Compute configuration reference
This article explains all the configuration settings available in the Create Compute UI. Most users create compute using their assigned policies, which limits the configurable settings. If you don’t see a particular setting in your UI, it’s because the policy you’ve selected does not allow you to configure that setting.
The configurations and management tools described in this article apply to both all-purpose and job compute. For more considerations on configuring job compute, see Use Databricks compute with your jobs.
Create a new compute resource
To create a new all-purpose compute resource:
In the workspace sidebar, click Compute.
Click the Create compute button.
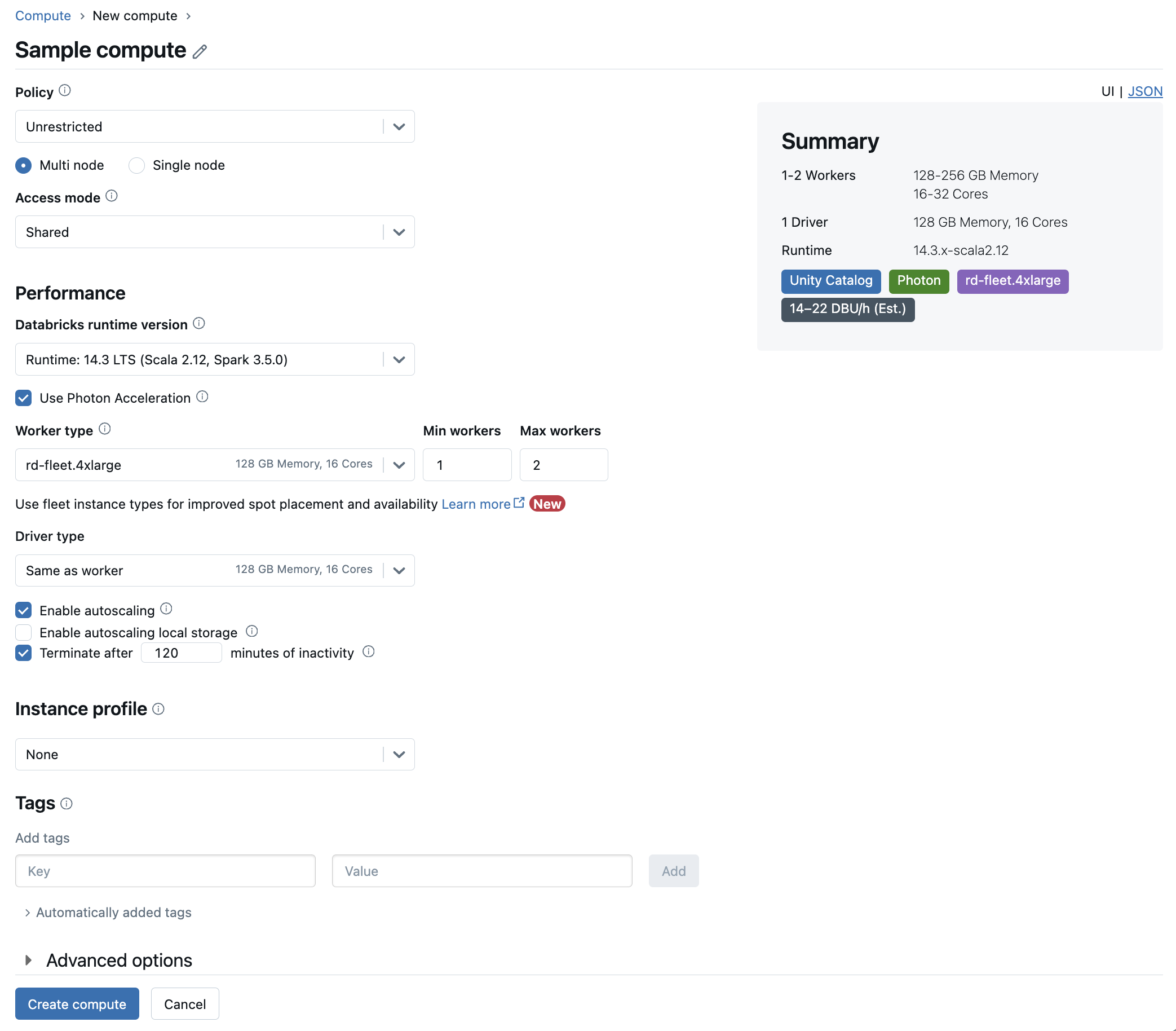
Configure the compute resource.
Click Create compute.
You new compute resource will automatically start spinning up and be ready to use shortly.
Policies
Policies are a set of rules used to limit the configuration options available to users when they create compute. If a user doesn’t have the Unrestricted cluster creation entitlement, then they can only create compute using their granted policies.
To create compute according to a policy, select a policy from the Policy drop-down menu.
By default, all users have access to the Personal Compute policy, allowing them to create single-machine compute resources. If you need access to Personal Compute or any additional policies, reach out to your workspace admin.
Single-node or multi-node compute
Depending on the policy, you can select between creating a Single node compute or a Multi node compute.
Single node compute is intended for jobs that use small amounts of data or non-distributed workloads such as single-node machine learning libraries. Multi-node compute should be used for larger jobs with distributed workloads.
Single node properties
A single node compute has the following properties:
Runs Spark locally.
Driver acts as both master and worker, with no worker nodes.
Spawns one executor thread per logical core in the compute, minus 1 core for the driver.
Saves all
stderr,stdout, andlog4jlog outputs in the driver log.Can’t be converted to a multi-node compute.
Selecting single or multi node
Consider your use case when deciding between a single or multi-node compute:
Large-scale data processing will exhaust the resources on a single node compute. For these workloads, Databricks recommends using a multi-node compute.
Single-node compute is not designed to be shared. To avoid resource conflicts, Databricks recommends using a multi-node compute when the compute must be shared.
A multi-node compute can’t be scaled to 0 workers. Use a single node compute instead.
Single-node compute is not compatible with process isolation.
GPU scheduling is not enabled on single node compute.
On single-node compute, Spark cannot read Parquet files with a UDT column. The following error message results:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.To work around this problem, disable the native Parquet reader:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Access modes
Access mode is a security feature that determines who can use the compute resource and the data they can access using the compute resource. Every compute resource in Databricks has an access mode.
Databricks recommends that you use shared access mode for all workloads. Use the single-user access mode only if your required functionality is not supported by shared access mode.
Access Mode |
Visible to user |
UC Support |
Supported Languages |
Notes |
|---|---|---|---|---|
Single user |
Always |
Yes |
Python, SQL, Scala, R |
Can be assigned to and used by a single user. Referred to as Assigned access mode in some workspaces. |
Shared |
Always (Premium plan or above required) |
Yes |
Python (on Databricks Runtime 11.3 LTS and above), SQL, Scala (on Unity Catalog-enabled compute using Databricks Runtime 13.3 LTS and above) |
Can be used by multiple users with data isolation among users. |
No Isolation Shared |
Admins can hide this access mode by enforcing user isolation in the admin settings page. |
No |
Python, SQL, Scala, R |
There is a related account-level setting for No Isolation Shared compute. |
Custom |
Hidden (For all new compute) |
No |
Python, SQL, Scala, R |
This option is shown only if you have existing compute without a specified access mode. |
You can upgrade an existing compute resource to meet the requirements of Unity Catalog by setting its access mode to Single User or Shared. For detailed information about the functionality that is supported by each of these access modes in Unity Catalog-enabled workspaces, see Compute access mode limitations for Unity Catalog.
Note
In Databricks Runtime 13.3 LTS and above, init scripts and libraries are supported by all access modes. Requirements and levels of support vary. See Where can init scripts be installed? and Cluster-scoped libraries.
Databricks Runtime versions
Databricks Runtime is the set of core components that run on your compute. Select the runtime using the Databricks Runtime Version drop-down menu. For details on specific Databricks Runtime versions, see Databricks Runtime release notes versions and compatibility. All versions include Apache Spark. Databricks recommends the following:
For all-purpose compute, use the most current version to ensure you have the latest optimizations and the most up-to-date compatibility between your code and preloaded packages.
For job compute running operational workloads, consider using the Long Term Support (LTS) Databricks Runtime version. Using the LTS version will ensure you don’t run into compatibility issues and can thoroughly test your workload before upgrading.
For data science and machine learning use cases, consider Databricks Runtime ML version.
Use Photon acceleration
Photon is enabled by default on compute running Databricks Runtime 9.1 LTS and above.
To enable or disable Photon acceleration, select the Use Photon Acceleration checkbox. To learn more about Photon, see What is Photon?.
Worker and driver node types
Compute consists of one driver node and zero or more worker nodes. You can pick separate cloud provider instance types for the driver and worker nodes, although by default the driver node uses the same instance type as the worker node. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads.
You can also select a pool to use as the worker or driver node. Only use a pool with spot instances as your worker type. Select a separate on-demand driver type to prevent your driver from being reclaimed. See What are Databricks pools?.
Worker type
In multi-node compute, worker nodes run the Spark executors and other services required for proper functioning compute. When you distribute your workload with Spark, all the distributed processing happens on worker nodes. Databricks runs one executor per worker node. Therefore, the terms executor and worker are used interchangeably in the context of the Databricks architecture.
Tip
To run a Spark job, you need at least one worker node. If the compute has zero workers, you can run non-Spark commands on the driver node, but Spark commands will fail.
Worker node IP addresses
Databricks launches worker nodes with two private IP addresses each. The node’s primary private IP address hosts Databricks internal traffic. The secondary private IP address is used by the Spark container for intra-cluster communication. This model allows Databricks to provide isolation between multiple compute in the same workspace.
Driver type
The driver node maintains state information of all notebooks attached to the compute. The driver node also maintains the SparkContext, interprets all the commands you run from a notebook or a library on the compute, and runs the Apache Spark master that coordinates with the Spark executors.
The default value of the driver node type is the same as the worker node type. You can choose a larger driver node type with more memory if you are planning to collect() a lot of data from Spark workers and analyze them in the notebook.
Tip
Since the driver node maintains all of the state information of the notebooks attached, make sure to detach unused notebooks from the driver node.
GPU instance types
For computationally challenging tasks that demand high performance, like those associated with deep learning, Databricks supports compute accelerated with graphics processing units (GPUs). For more information, see GPU-enabled compute.
Databricks no longer supports spinning up compute using Amazon EC2 P2 instances.
AWS Graviton instance types
Databricks compute supports AWS Graviton instances. These instances use AWS-designed Graviton processors that are built on top of the Arm64 instruction set architecture. AWS claims that instance types with these processors have the best price-to-performance ratio of any instance type on Amazon EC2. To use Graviton instance types, select one of the available AWS Graviton instance type for the Worker type, Driver type, or both.
Databricks supports AWS Graviton-enabled compute:
On Databricks Runtime 9.1 LTS and above for non-Photon, and Databricks Runtime 10.2 (unsupported) and above for Photon.
On Databricks Runtime 15.4 LTS for Machine Learning (Beta) for Databricks Runtime for Machine Learning.
In all AWS Regions. Note, however, that not all instance types are available in all Regions. If you select an instance type that is not available in the Region for a workspace, you get compute creation failure.
For AWS Graviton2 and Graviton3 processors.
Note
Delta Live Tables is not supported on Graviton-enabled compute.
ARM64 ISA limitations
Floating point precision changes: typical operations like adding, subtracting, multiplying, and dividing have no change in precision. For single triangle functions such as
sinandcos, the upper bound on the precision difference to Intel instances is1.11e-16.Third party support: the change in ISA may have some impact on support for third-party tools and libraries.
Mixed-instance compute: Databricks does not support mixing AWS Graviton and non-AWS Graviton instance types, as each type requires a different Databricks Runtime.
Graviton limitations
The following features do not support AWS Graviton instance types:
Python UDFs (Python UDFs are available on Databricks Runtime 15.2 and above)
Databricks Container Services
Delta Live Tables
Databricks SQL
Databricks on AWS GovCloud
Access to workspace files, including those in Git folders, from web terminals
AWS Fleet instance types
Note
If your workspace was created before May 2023, its IAM role’s permissions might need to be updated to allow access to fleet instance types. For more information, see Enable fleet instance types.
A fleet instance type is a variable instance type that automatically resolves to the best available instance type of the same size.
For example, if you select the fleet instance type m-fleet.xlarge, your node will resolve to whichever .xlarge, general purpose instance type has the best spot capacity and price at that moment. The instance type your compute resolves to will always have the same memory and number of cores as the fleet instance type you chose.
Fleet instance types use AWS’s Spot Placement Score API to choose the best and most likely to succeed availability zone for your compute at startup time.
Fleet limitations
The Max spot price setting under Advanced options has no effect when the worker node type is set to a fleet instance type. This is because there is no single on-demand instance to use as a reference point for the spot price.
Fleet instances do not support GPU instances.
A small percentage of older workspaces do not yet support fleet instance types. If this is the case for your workspace, you’ll see an error indicating this when attempting to create compute or an instance pool using a fleet instance type. We’re working to bring support to these remaining workspaces.
Enable autoscaling
When Enable autoscaling is checked, you can provide a minimum and maximum number of workers for the compute. Databricks then chooses the appropriate number of workers required to run your job.
To set the minimum and the maximum number of workers your compute will autoscale between, use the Min workers and Max workers fields next to the Worker type dropdown.
If you don’t enable autoscaling, you will enter a fixed number of workers in the Workers field next to the Worker type dropdown.
Note
When the compute is running, the compute details page displays the number of allocated workers. You can compare number of allocated workers with the worker configuration and make adjustments as needed.
Benefits of autoscaling
With autoscaling, Databricks dynamically reallocates workers to account for the characteristics of your job. Certain parts of your pipeline may be more computationally demanding than others, and Databricks automatically adds additional workers during these phases of your job (and removes them when they’re no longer needed).
Autoscaling makes it easier to achieve high utilization because you don’t need to provision the compute to match a workload. This applies especially to workloads whose requirements change over time (like exploring a dataset during the course of a day), but it can also apply to a one-time shorter workload whose provisioning requirements are unknown. Autoscaling thus offers two advantages:
Workloads can run faster compared to a constant-sized under-provisioned compute.
Autoscaling can reduce overall costs compared to a statically-sized compute.
Depending on the constant size of the compute and the workload, autoscaling gives you one or both of these benefits at the same time. The compute size can go below the minimum number of workers selected when the cloud provider terminates instances. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers.
Note
Autoscaling is not available for spark-submit jobs.
Note
Compute auto-scaling has limitations scaling down cluster size for Structured Streaming workloads. Databricks recommends using Delta Live Tables with Enhanced Autoscaling for streaming workloads. See Optimize the cluster utilization of Delta Live Tables pipelines with Enhanced Autoscaling.
How autoscaling behaves
Workspace on the Premium plan or above use optimized autoscaling. Workspaces on the standard pricing plan use standard autoscaling.
Optimized autoscaling has the following characteristics:
Scales up from min to max in 2 steps.
Can scale down, even if the compute is not idle, by looking at the shuffle file state.
Scales down based on a percentage of current nodes.
On job compute, scales down if the compute is underutilized over the last 40 seconds.
On all-purpose compute, scales down if the compute is underutilized over the last 150 seconds.
The
spark.databricks.aggressiveWindowDownSSpark configuration property specifies in seconds how often the compute makes down-scaling decisions. Increasing the value causes the compute to scale down more slowly. The maximum value is 600.
Standard autoscaling is used in standard plan workspaces. Standard autoscaling has the following characteristics:
Starts by adding 8 nodes. Then scales up exponentially, taking as many steps as required to reach the max.
Scales down when 90% of the nodes are not busy for 10 minutes and the compute has been idle for at least 30 seconds.
Scales down exponentially, starting with 1 node.
Autoscaling with pools
If you are attaching your compute to a pool, consider the following:
Make sure the compute size requested is less than or equal to the minimum number of idle instances in the pool. If it is larger, compute startup time will be equivalent to compute that doesn’t use a pool.
Make sure the maximum compute size is less than or equal to the maximum capacity of the pool. If it is larger, the compute creation will fail.
Autoscaling example
If you reconfigure a static compute to autoscale, Databricks immediately resizes the compute within the minimum and maximum bounds and then starts autoscaling. As an example, the following table demonstrates what happens to compute with a certain initial size if you reconfigure the compute to autoscale between 5 and 10 nodes.
Initial size |
Size after reconfiguration |
|---|---|
6 |
6 |
12 |
10 |
3 |
5 |
Enable autoscaling local storage
If you don’t want to allocate a fixed number of EBS volumes at compute creation time, use autoscaling local storage. With autoscaling local storage, Databricks monitors the amount of free disk space available on your compute’s Spark workers. If a worker begins to run too low on disk, Databricks automatically attaches a new EBS volume to the worker before it runs out of disk space. EBS volumes are attached up to a limit of 5 TB of total disk space per instance (including the instance’s local storage).
To configure autoscaling storage, select Enable autoscaling local storage.
The EBS volumes attached to an instance are detached only when the instance is returned to AWS. That is, EBS volumes are never detached from an instance as long as it is part of a running compute. To scale down EBS usage, Databricks recommends using this feature in compute configured with autoscaling compute or automatic termination.
Note
Databricks uses Throughput Optimized HDD (st1) to extend the local storage of an instance. The default AWS capacity limit for these volumes is 20 TiB. To avoid hitting this limit, administrators should request an increase in this limit based on their usage requirements.
Local disk encryption
Preview
This feature is in Public Preview.
Some instance types you use to run compute may have locally attached disks. Databricks may store shuffle data or ephemeral data on these locally attached disks. To ensure that all data at rest is encrypted for all storage types, including shuffle data that is stored temporarily on your compute’s local disks, you can enable local disk encryption.
Important
Your workloads may run more slowly because of the performance impact of reading and writing encrypted data to and from local volumes.
When local disk encryption is enabled, Databricks generates an encryption key locally that is unique to each compute node and is used to encrypt all data stored on local disks. The scope of the key is local to each compute node and is destroyed along with the compute node itself. During its lifetime, the key resides in memory for encryption and decryption and is stored encrypted on the disk.
To enable local disk encryption, you must use the Clusters API. During compute creation or edit, set enable_local_disk_encryption to true.
Automatic termination
You can set auto termination for compute. During compute creation, specify an inactivity period in minutes after which you want the compute to terminate.
If the difference between the current time and the last command run on the compute is more than the inactivity period specified, Databricks automatically terminates that compute. For more information on compute termination, see Terminate a compute.
Instance profiles
Note
Databricks recommends using Unity Catalog external locations to connect to S3 instead of instance profiles. Unity Catalog simplifies the security and governance of your data by providing a central place to administer and audit data access across multiple workspaces in your account. See Connect to cloud object storage using Unity Catalog.
To securely access AWS resources without using AWS keys, you can launch Databricks compute with instance profiles. See Tutorial: Configure S3 access with an instance profile for information about how to create and configure instance profiles. Once you have created an instance profile, you select it in the Instance Profile drop-down list.
After you launch your compute, verify that you can access the S3 bucket using the following command. If the command succeeds, that compute resource can access the S3 bucket.
dbutils.fs.ls("s3a://<s3-bucket-name>/")
Warning
Once a compute launches with an instance profile, anyone who has attach permissions to this compute can access the underlying resources controlled by this role. To guard against unwanted access, use Compute permissions to restrict permissions to the compute.
Tags
Tags allow you to easily monitor the cost of cloud resources used by various groups in your organization. Specify tags as key-value pairs when you create compute, and Databricks applies these tags to cloud resources like VMs and disk volumes, as well as DBU usage reports.
For compute launched from pools, the custom tags are only applied to DBU usage reports and do not propagate to cloud resources.
For detailed information about how pool and compute tag types work together, see Monitor usage using tags
To add tags to your compute:
In the Tags section, add a key-value pair for each custom tag.
Click Add.
AWS configurations
When you create compute, you can choose the availability zone, the max spot price, and EBS volume type. These settings are under the Advanced Options toggle in the Instances tab.
Availability zones
This setting lets you specify which availability zone (AZ) you want the compute to use. By default, this setting is set to auto, where the availability zone is automatically selected. If auto-AZ selects a zone with insufficient capacity, it retries in another availability zone.
Note
Auto-AZ works only at compute startup. After the compute launches, all the nodes stay in the original availability zone until the compute is terminated or restarted.
Choosing a specific AZ for the compute is useful primarily if your organization has purchased reserved instances in specific availability zones. Read more about AWS availability zones.
Spot instances
You can specify whether to use spot instances and the max spot price to use when launching spot instances as a percentage of the corresponding on-demand price. By default, the max price is 100% of the on-demand price. See AWS spot pricing.
EBS volumes
This section describes the default EBS volume settings for worker nodes, how to add shuffle volumes, and how to configure compute so that Databricks automatically allocates EBS volumes.
To configure EBS volumes, your compute must not be enabled for autoscaling local storage. Click the Instances tab in the compute configuration and select an option in the EBS Volume Type dropdown list.
Default EBS volumes
Databricks provisions EBS volumes for every worker node as follows:
A 30 GB encrypted EBS instance root volume used by the host operating system and Databricks internal services.
A 150 GB encrypted EBS container root volume used by the Spark worker. This hosts Spark services and logs.
(HIPAA only) a 75 GB encrypted EBS worker log volume that stores logs for Databricks internal services.
Add EBS shuffle volumes
To add shuffle volumes, select General Purpose SSD in the EBS Volume Type dropdown list.
By default, Spark shuffle outputs go to the instance local disk. For instance types that do not have a local disk, or if you want to increase your Spark shuffle storage space, you can specify additional EBS volumes. This is particularly useful to prevent out-of-disk space errors when you run Spark jobs that produce large shuffle outputs.
Databricks encrypts these EBS volumes for both on-demand and spot instances. Read more about AWS EBS volumes.
Optionally encrypt Databricks EBS volumes with a customer-managed key
Optionally, you can encrypt compute EBS volumes with a customer-managed key.
AWS EBS limits
Ensure that your AWS EBS limits are high enough to satisfy the runtime requirements for all workers in all your deployed compute. For information on the default EBS limits and how to change them, see Amazon Elastic Block Store (EBS) Limits.
AWS EBS SSD volume type
Select either gp2 or gp3 for your AWS EBS SSD volume type. To do this, see Manage SSD storage. Databricks recommends you switch to gp3 for its cost savings compared to gp2.
Note
By default, the Databricks configuration sets the gp3 volume’s IOPS and throughput IOPS to match the maximum performance of a gp2 volume with the same volume size.
For technical information about gp2 and gp3, see Amazon EBS volume types.
Spark configuration
To fine-tune Spark jobs, you can provide custom Spark configuration properties.
On the compute configuration page, click the Advanced Options toggle.
Click the Spark tab.
In Spark config, enter the configuration properties as one key-value pair per line.
When you configure compute using the Clusters API, set Spark properties in the spark_conf field in the create cluster API or Update cluster API.
To enforce Spark configurations on compute, workspace admins can use compute policies.
Retrieve a Spark configuration property from a secret
Databricks recommends storing sensitive information, such as passwords, in a secret instead of plaintext. To reference a secret in the Spark configuration, use the following syntax:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
For example, to set a Spark configuration property called password to the value of the secret stored in secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
For more information, see Syntax for referencing secrets in a Spark configuration property or environment variable.
Environment variables
Configure custom environment variables that you can access from init scripts running on the compute. Databricks also provides predefined environment variables that you can use in init scripts. You cannot override these predefined environment variables.
On the compute configuration page, click the Advanced Options toggle.
Click the Spark tab.
Set the environment variables in the Environment Variables field.
You can also set environment variables using the spark_env_vars field in the Create cluster API or Update cluster API.
Compute log delivery
When you create compute, you can specify a location to deliver the logs for the Spark driver node, worker nodes, and events. Logs are delivered every five minutes and archived hourly in your chosen destination. When a compute is terminated, Databricks guarantees to deliver all logs generated up until the compute was terminated.
The destination of the logs depends on the compute’s cluster_id. If the specified destination is
dbfs:/cluster-log-delivery, compute logs for 0630-191345-leap375 are delivered to
dbfs:/cluster-log-delivery/0630-191345-leap375.
To configure the log delivery location:
On the compute page, click the Advanced Options toggle.
Click the Logging tab.
Select a destination type.
Enter the compute log path.
S3 bucket destinations
If you choose an S3 destination, you must configure the compute with an instance profile that can access the bucket.
This instance profile must have both the PutObject and PutObjectAcl permissions. An example instance profile
has been included for your convenience. See Tutorial: Configure S3 access with an instance profile for instructions on how to set up an instance profile.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>/*"
]
}
]
}
Note
This feature is also available in the REST API. See the Clusters API.