RAGチェーンの品質向上
この記事では、RAGチェーンのコンポーネントを使用してRAGアプリの品質を向上させる方法について説明します。
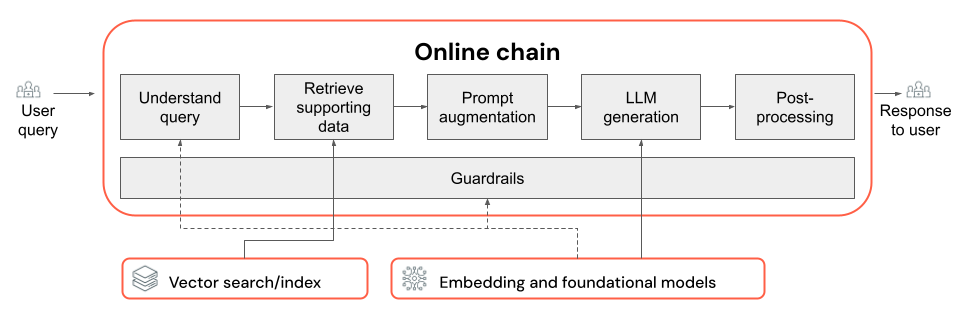
RAGチェーンは、ユーザークエリを入力として受け取り、そのクエリに基づいて関連情報を取得し、取得したデータに基づいて適切な応答を生成します。 RAGチェーン内の正確な手順は、ユースケースや要件によって大きく異なりますが、RAGチェーンを構築する際に考慮すべき主要なコンポーネントは次のとおりです。
- クエリの理解: ユーザークエリを分析および変換して、意図をより適切に表現し、フィルターやキーワードなどの関連情報を抽出して、取得プロセスを改善します。
- 検索: 検索クエリに対して最も関連性の高い情報のチャンクを見つける。 非構造化データの場合、通常、これにはセマンティック検索またはキーワードベースの検索の 1 つまたは組み合わせが含まれます。
- プロンプト増強: ユーザークエリと取得した情報および指示を組み合わせて、LLMが高品質の応答を生成するように導きます。
- LLM: アプリケーションに最適なモデル (およびモデル パラメーター) を選択して、パフォーマンス、レイテンシ、およびコストを最適化/バランスします。
- 後処理とガードレール: LLMが生成した回答がトピックに沿っており、事実に一貫性があり、特定のガイドラインや制約に準拠していることを確認するために、追加の処理手順と安全対策を適用する。
繰り返しの実装と品質改善の評価 では、チェーンのコンポーネントを反復処理する方法を示します。
クエリの理解
ユーザー クエリを取得クエリとして直接使用すると、一部のクエリで機能することがあります。 ただし、一般的には、取得ステップの前にクエリを再定式化することが有益です。 クエリの理解は、チェーンの先頭にあるステップ (または一連のステップ) で構成され、ユーザー クエリを分析および変換して、意図をより適切に表現し、関連情報を抽出し、最終的に後続の取得プロセスを支援します。 ユーザークエリを変換して取得を向上させる方法には、次のようなものがあります。
-
クエリの書き換え: クエリの書き換えには、ユーザー クエリを、元の意図をより適切に表す 1 つ以上のクエリに変換することが含まれます。 目標は、検索ステップで最も関連性の高いドキュメントを見つける可能性を高める方法でクエリを再定式化することです。 これは、取得ドキュメントで使用される用語と直接一致しない可能性のある複雑またはあいまいなクエリを処理する場合に特に便利です。
例:
- マルチターンチャットでの会話履歴の言い換え
- ユーザーのクエリのスペルミスの修正
- ユーザークエリ内の単語やフレーズを同義語に置き換えて、より広範な関連ドキュメントをキャプチャする
クエリの書き換えは、取得コンポーネントの変更と併せて行う必要があります
-
フィルター抽出: 場合によっては、ユーザークエリに特定のフィルターや条件が含まれており、それらを使用して検索結果を絞り込むことができます。 フィルター抽出では、これらのフィルターをクエリから識別して抽出し、追加のパラメーターとして取得ステップに渡します。 これにより、使用可能なデータの特定のサブセットに焦点を当てることで、取得したドキュメントの関連性を向上させることができます。
例:
- クエリに記載されている特定の期間 (「過去 6 か月の記事」や「2023 年のレポート」など) を抽出します。
- クエリ内の特定の製品、サービス、またはカテゴリ (「Databricks プロフェッショナル サービス」や「ラップトップ」など) の言及を特定します。
- クエリから地理的エンティティ (都市名や国コードなど) を抽出します。
フィルター抽出は、メタデータ抽出 データパイプライン と レトリーバーチェーン コンポーネントの両方に対する変更と併せて実行する必要があります。 メタデータ抽出ステップでは、関連するメタデータフィールドが各ドキュメント/チャンクで使用できることを確認し、抽出されたフィルターを受け入れて適用するための取得ステップを実装する必要があります。
クエリの書き換えとフィルター抽出に加えて、クエリの理解における別の重要な考慮事項は、単一の LLM 呼び出しを使用するか、複数の呼び出しを使用するかです。 慎重に作成されたプロンプトで 1 つの呼び出しを使用するのは効率的ですが、クエリの理解プロセスを複数の LLM 呼び出しに分割すると、より良い結果が得られる場合があります。 ちなみに、これは、1 つのプロンプトに多数の複雑なロジック ステップを実装しようとしている場合に一般的に適用される経験則です。
たとえば、1 つの LLM 呼び出しを使用してクエリの意図を分類し、別の LLM 呼び出しを使用して関連エンティティを抽出し、3 つ目の LLM 呼び出しを使用して抽出された情報に基づいてクエリを書き換えることができます。 このアプローチでは、プロセス全体に多少の遅延が加わる可能性がありますが、より詳細な制御が可能になり、取得されたドキュメントの品質が向上する可能性があります。
サポート ボットのマルチステップ クエリの理解
複数ステップのクエリ理解コンポーネントが顧客サポート ボットを検索する方法を次に示します。
- インテントの分類: LLM を使用して、ユーザーのクエリを "製品情報"、"トラブルシューティング"、"アカウント管理" などの定義済みのカテゴリに分類します。
- エンティティの抽出: 特定されたインテントに基づいて、別の LLM 呼び出しを使用して、製品名、報告されたエラー、アカウント番号など、クエリから関連エンティティを抽出します。
- クエリの書き換え: 抽出されたインテントとエンティティを使用して、元のクエリをより具体的でターゲットを絞った形式に書き換えます (例: "My RAG chain is failing to deploy on modelsaービング, I'm seeing the following error...")。
検索
RAGチェーンの検索コンポーネントは、検索クエリに対して最も関連性の高い情報のチャンクを見つける役割を担います。非構造化データのコンテキストでは、取得には通常、セマンティック検索、キーワードベースの検索、メタデータフィルタリングの 1 つまたは組み合わせが含まれます。取得方法の選択は、アプリケーションの特定の要件、データの性質、および処理するクエリの種類によって異なります。これらのオプションを比較してみましょう。
- セマンティック検索: セマンティック検索では、埋め込みモデルを使用して、テキストの各チャンクを、そのセマンティックな意味をキャプチャするベクトル表現に変換します。取得クエリのベクトル表現とチャンクのベクトル表現を比較することで、セマンティック検索では、クエリの正確なキーワードが含まれていなくても、概念的に類似したドキュメントを取得できます。
- キーワードベースの検索: キーワードベースの検索では、検索クエリとインデックス付きドキュメントの間で共有される単語の頻度と分布を分析することで、ドキュメントの関連性を判断します。 クエリとドキュメントの両方に同じ単語が出現する頻度が高いほど、そのドキュメントに割り当てられる関連性スコアが高くなります。
- ハイブリッド検索: ハイブリッド検索は、セマンティック検索とキーワードベースの検索の両方の長所を、2段階の検索プロセスを採用することで組み合わせます。 まず、セマンティック検索を実行して、概念的に関連性のあるドキュメントのセットを取得します。 次に、この削減されたセットにキーワードベースの検索を適用して、完全一致キーワードに基づいて結果をさらに絞り込みます。 最後に、両方のステップのスコアを組み合わせて、ドキュメントをランク付けします。
取得戦略の比較
次の表は、これらの各取得戦略を互いに比較したものです。
セマンティック検索 | キーワード検索 | ハイブリッド検索 | |
|---|---|---|---|
簡単な説明 | 同じ 概念 がクエリと潜在的なドキュメントに現れる場合、それらは関連性があります。 | クエリと潜在的なドキュメントに同じ 単語 が出現する場合、それらは関連性があります。 ドキュメント内のクエリの 単語数が多い ほど、そのドキュメントの関連性は高くなります。 | セマンティック検索とキーワード検索の両方を実行し、結果を結合します。 |
ユースケースの例 | ユーザーからの問い合わせが製品マニュアルの言葉と異なる場合の顧客サポート。 例:「電話の電源を入れるにはどうすればよいですか?」 マニュアルセクションは「電源の切り替え」と呼ばれます。 | クエリに特定の説明的でない専門用語が含まれている場合の顧客サポート。 例: 「モデルHD7-8Dは何をしますか?」 | セマンティック用語と技術用語の両方を組み合わせたクエリを顧客サポート 例: 「HD7-8D をオンにするにはどうすればよいですか?」 |
技術的なアプローチ | エンベディングを使用して連続ベクトル空間でテキストを表し、セマンティック検索を可能にします。 | キーワードの照合には、 bag-of-words、 TF-IDF、 BM25 などの個別のトークンベースの方法に依存します。 | 再ランク付けアプローチを使用して、逆ランク融合や再ランク付けモデルなど、結果を組み合わせます。 |
強み | クエリとコンテキスト的に類似した情報を取得する (正確な単語が使用されていない場合でも)。 | 正確なキーワード一致が必要なシナリオで、製品名など、特定の用語に焦点を当てたクエリに最適です。 | 両方のアプローチの長所を兼ね備えています。 |
検索プロセスを強化する方法
これらの主要な取得戦略に加えて、取得プロセスをさらに強化するために適用できるいくつかの手法があります。
- クエリの拡張: クエリ拡張は、取得クエリの複数のバリエーションを使用して、より広範な関連ドキュメントをキャプチャするのに役立ちます。 これは、拡張クエリごとに個別の検索を実行するか、すべての拡張検索クエリを 1 つの取得クエリに連結して使用することで実現できます。
クエリの拡張は、クエリ理解コンポーネント (RAG チェーン) の変更と併せて行う必要があります。 取得クエリの複数のバリエーションは、通常、この手順で生成されます。
- リランキング: チャンクの初期セットを取得したら、追加のランク付け条件 (時間による並べ替えなど) またはリランカーモデルを適用して結果を並べ替えます。 リランキングは、特定の取得クエリに対して最も関連性の高いチャンクに優先順位を付けるのに役立ちます。 mxbai-rerank や ColBERTv2 などのクロスエンコーダーモデルでリランキングすると、検索パフォーマンスが向上する可能性があります。
- メタデータのフィルタリング: クエリの理解手順から抽出されたメタデータ フィルターを使用して、特定の条件に基づいて検索空間を絞り込みます。 メタデータフィルターには、ドキュメントタイプ、作成日、作成者、ドメイン固有のタグなどの属性を含めることができます。 メタデータフィルターをセマンティック検索またはキーワードベースの検索と組み合わせることで、よりターゲットを絞った効率的な取得を作成できます。
メタデータのフィルタリングは、クエリの理解(RAGチェーン)およびメタデータ抽出(データパイプライン)コンポーネントの変更と併せて実行する必要があります。
プロンプトの拡張
プロンプト拡張は、ユーザー クエリをプロンプト テンプレートで取得した情報と指示と組み合わせて、言語モデルを高品質の応答を生成するようにガイドするステップです。 このテンプレートを反復処理して LLM に提供されるプロンプト (別名 プロンプトエンジニアリング ) を最適化するには、モデルが正確で接地された一貫性のある応答を生成するようにガイドされるようにする必要があります。
プロンプトエンジニアリングには完全なガイドがありますが、プロンプトテンプレートを反復処理する際に留意すべき考慮事項がいくつかあります。
-
例を挙げる
- 整形式のクエリとそれに対応する理想的な応答の例をプロンプトテンプレート自体に含めます(few-shot学習)。 これにより、モデルは応答の目的の形式、スタイル、および内容を理解できます。
- 良い例を思いつくための便利な方法の1つは、チェーンが苦労しているクエリの種類を特定することです。 これらのクエリに対してゴールドスタンダードの応答を作成し、プロンプトに例として含めます。
- 提供する例が、推論時に予想されるユーザークエリを代表するものであることを確認してください。 モデルがより適切に一般化できるように、予想されるさまざまなクエリをカバーすることを目指します。
-
プロンプトテンプレートをパラメーター化する
- プロンプト テンプレートをパラメーター化して、取得したデータとユーザー クエリ以外の追加情報を組み込むことで、柔軟性を持たせるように設計します。 これは、現在の日付、ユーザー コンテキスト、その他の関連するメタデータなどの変数である可能性があります。
- 推論時にこれらの変数をプロンプトに挿入すると、よりパーソナライズされた応答やコンテキストに応じた応答が可能になります。
-
チェーンオブソートを検討する
- 直接的な答えがすぐには得られない複雑なクエリの場合は、 CoT(Chain-of-Thought)プロンプトを検討してください。この迅速なエンジニアリング戦略は、複雑な問題をより単純で連続的なステップに分割し、LLMを論理的な推論プロセスを通じて導きます。
- モデルに「問題を段階的に考える」ように促すことで、より詳細で理にかなった応答を提供するように促し、マルチステップまたはオープンエンドのクエリを処理する場合に特に効果的です。
-
プロンプトはモデル間で転送できない場合があります
- プロンプトは、異なる言語モデル間でシームレスに転送されないことが多いことを認識してください。 各モデルには独自の特性があり、あるモデルでうまく機能するプロンプトが、別のモデルではそれほど効果的でない場合があります。
- エクスペリメントは、プロンプトの形式と長さが異なるため、オンラインガイド (OpenAI Cookbook や Anthropic Cookbook など) を参照し、モデルを切り替えるときにプロンプトを適応させて調整できるように準備してください。
LLM
RAGチェーンの生成コンポーネントは、前のステップの拡張プロンプトテンプレートを取得し、それをLLMに渡します。 RAGチェーンの生成コンポーネントにLLMを選択および最適化する場合は、LLM呼び出しを含む他の手順にも同様に適用できる次の要素を考慮してください。
-
さまざまな既製のモデルを用いた実験。
- 各モデルには、独自の特性、長所、短所があります。 一部のモデルは、特定のドメインをよりよく理解したり、特定のタスクでより優れたパフォーマンスを発揮したりする場合があります。
- 前述のように、モデルが異なれば同じプロンプトに対する応答も異なる可能性があるため、モデルの選択がプロンプトエンジニアリングプロセスにも影響を与える可能性があることに注意してください。
- 生成ステップに加えてクエリ理解の呼び出しなど、LLM を必要とするステップがチェーンに複数ある場合は、ステップごとに異なるモデルを使用することを検討してください。 より高価な汎用モデルは、ユーザークエリの意図を判断するなどのタスクには過剰かもしれません。
-
小規模から始めて、必要に応じてスケールアップします。
- GPT-4、Claudeなど、最もパワフルで高性能なモデルにすぐに手を伸ばしたくなるかもしれませんが、多くの場合、より小さく、より軽量なモデルから始める方が効率的です。
- 多くの場合、Llama 3 のような小規模なオープンソースの代替手段は、より低コストでより速い推論時間で満足のいく結果を提供できます。これらのモデルは、非常に複雑な推論や広範な世界知識を必要としないタスクに特に効果的です。
- RAGチェーンを開発および改良する際には、選択したモデルのパフォーマンスと制限を継続的に評価してください。 モデルが特定の種類のクエリで問題がある場合、または十分に詳細または正確な応答を提供できない場合は、より機能的なモデルにスケールアップすることを検討してください。
- モデルの変更がレスポンスの品質、レイテンシ、コストなどの主要なメトリクスに与える影響を監視して、特定のユースケースの要件に適したバランスを確保していることを確認します。
-
モデル パラメーターの最適化
- エクスペリメントをさまざまなパラメーター設定で使用して、応答の品質、多様性、一貫性の最適なバランスを見つけます。 たとえば、温度を調整すると、生成されるテキストのランダム性を制御でき、max_tokensで応答の長さを制限できます。
- 最適なパラメーター設定は、特定のタスク、プロンプト、および目的の出力スタイルによって異なる場合があることに注意してください。 生成された応答の評価に基づいて、これらの設定を繰り返しテストし、調整します。
-
タスク固有のファインチューニング
- パフォーマンスを洗練させる際には、クエリの理解など、RAGチェーン内の特定のサブタスクに対して、より小さなモデルをファインチューニングすることを検討します。
- RAGチェーンを使用して個々のタスクに特化したモデルをトレーニングすることで、すべてのタスクに単一の大きなモデルを使用する場合と比較して、全体的なパフォーマンスを向上させ、レイテンシを削減し、推論コストを削減できる可能性があります。
-
継続的な事前学習
- RAGアプリケーションが特殊なドメインを扱っている場合、または事前トレーニング済みLLMで十分に表現されていない知識が必要な場合は、ドメイン固有のデータに対して継続的事前トレーニング(CPT)を実行することを検討してください。
- 事前トレーニングを継続的に行うことで、ドメインに固有の特定の用語や概念に対するモデルの理解を向上させることができます。これにより、広範なプロンプトエンジニアリングや少数のショットの例の必要性を減らすことができます。
後処理とガードレール
LLM が応答を生成した後、多くの場合、出力が目的の形式、スタイル、およびコンテンツの要件を満たしていることを確認するために、後処理手法またはガードレールを適用する必要があります。 チェーンのこの最後のステップ(または複数のステップ)は、生成された応答全体の一貫性と品質を維持するのに役立ちます。 ポストプロセッシングとガードレールを実装する場合は、次の点を考慮してください。
-
出力形式の適用
- ユースケースによっては、生成されたレスポンスを特定の形式(構造化テンプレートや特定のファイルタイプ(JSON、HTML、Markdownなど)など)に準拠させる必要がある場合があります。
- 構造化された出力が必要な場合は、 Instructor や Outline などのライブラリが、この種の検証手順を実装するための適切な開始点を提供します。
- 開発の際は、必要な形式を維持しながら、生成された応答のバリエーションを処理できる柔軟性が後処理ステップにあることを確認するために時間をかけてください。
-
スタイルの一貫性の維持
- RAGアプリケーションに特定のスタイルガイドラインやトーン要件(フォーマルかカジュアルか、簡潔か詳細かなど)がある場合、後処理ステップでこれらのスタイル属性を生成されたレスポンス全体でチェックし、適用することができます。
-
コンテンツフィルタと安全ガードレール
- RAGアプリケーションの性質や、生成されたコンテンツに関連する潜在的なリスクによっては、不適切、攻撃的、または有害な情報の出力を防ぐために、 コンテンツフィルターや安全ガードレールを実装する ことが重要な場合があります。
- LlamaGuard のようなモデルや、APIOpenAIのモデレーションAPI など、コンテンツのモデレーションと安全性のために特別に設計された を使用して、安全ガードレールを実装することを検討してください。
-
幻覚の取り扱い
- 幻覚に対する防御は、後処理ステップとしても実装できます。 これには、生成された出力と取得したドキュメントとの相互参照、または追加のLLMを使用して応答の事実精度を検証することが含まれる場合があります。
- 生成されたレスポンスが事実精度の要件を満たしていない場合に対処するためのフォールバックメカニズムを開発します(代替レスポンスの生成やユーザーへの免責事項の提供など)。
-
エラー処理
- 後処理ステップでは、ステップで問題が発生した場合や満足のいく応答を生成できなかった場合に適切に対処するためのメカニズムを実装します。 これには、デフォルトの応答を生成するか、問題を人間のオペレーターにエスカレーションして手動レビューを依頼することが含まれる場合があります。