SQL Server インジェストのトラブルシューティング
このページでは、Databricks Lakeflow Connect の Microsoft SQL Server コネクタに関する一般的な問題とその解決方法について説明します。
一般的なパイプラインのトラブルシューティング
このセクションのトラブルシューティング手順は、 Lakeflowコネクトのすべてのインジェスト パイプラインに適用されます。
実行中にパイプラインが失敗した場合は、失敗したステップをクリックし、エラー メッセージにエラーの性質に関する十分な情報が含まれているかどうかを確認します。
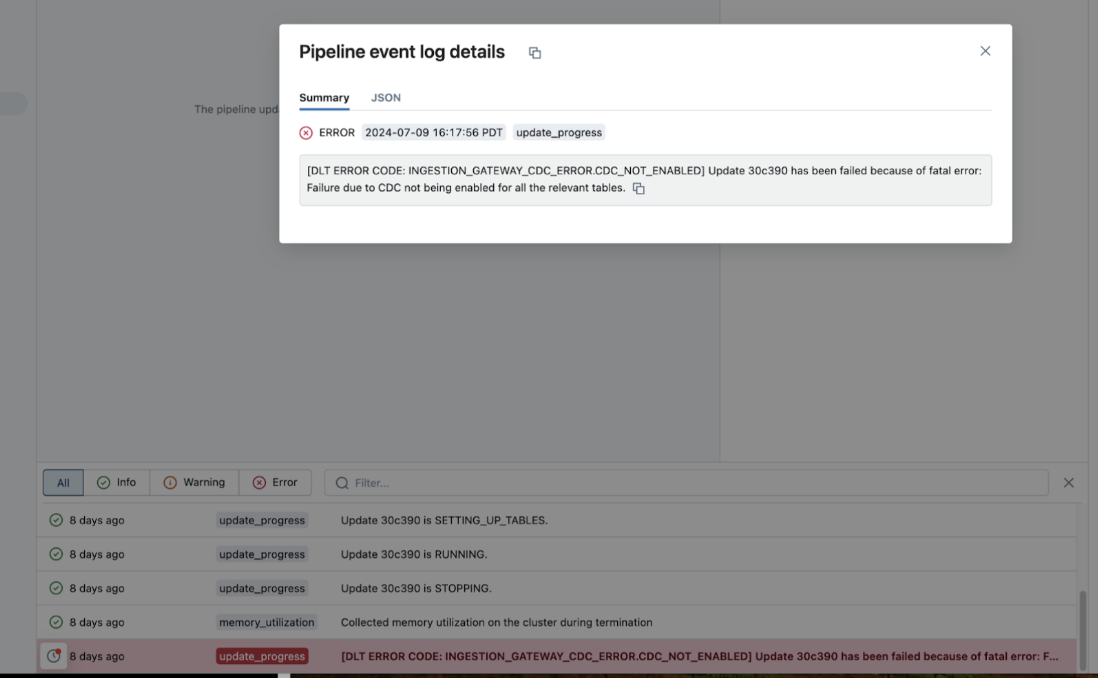
また、右側のパネルで [Update details] をクリックし、[Logs] をクリックして、パイプラインの詳細ページからクラスター ログを確認してダウンロードすることもできます。 ログをスキャンしてエラーまたは例外を探します。
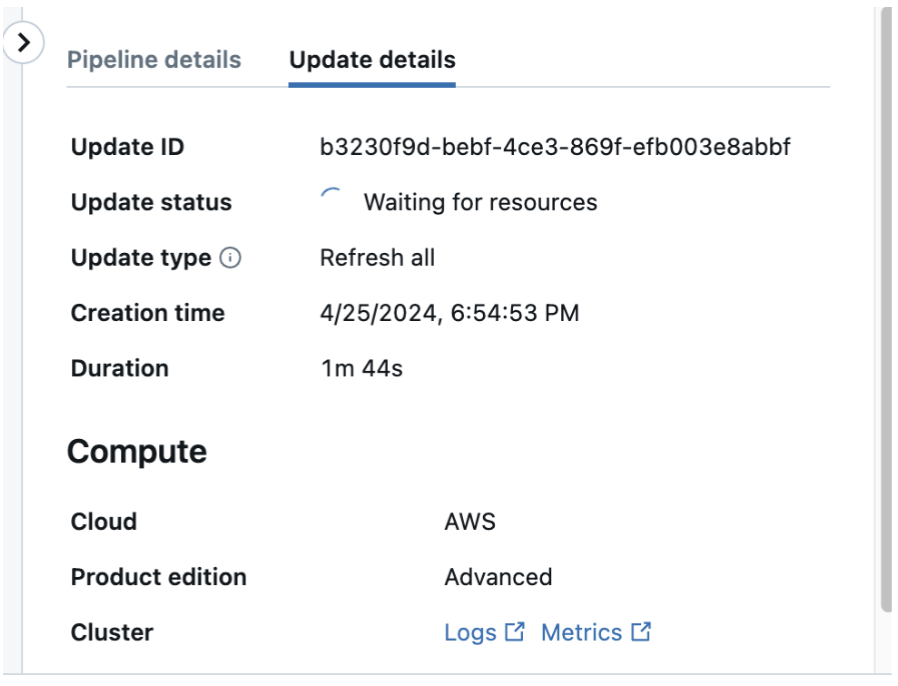
CDC がデータベースまたはテーブルで有効になっているかどうかを確認する
CDC がデータベース <database-name>に対して有効になっているかどうかを確認するには:
select is_cdc_enabled from sys.databases where name='<database-name>';
CDC がテーブル <schema-name>.<table-name>で有効になっているかどうかを確認するには:
select t.is_tracked_by_cdc
from sys.tables t join sys.schemas s on t.schema_id = s.schema_id
where s.name='<schema-name>' and t.name='<table-name>';
変更追跡がデータベースまたはテーブルに対して有効になっているかどうかを確認する
データベース\<database-name\>の変更追跡が有効になっているかどうかを確認するには:
select ctdb.*
from sys.change_tracking_databases ctdb join sys.databases db
on db.database_id = ctdb.database_id
where db.name = '<MyDatabaseName>'
テーブル <schema-name>.<table-name>の変更追跡が有効になっているかどうかを確認するには:
select s.name schema_name, t.name table_name, ct.*
from sys.change_tracking_tables ct join sys.tables t
on ct.object_id = t.object_id
join sys.schemas s on t.schema_id = s.schema_id
where s.name = '<MySchemaName>' and t.name = '<MyTableName>'
テーブルトークンの待機中にタイムアウト
インジェスト パイプラインは、ゲートウェイから情報が提供されるのを待っている間にタイムアウトする場合があります。これは、次の理由が考えられます。
- 古いバージョンのゲートウェイを実行しています。
- 必要な情報の生成中にエラーが発生しました。ゲートウェイ ドライバーのログでエラーを確認します。
完全更新フローにより、完全更新操作中のタイムアウト エラーの発生が大幅に削減されます。 「完全更新動作 (CDC)」を参照してください。
デフォルトの認証: デフォルトの認証情報を設定できません
このエラーが表示された場合は、現在のユーザー資格情報の検出に問題があります。次のものを置き換えてみてください。
w = WorkspaceClient()
で:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
Databricks SDK for Python ドキュメントの 認証 を参照してください。
tech.replicant.common.ExtractorException:com.microsoft.sqlserver.JDBC.SQLServerException:無効な列名「SERIAL_NUMBER」。
このエラーは、古いバージョンの内部テーブルを使用している場合に表示されることがあります。接続されたデータベースで次のコマンドを実行します。
drop table dbo.replicate_io_audit_ddl_trigger_1;
PERMISSION_DENIED: You are not authorized to create clusters. Please contact your administrator.
Databricks アカウント管理者に連絡して、 Unrestricted cluster creation アクセス許可を付与してください。
DLT ERROR CODE: INGESTION_GATEWAY_INTERNAL_ERROR
ドライバー ログの stdout ファイルを確認します。
ソース テーブルの名前の競合
Ingestion pipeline error: “org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `XYZ_snapshot_load` for `XYZ`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
これは、同じインジェスト パイプラインによって同じ宛先スキーマに取り込まれている、異なるソース スキーマ内の XYZ という名前の複数のソース テーブルが原因で名前の競合が発生していることを示しています。
複数のゲートウェイとパイプラインのペアを作成し、これらの競合するテーブルを異なる送信先スキーマに書き込みます。
Incompatible schema changes
互換性のないスキーマの変更により、インジェスト パイプラインは INCOMPATIBLE_SCHEMA_CHANGE エラーで失敗します。レプリケーションを続行するには、影響を受けるテーブルの完全更新をトリガーします。
Databricks では、互換性のないスキーマ変更のためにインジェスト パイプラインが失敗した時点で、スキーマ変更前のすべての行が取り込まれていることを保証できません。