Collect feedback and expectations by labeling existing traces
One of the most effective ways to improve your GenAI application is to have domain experts review and label existing traces. MLflow's Review App provides a structured process for collecting this expert feedback on real interactions with your application.

When to label existing traces
Ask experts to review existing interactions with your app to provide feedback and expectations.
Use the Review App to:
- Understand what high-quality, correct responses look like for specific queries
- Collect input to align LLM judges with your business requirements
- Create evaluation datasets from production traces
Identify traces for expert review
Before creating a labeling session, identify traces that would benefit from expert review. Focus on cases requiring human judgment:
- Traces with ambiguous or borderline quality
- Edge cases not covered by automated judges
- Examples where automated metrics disagree with expected quality
- Representative samples of different user interaction patterns
You can filter traces in the MLflow UI by status, tags, or time range. For programmatic selection with advanced filters, see Query traces via SDK.
Prerequisites
-
You must install MLflow and its required packages. The features described in this guide require MLflow version 3.1.0 or above. Run the following command to install or upgrade the MLflow SDK, including extras needed for Databricks integration:
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
Your development environment must be connected to the MLflow Experiment where your GenAI application traces are logged.
- Follow Tutorial: Connect your development environment to MLflow to connect your development environment.
-
Domain experts must have the following permissions to use the Review App to label existing traces:
-
Account access: Must be provisioned in your Databricks account, but do not need access to your workspace.
For users without workspace access, account admins can:
- Use account-level SCIM provisioning to sync users from your identity provider
- Manually register users and groups in Databricks
See User and group management for details.
-
Experiment access:
CAN_EDITpermission to the MLflow experiment.
-
Step 1: Create an app with tracing
Before you can collect feedback, you must have traces logged from your GenAI application. These traces capture the inputs, outputs, and intermediate steps of your application's execution, including any tool calls or retriever actions.
Below is an example of how you might log traces. This example includes a fake retriever so we can illustrate how the retrieved documents in the traces are rendered in the Review App. See Review App content rendering for more information about how Review App renders traces.
-
Initialize an OpenAI client to connect to either Databricks-hosted LLMs or LLMs hosted by OpenAI.
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
Use
databricks-openaito get an OpenAI client that connects to Databricks-hosted LLMs. Select a model from the available foundation models.Pythonimport mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"Use the native OpenAI SDK to connect to OpenAI-hosted models. Select a model from the available OpenAI models.
Pythonimport mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini" -
Define your application:
Pythonfrom mlflow.entities import Document
from typing import List, Dict
# Spans of type RETRIEVER are rendered in the Review App as documents.
@mlflow.trace(span_type="RETRIEVER")
def retrieve_docs(query: str) -> List[Document]:
normalized_query = query.lower()
if "john doe" in normalized_query:
return [
Document(
id="conversation_123",
page_content="John Doe mentioned issues with login on July 10th. Expressed interest in feature X.",
metadata={"doc_uri": "http://domain.com/conversations/123"},
),
Document(
id="conversation_124",
page_content="Follow-up call with John Doe on July 12th. Login issue resolved. Discussed pricing for feature X.",
metadata={"doc_uri": "http://domain.com/conversations/124"},
),
]
else:
return [
Document(
id="ticket_987",
page_content="Acme Corp raised a critical P0 bug regarding their main dashboard on July 15th.",
metadata={"doc_uri": "http://domain.com/tickets/987"},
)
]
# Sample app to review traces from
@mlflow.trace
def my_app(messages: List[Dict[str, str]]):
# 1. Retrieve conversations based on the last user message
last_user_message_content = messages[-1]["content"]
retrieved_documents = retrieve_docs(query=last_user_message_content)
retrieved_docs_text = "\n".join([doc.page_content for doc in retrieved_documents])
# 2. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant!"},
{
"role": "user",
"content": f"Additional retrieved context:\n{retrieved_docs_text}\n\nNow, please provide the one-paragraph summary based on the user's request {last_user_message_content} and this retrieved context.",
},
]
# 3. Call LLM to generate the summary
return client.chat.completions.create(
model=model_name, # This example uses :re[DB] hosted claude-sonnet-4-5. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
Step 2: Define labeling schemas
Labeling schemas define the questions and input types that domain experts will use to provide feedback on your traces. You can use MLflow's built-in schemas or create custom ones tailored to your specific evaluation criteria.
There are two main types of labeling schemas:
- Expectation Type (
type="expectation"): Used when the expert provides a "ground truth" or a correct answer. For example, providing theexpected_factsfor a RAG system's response. These labels can often be directly used in evaluation datasets. - Feedback Type (
type="feedback"): Used for subjective assessments, ratings, or classifications. For example, rating a response on a scale of 1-5 for politeness, or classifying if a response met certain criteria.
See Create and manage labeling schemas to understand the various input methods for your schemas, such as categorical choices, numeric scales, or free-form text.
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
# Collect feedback on the summary
summary_quality = create_label_schema(
name="summary_quality",
type="feedback",
title="Is this summary concise and helpful?",
input=InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True,
overwrite=True,
)
# Collect a ground truth summary
expected_summary = create_label_schema(
name="expected_summary",
type="expectation",
title="Please provide the correct summary for the user's request.",
input=InputText(),
overwrite=True,
)
Step 3: Create a labeling session
A labeling session is a special type of MLflow Run that organizes a set of traces for review by specific experts using selected labeling schemas. It acts as a queue for the review process.
See Create and manage labeling sessions for more details.
Here's how to create a labeling session:
from mlflow.genai.labeling import create_labeling_session
# Create the labeling session with the schemas we created in the previous step
label_summaries = create_labeling_session(
name="label_summaries",
assigned_users=[],
label_schemas=[summary_quality.name, expected_summary.name],
)
Step 4: Generate traces and add to the labeling session
After your labeling session is created, you must add traces to it. Traces are copied into the labeling session, so any labels or modifications made during the review process don't affect your original logged traces.
You can add any trace in your MLflow Experiment. See Create and manage labeling sessions for more details.
After the traces are generated, you can also add them to the labeling session by selecting the traces in the Trace tab, clicking Export Traces, and then selecting the labeling session you created earlier.
import mlflow
# Use version tracking to be able to easily query for the traces
tracked_model = mlflow.set_active_model(name="my_app")
# Run the app to generate traces
sample_messages_1 = [
{"role": "user", "content": "what issues does john doe have?"},
]
summary1_output = my_app(sample_messages_1)
sample_messages_2 = [
{"role": "user", "content": "what issues does acme corp have?"},
]
summary2_output = my_app(sample_messages_2)
# Query for the traces we just generated
traces = mlflow.search_traces(model_id=tracked_model.model_id)
# Add the traces to the session
label_summaries.add_traces(traces)
# Print the URL to share with your domain experts
print(f"Share this Review App with your team: {label_summaries.url}")
Step 5: Share the Review App with experts
After your labeling session is populated with traces, you can share its URL with your domain experts. They can use this URL to access the Review App, view the traces assigned to them (or select from unassigned ones), and provide feedback using the labeling schemas you configured.
Your domain experts must be provisioned in your Databricks account and have CAN_EDIT permission on the MLflow experiment. They do not need access to your Databricks workspace. See the Prerequisites section for details on how to set up account-level access.

Customize the Review App UI (optional)
For use cases that require custom trace visualization, tailored labeling interfaces, or specific workflows, deploy a customizable Review App template. This open-source template uses the same MLflow backend APIs and data model (labeling sessions, schemas, and assessments) while giving you full control over the frontend experience. Customization options include:
- Specialized trace renderers for your agent types
- Custom labeling interface layouts and interactions
- Domain-specific visualizations
- Control what trace information is displayed to reviewers
The template repository includes command-line tools for programmatic setup or an AI assistant (Claude Code) for interactive customization: GitHub - custom-mlflow-review-app. The customized Review App deploys as a Databricks App and integrates directly with your existing MLflow experiments and labeling sessions. See the template repository documentation for complete customization and deployment instructions.
The customizable template is ideal for teams that need custom trace visualization, evaluation workflows, or specific UI requirements beyond the standard Review App interface. For standard evaluation workflows, the built-in Review App provides a production-ready solution without additional setup.
Step 6: View and use collected labels
After your domain experts have completed their reviews, the collected feedback is attached to the traces within the labeling session. You can retrieve these labels programmatically to analyze them or use them to create evaluation datasets.
Labels are stored as Assessment objects on each Trace within the labeling session.
Use the MLflow UI
To review the results, go to the MLflow experiment.

Use the MLflow SDK
The following code fetches all traces from the labeling session's run and extracts the assessments (labels) into a pandas DataFrame for easier analysis.
labeled_traces_df = mlflow.search_traces(run_id=label_summaries.mlflow_run_id)
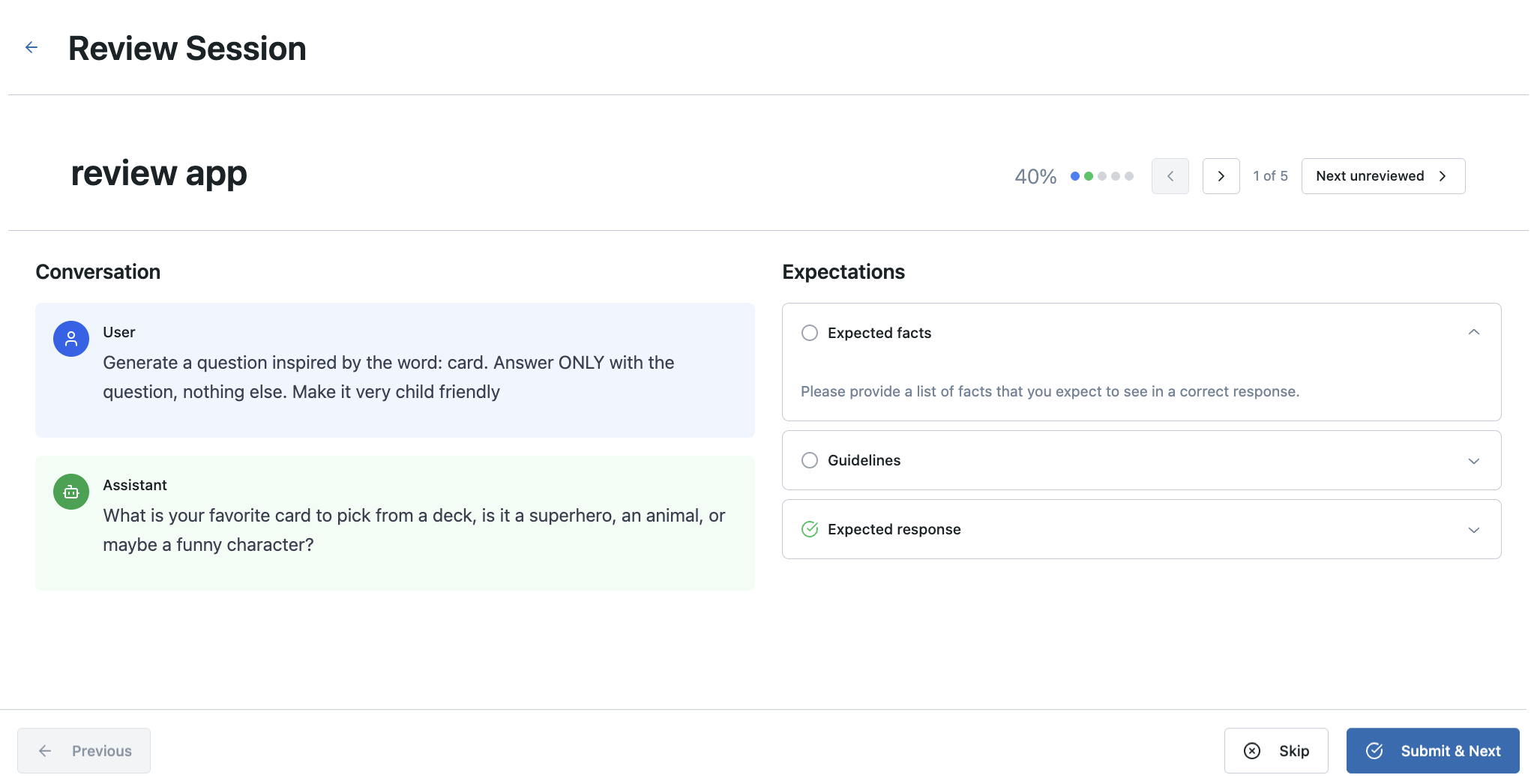
Review App content rendering
When labeling existing traces, the Review App uses the inputs and outputs from existing traces and stores results in MLflow Traces inside a labeling session. You must provide a custom labeling schema to define the questions and criteria for your use case.
The Review App automatically renders different content types from your MLflow Trace:
- Retrieved documents: Documents within a
RETRIEVERspan are rendered for display - OpenAI format messages: Inputs and outputs of the MLflow Trace following OpenAI chat conversations are rendered:
outputsthat contain an OpenAI format ChatCompletions objectinputsoroutputsdicts that contain amessageskey with an array of OpenAI format chat messages- If the
messagesarray contains OpenAI format tool calls, tool calls are also rendered
- If the
- Dictionaries: Inputs and outputs of the MLflow Trace that are dicts are rendered as pretty-printed JSONs
Otherwise, the content of the input and output from the root span of each trace are used as the primary content for review.
Example notebook
The following notebook includes all of the code on this page.
Collect domain expert feedback notebook
Next steps
Converting to evaluation datasets
Labels of "expectation" type (such as expected_summary from our example) are particularly useful for creating Evaluation Datasets. These datasets can then be used with mlflow.genai.evaluate() to systematically test new versions of your GenAI application against expert-defined ground truth.