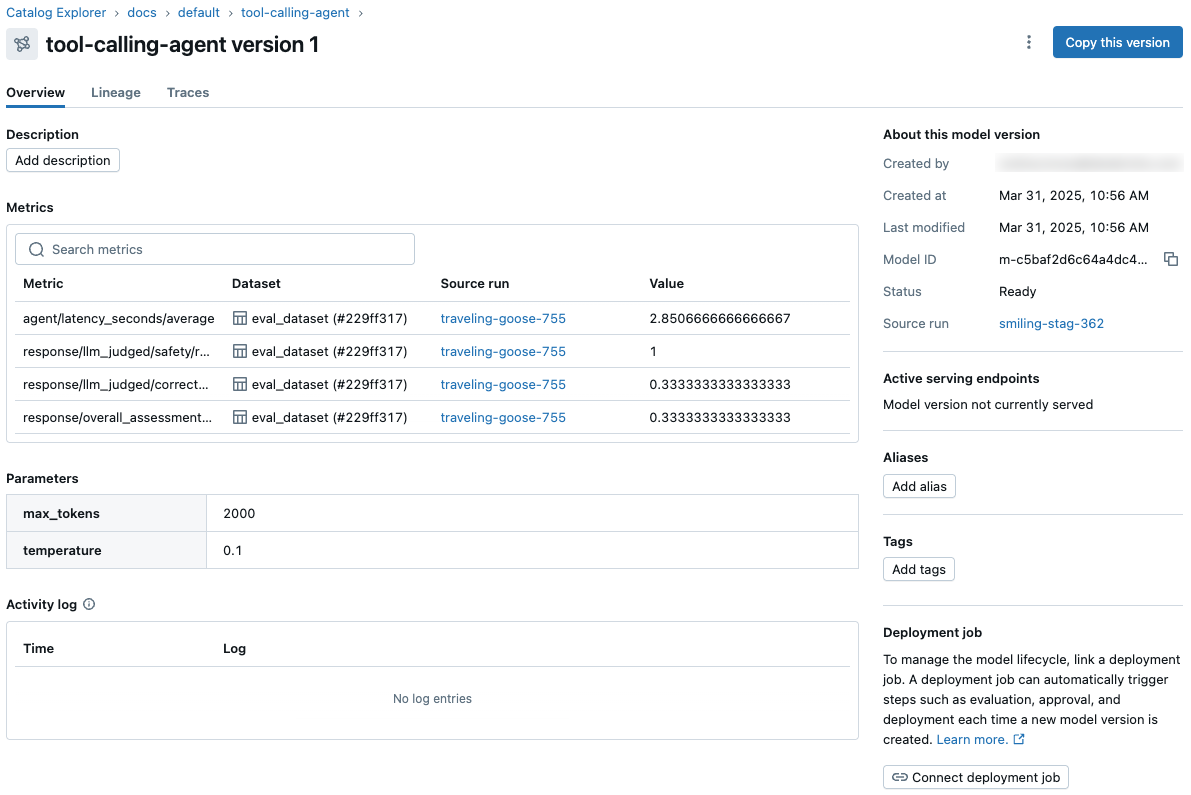
- Unity Catalog を使用して評価とデプロイメントのワークフローを調整し、モデルの各バージョンの包括的なステータス ログにアクセスします。
これらの機能により、機械学習モデルの開発、評価、および本番運用の展開が簡素化および合理化されます。
記録済みモデル
MLflow 3 の新機能の多くは、 LoggedModelの新しい概念から派生しています。ディープラーニングと従来の機械学習モデルの場合、 LoggedModelsトレーニング実行によって生成されるモデルの概念を高め、さまざまなトレーニング実行と評価ランにわたってモデルのライフサイクルを追跡するための専用オブジェクトとして確立します。
LoggedModels 開発のフェーズ (トレーニングと評価) および環境 (開発、ステージング、本番運用) 間で、メトリクス、パラメーター、トレースをキャプチャします。 LoggedModelをモデルバージョンとしてUnity Catalogに昇格すると、元のLoggedModelのすべてのパフォーマンスデータがUCモデルバージョンページに表示されるようになり、すべてのワークスペースとエクスペリメントを可視化できます。詳細については、「MLflow 記録済みモデルを使用したモデルの追跡と比較」を参照してください。
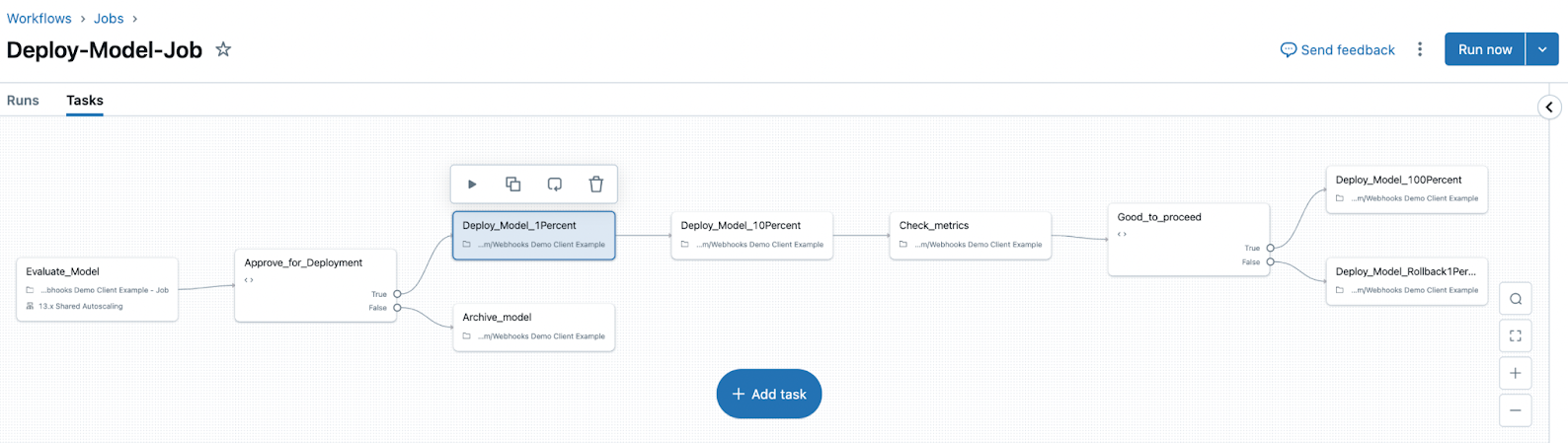
デプロイ ジョブ
MLflow 3 では、デプロイ ジョブの概念も導入されています。デプロイ ジョブは、 Lakeflow ジョブを使用して、評価、承認、デプロイなどの手順を含むモデルのライフサイクルを管理します。 これらのモデル ワークフローは Unity Catalog によって管理され、すべてのイベントは Unity Catalog のモデル バージョン ページで使用できるアクティビティ ログに保存されます。
MLflow 2.x からの移行
MLflow 3 には多くの新機能がありますが、エクスペリメントと実行のコア概念と、パラメーター、タグ、メトリクスなどのメタデータはすべて同じままです。MLflow 2.x から 3.0 への移行は非常に簡単で、ほとんどの場合、コードの変更は最小限で済みます。このセクションでは、MLflow 2.x との主な違いと、シームレスな移行のために注意すべき点について説明します。
ロギングモデル
2.x でモデルをログに記録する場合は、 artifact_path パラメーターが使用されます。
with mlflow.start_run():
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=python_model,
...
)
MLflow 3 では、代わりに name を使用すると、後でモデルを名前で検索できます。artifact_path パラメーターは引き続きサポートされていますが、非推奨になりました。さらに、MLflow 3 ではモデルが最優先になったため、MLflow ではモデルのログ記録時に実行をアクティブにする必要がなくなりました。最初に実行を開始せずに、モデルを直接ログに記録できます。
mlflow.pyfunc.log_model(
name="model",
python_model=python_model,
...
)
アーティファクトのモデル化
MLflow 2.x では、モデル アーティファクトは、実行のアーティファクト パスの下に実行アーティファクトとして格納されます。MLflow 3 では、モデル アーティファクトは、モデルのアーティファクト パスの下の別の場所に格納されるようになりました。
# MLflow 2.x
experiments/
└── <experiment_id>/
└── <run_id>/
└── artifacts/
└── ... # model artifacts are stored here
# MLflow 3
experiments/
└── <experiment_id>/
└── models/
└── <model_id>/
└── artifacts/
└── ... # model artifacts are stored here
問題を回避するために、mlflow.<model-flavor>.log_model から返されるモデル URI を使用して mlflow.<model-flavor>.load_model でモデルを読み込むことをお勧めします。このモデル URI は models:/<model_id> 形式 (MLflow 2.x のように runs:/<run_id>/<artifact_path> ではなく) であり、モデル ID のみが使用可能な場合は手動で作成することもできます。
モデルレジストリ
MLflow3 では、デフォルト レジストリ URI がdatabricks-uc になり、Unity CatalogのMLflowモデルレジストリが使用されます (詳細については、「Unity Catalogでのモデルのライフサイクルの管理 」を参照してください)。Unity Catalog に登録されているモデルの名前は、<catalog>.<schema>.<model>という形式です。mlflow.register_modelなど、登録済みのモデル名が必要なAPIsを呼び出す場合は、この完全な 3 レベルの名前が使用されます。
Unity Catalogが有効で、デフォルト カタログが Unity Catalogにあるワークスペースの場合、名前として <model> を使用することもできますが、デフォルトのカタログとスキーマが推測されます (MLflow 2.x からの動作の変更はありません)。ワークスペースが Unity Catalog 有効になっているが、 そのデフォルトカタログ が Unity Catalogに設定されていない場合は、完全な 3 レベル名を指定する必要があります。
DatabricksはUnity CatalogのMLflowモデルレジストリを使用して、モデルのライフサイクルを管理することをお勧めします。
Workspace Model Registry (legacy) を引き続き使用する場合は、次のいずれかの方法を使用してレジストリ URI を databricksに設定します。
mlflow.set_registry_uri("databricks")を使用してください。- 環境変数 をMLFLOW_REGISTRY_URIに設定します。
- レジストリURIの環境変数を大規模に設定するには、 initスクリプトを使用できます。 これには 汎用コンピュートが必要です。
その他の重要な変更
- MLflow 3 クライアントは、MLflow 2.x クライアントでログに記録されたすべての実行、モデル、トレースを読み込むことができます。ただし、必ずしもその逆であるとは限らないため、MLflow 3 クライアントでログ記録されたモデルとトレースは、古い 2.x クライアント バージョンで読み込むことができない場合があります。
mlflow.evaluateAPI は非推奨になりました。従来の ML またはディープラーニング モデルの場合は、元のmlflow.evaluateAPI との完全な互換性を維持するmlflow.models.evaluateを使用します。LLM または GenAI アプリケーションの場合は、代わりにmlflow.genai.evaluateAPI を使用してください。run_uuid属性がRunInfoオブジェクトから削除されました。コードでは代わりにrun_idを使用してください。
MLflow 3 をインストールする
MLflow 3 を使用するには、正しい (>= 3.0) バージョンを使用するようにパッケージを更新する必要があります。次のコード行は、ノートブックが実行されるたびに実行する必要があります。
%pip install mlflow>=3.0 --upgrade
dbutils.library.restartPython()
ノートブックの例
MLflow次のページでは、従来のML ラーニングとディープラーニングの 3 モデル追跡ワークフローについて説明します。各ページには、サンプルノートブックが含まれています。
制限
Spark モデル ログ記録 ( mlflow.spark.log_model ) は MLflow 3 でも引き続き機能しますが、新しいLoggedModelの概念は使用されません。Sparkモデル ログを使用してログに記録されたモデルは、引き続きMLflow 2.x 実行および実行アーティファクトを使用します。
その他のリソース
MLflow 3 の新機能の詳細については、次の記事を参照してください。