Depure e analise seu aplicativo com rastreamento.
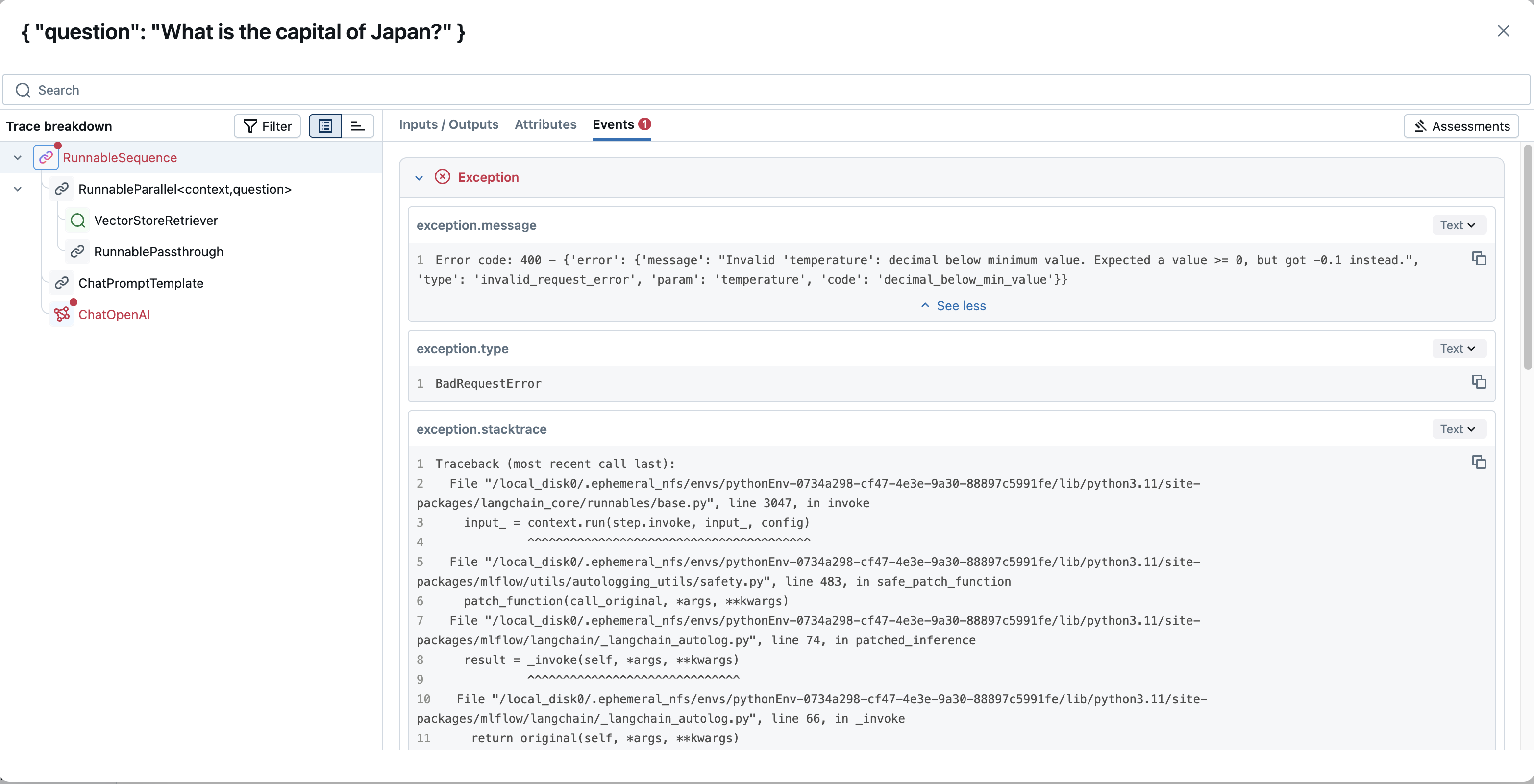
MLflow Tracing oferece uma visão profunda do comportamento do seu aplicativo, facilitando uma experiência completa em diferentes ambientes. Ao capturar o ciclo completo de solicitação-resposta (entrada/saída acompanhamento) e o fluxo de execução, você pode visualizar e compreender a lógica e o processo de tomada de decisão do seu aplicativo.
Examinar as entradas, saídas e metadados de cada etapa intermediária (por exemplo, recuperação de dados, chamadas de ferramentas, interações LLM ) e o feedback do usuário associado ou os resultados das avaliações de qualidade permite:
- Em desenvolvimento : Obtenha visibilidade detalhada do que acontece por baixo das abstrações da biblioteca GenAI, ajudando você a identificar com precisão onde ocorrem problemas ou comportamentos inesperados.
- Em produção : Monitore e depure problemas em tempo real. Os rastreamentos capturam erros e podem incluir métricas operacionais como latência em cada etapa, auxiliando em diagnósticos rápidos.
O MLflow Tracing oferece uma experiência unificada entre desenvolvimento e produção: você instrumenta seu aplicativo uma única vez e o rastreamento funciona de forma consistente em ambos os ambientes. Isso permite navegar pelos rastreamentos de forma integrada em seu ambiente preferido — seja seu IDE, Notebook ou painel de monitoramento de produção — eliminando o incômodo de alternar entre várias ferramentas ou pesquisar em logs extensos.
Monitorar o desempenho e otimizar custos
Compreender e otimizar o desempenho e o custo das suas aplicações GenAI é crucial. MLflow Tracing permite capturar e monitorar métricas operacionais key , como latência, custo e utilização de recursos em cada etapa da execução do seu aplicativo.
Isso permite que você:
- Rastrear e identificar gargalos de desempenho em pipelines complexos.
- Monitorar a utilização de recursos para garantir operações eficientes.
- Otimize a relação custo-benefício entendendo onde os recursos ou tokens são consumidos.
- Identifique áreas para melhoria de desempenho em seu código ou interações de modelo.
Além disso, MLflow Tracing é compatível com o OpenTelemetry , uma especificação de observabilidade padrão da indústria. Essa compatibilidade permite exportar seus dados de rastreamento para vários serviços em sua pilha de observabilidade existente. Consulte a seção Exportação do OpenTelemetry para obter mais detalhes.