本番運用トラフィックでエージェントの品質を監視する方法
プレビュー
この機能は パブリック プレビュー段階です。
この記事では、機能が制限された古い製品について説明します。Databricks 、本番運用では代わりに Monitor GenAIを使用することをお勧めします。
この記事では、 Mosaic AI Agent Evaluation を使用して、本番運用トラフィックにデプロイされたエージェントの品質を監視する方法について説明します。
オンラインモニタリングは、エージェントが実際のリクエストに対して意図したとおりに機能していることを確認するための重要な側面です。 以下に示すノートブックを使用すると、エージェント サービス エンドポイントを介して配信された要求に対して Agent Evaluation を継続的に実行できます。ノートブックは、 質の高いメトリクス と、本番運用リクエストに対するエージェントの出力に対するユーザーフィードバック(サムズアップ👍またはサムズダウン👎)を表示するダッシュボードを生成します。 このフィードバックは、関係者から のレビューアプリ を通じて、またはエンドユーザーの反応をキャプチャできる本番運用エンドポイントの フィードバック API を通じて提供されます。 ダッシュボードでは、時間、ユーザーフィードバック、合格/不合格ステータス、入力リクエストのトピックなど、さまざまなディメンションでメトリクスをスライスできます (たとえば、特定のトピックが低品質の出力と相関しているかどうかを理解するため)。さらに、低品質の応答を含む個々の要求を深く掘り下げて、さらにデバッグすることもできます。ダッシュボードなどのすべてのアーティファクトは、完全にカスタマイズ可能です。

必要条件
- :パートナーが提供する AI 機能をワークスペースで有効にする必要があります。
- 推論テーブル は、エージェントにサービスを提供するエンドポイントで有効にする必要があります。
Agent Evaluationによる本番運用トラフィックの継続的な処理
次のノートブックの例は、エージェント サービス エンドポイントからのリクエスト ログに対して Agent Evaluation を実行する方法を示しています。 ノートブックを実行するには、次の手順を実行します。
-
ノートブックをワークスペースにインポートします (手順)。 下の「インポート用のリンクをコピー」ボタンをクリックして、インポート用のURLを取得できます。
-
インポートしたノートブックの上部に必要なパラメーターを入力します。
- デプロイされたエージェントの配信エンドポイントの名前。
- 0.0 から 1.0 のサンプル レートからサンプル要求まで。 トラフィック量の多いエンドポイントには、より低いレートを使用します。
- (オプション)生成されたアーティファクト (ダッシュボードなど) を格納するワークスペース フォルダー。 デフォルトはホームフォルダーです。
- (オプション)入力要求を分類するトピックの一覧。 デフォルトは、1 つのキャッチオールトピックで構成されるリストです。
-
インポートしたノートブックで [ すべて実行 ] をクリックします。 これにより、30日以内に本番運用ログの初期処理が行われ、品質メトリクスをまとめたダッシュボードが初期化されます。
-
[ スケジュール ] をクリックして、ノートブックを定期的に実行するジョブを作成します。 ジョブは、本番運用ログを段階的に処理し、ダッシュボードを最新の状態に保ちます。
ノートブックには、サーバレス コンピュート、または 15.2 以降を実行しているクラスター Databricks Runtime が必要です。 リクエスト数の多いエンドポイントで本番運用トラフィックを継続的にモニタリングする場合は、より頻繁なスケジュールを設定することをお勧めします。 たとえば、時間単位のスケジュールは、1時間あたり10,000件を超えるリクエストと10%のサンプルレートを持つエンドポイントに適しています。
本番運用トラフィックに対するAgent Evaluation実行 ノートブック
エージェントの応答にガイドラインを適用する
ガイドライン準拠ジャッジは、モデルの出力が指定されたガイドラインに準拠していることを確認します。これらのグローバル ガイドラインは、上記のノートブックに示すように、または次のように記述できます。
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}
}
)
このジャッジの結果は、サンプル ノートブック (ノートブックのeval_requests_log_table_name ) によって生成された評価された要求ログ テーブルに入力され、ダッシュボードをカスタマイズしてジャッジの結果を経時的に表示できます。
評価メトリクスに対するアラートの作成
ノートブックを定期的に実行するようにスケジュールした後、品質メトリクスが予想よりも低下したときに通知を受け取るアラートを追加できます。 これらのアラートは、他の Databricks SQL アラートと同じ方法で作成および使用されます。 まず、サンプル ノートブックによって生成された評価要求ログ テーブルに対して Databricks SQL クエリ を作成します。 次のコードは、評価要求テーブルに対するクエリの例を示し、過去 1 時間からの要求をフィルター処理しています。
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
次に、 Databricks SQL アラート を作成して、目的の頻度でクエリを評価し、アラートがトリガーされた場合は通知を送信します。 次の図は、全体の合格率が 80% を下回ったときにアラートを送信する設定例を示しています。
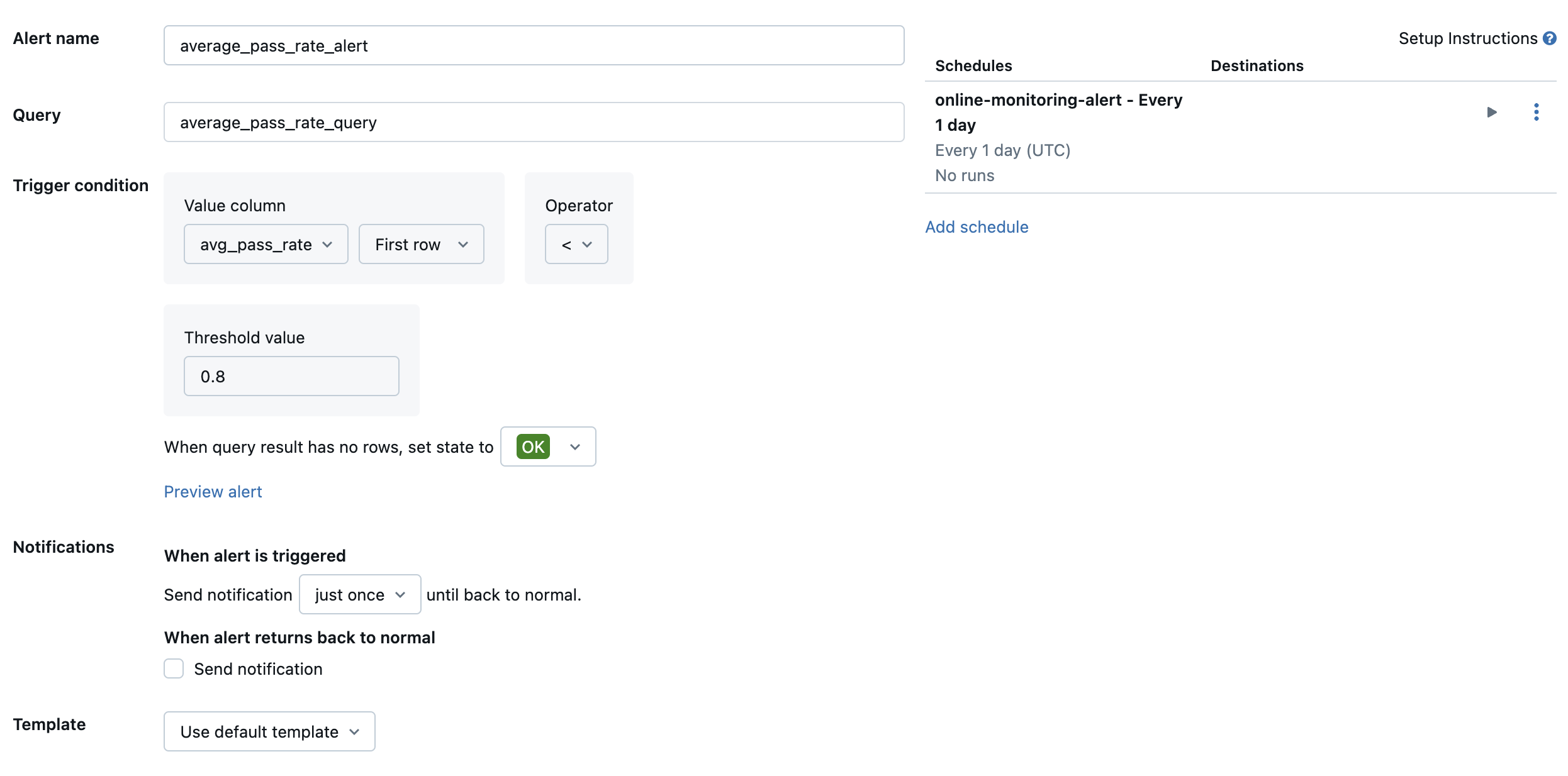
デフォルトでは、Eメールの通知が送信されます。 また、Webhook を設定したり、Slack や PagerDuty などの他のアプリケーションに通知を送信したりすることもできます。
選択した本番運用ログをレビューアプリに追加し、人間がレビューできるようにします
ユーザーからリクエストに対するフィードバックが寄せられたら、否定的なフィードバック (レスポンスや検索に親指を下げたリクエスト) があるリクエストを、対象分野の専門家にレビューしてもらうことができます。 これを行うには、 レビューアプリに 特定のログを追加して、専門家によるレビューをリクエストします。
次のコードは、評価ログ テーブルに対するクエリの例を示しており、要求 ID とソース ID ごとに最新の人間による評価を取得します。
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
次のコードでは、行 human_ratings_query = "..." の ... を上記のようなクエリに置き換えます。次に、次のコードは、否定的なフィードバックを含む要求を抽出し、レビュー アプリに追加します。
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
レビュー アプリの詳細については、「 生成AI アプリの人間によるレビューにレビュー アプリを使用する (MLflow 2)」を参照してください。