モデルのモニタリングとデバッグのための推論テーブル
このドキュメントは廃止されており、更新されない可能性があります。 このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。
Databricksは、カスタムモデル、基盤モデル、およびエージェントサービスエンドポイントで利用できるため、 AI Gateway対応の推論テーブルを推奨しています。AI Gateway対応推論テーブルへの移行手順については、「AI Gateway推論テーブルへの移行」を参照してください。
この記事では、サービングされるモデルを監視するための推論テーブルについて説明します。 次の図は、推論テーブルを使用した一般的なワークフローを示しています。 推論テーブルは、モデルサービング エンドポイントの受信要求と送信応答を自動的にキャプチャし、それらを Unity Catalog Delta テーブルとしてログに記録します。 この表のデータを使用して、ML モデルをモニタリング、デバッグ、改善できます。
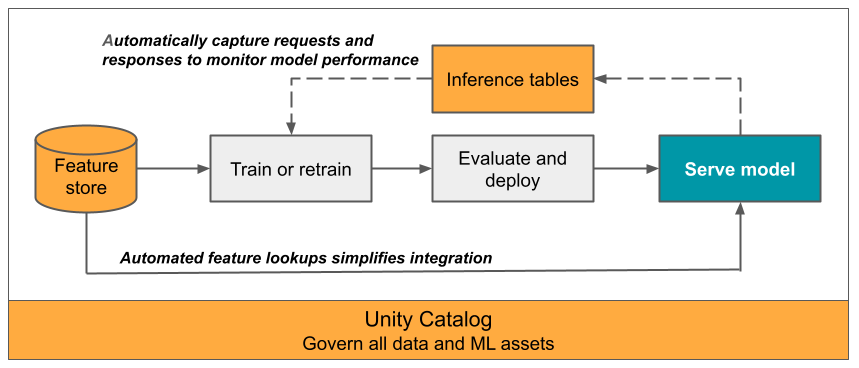
推論テーブルとは何ですか?
本番運用ワークフローでのモデルのパフォーマンスのモニタリングは、 AIおよびMLモデルのライフサイクルの重要な側面です。 推論テーブルは、モデルサービング エンドポイントからのサービング リクエストの入力と応答 (予測) を継続的にログに記録し、それらをUnity CatalogのDeltaテーブルに保存することにより、モデルのモニタリングと診断を簡素化します。 その後、Databricks SQLクエリ、ノートブック、データプロファイリングなど、Databricksプラットフォームのすべての機能を使用して、モデルの監視、デバッグ、最適化を行うことができます。
既存または新規に作成されたモデルサーのエンドポイントで推論テーブルを有効にすると、そのエンドポイントへのリクエストは自動的にUCのテーブルにログ記録されます。
推論テーブルの一般的な用途には、以下のようなものがあります。
- データとモデルの品質を監視する。データプロファイリングを使用することで、モデルのパフォーマンスとデータドリフトを継続的に監視できます。データプロファイリングは、関係者と共有できるデータおよびモデル品質ダッシュボードを自動的に生成します。さらに、受信データの変化やモデルのパフォーマンス低下に基づいて、モデルの再トレーニングが必要な時期を知らせるアラートを有効にすることもできます。
- 本番運用の問題をデバッグします。 推論テーブルは、HTTPステータスコード、モデル実行時間、リクエストおよびレスポンスのJSONコードなどのデータをログに記録します。このパフォーマンスデータはデバッグ目的で使用できます。推論テーブルの履歴データを使用して、過去のリクエストに対するモデルのパフォーマンスを比較することもできます。
- トレーニング コーパスを作成します。推論テーブルをグラウンド トゥルース ラベルと結合することで、モデルの再トレーニングや微調整、改善に使用できるトレーニング コーパスを作成できます。Lakeflowジョブを使用すると、継続的なフィードバックループを設定し、再トレーニングを自動化できます。
要件
- ワークスペースはUnity Catalogが有効になっていなければなりません。
- エンドポイントの作成者と変更者の両方が、エンドポイントに対する 「管理可能 」権限を持っている必要があります。アクセス制御リストを参照してください。
- エンドポイントの作成者と変更者は、Unity Catalogで以下の権限を持っている必要があります。
USE CATALOG指定されたカタログに対する権限。USE SCHEMA指定されたスキーマに対する権限。CREATE TABLEスキーマ内の権限。
推論テーブルの有効化と無効化
このセクションでは、Databricksのユーザーインターフェースを使用して推論テーブルを有効または無効にする方法を説明します。APIを使用することもできます。手順については、「 APIを使用してモデルサービング エンドポイントで推論テーブルを有効にする」を参照してください。
推論テーブルの所有者は、エンドポイントを作成したユーザーです。テーブル上のすべてのアクセス制御リスト(ACL)は、標準のUnity Catalog権限に従い、テーブルの所有者によって変更できます。
推論テーブルは、以下のいずれかの操作を行った場合に破損する可能性があります。
- テーブルスキーマを変更します。
- テーブル名を変更します。
- テーブルを削除します。
- Unity Catalogカタログまたはスキーマに対する権限を失います。
この場合、エンドポイントステータスのauto_capture_configは、ペイロードテーブルのFAILED状態を示します。この場合は、推論テーブルを引き続き使用するには、新しいエンドポイントを作成する必要があります。
エンドポイントの作成中に推論テーブルを有効にするには、次のステップを使用します。
-
DatabricksのUIで 「Serving」 をクリックします。
-
サービングエンドポイントの作成 をクリックします。
-
推論テーブルを有効にする を選択します。
-
ドロップダウンメニューから、テーブルを配置したいカタログとスキーマを選択してください。
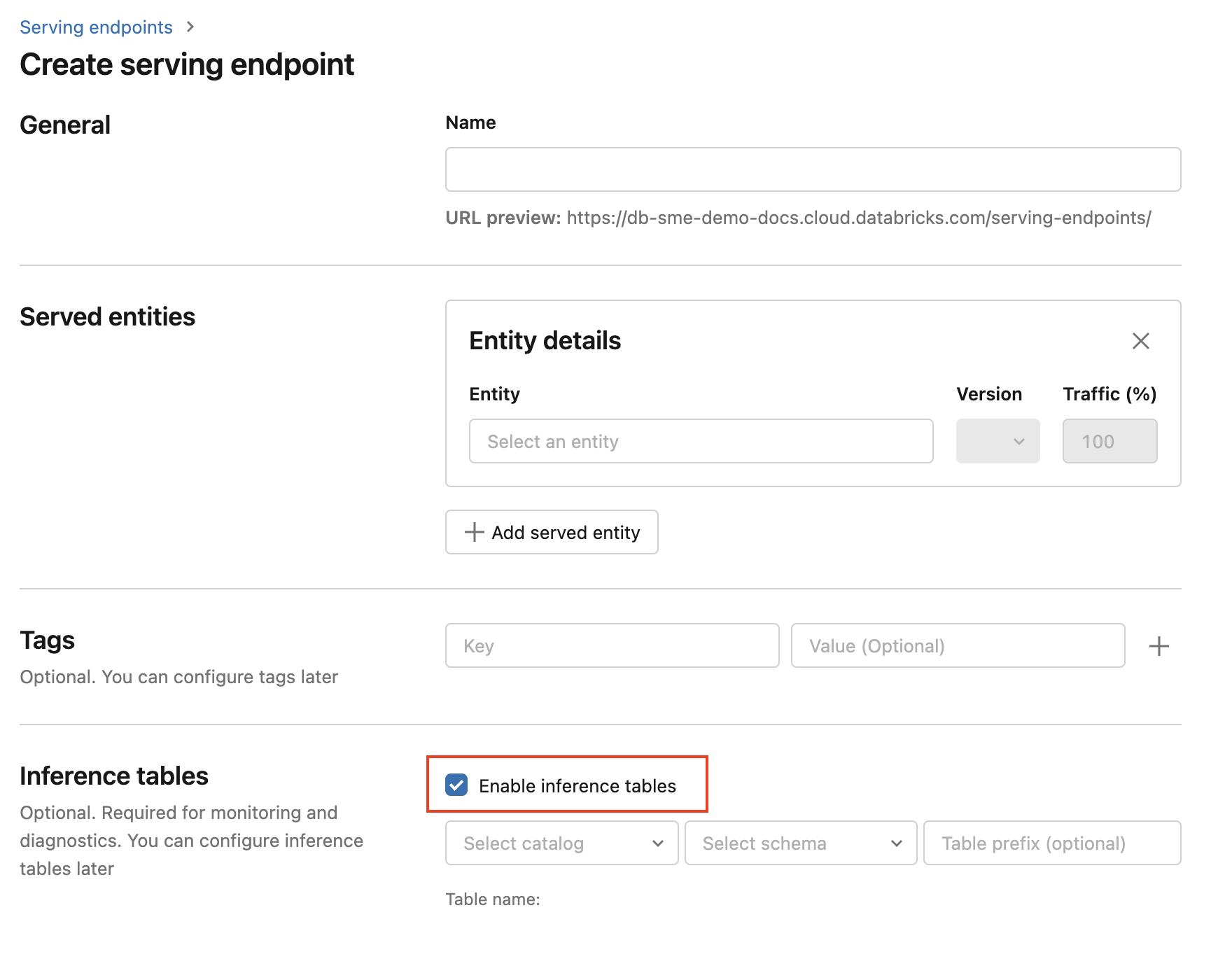
-
デフォルトのテーブル名は
<catalog>.<schema>.<endpoint-name>_payloadです。必要に応じて、カスタムテーブル接頭辞を入力できます。 -
サービングエンドポイントの作成 をクリックします。
既存のエンドポイントで推論テーブルを有効にすることもできます。既存のエンドポイント構成を編集するには、次の手順を実行します。
- エンドポイントページに移動してください。
- 構成の編集 をクリックします。
- ステップ 3 から始まる前の手順に従ってください。
- 完了したら、[ サービングエンドポイントの更新 ] をクリックします。
推論テーブルを無効にするには、以下の手順に従ってください。
- エンドポイントページに移動してください。
- 構成の編集 をクリックします。
- 推論テーブルを有効にする をクリックして、チェックマークを外します。
- エンドポイントの仕様に問題がなければ、 「更新」 をクリックしてください。
AI Gateway推論テーブルへの移行
エンドポイントがAI Gatewayの推論テーブルを使用するように移行した後、従来のテーブルに戻すことはできません。
AI Gatewayの推論テーブルは、従来の推論テーブルとは異なるスキーマを持っています。
価格情報については、 AI Gateway 価格ページをご覧ください。
このセクションでは、従来の推論テーブルからAI Gatewayの推論テーブルに移行する方法について説明します。
構成を更新するには、主に 2 つのステップがあります。
- 従来の推論テーブルを無効にするように、サービス提供エンドポイントを更新してください。
- AI Gatewayの推論テーブルを有効にするために、サービス提供エンドポイントを更新してください。
UIを使用して推論テーブル構成を移行します
少数のサービス提供エンドポイントの場合は、UIでエンドポイント構成を編集します。
-
DatabricksのUIで 「Serving」 をクリックし、エンドポイントページに移動します。
-
構成の編集 をクリックします。
-
チェックマークを外すには、「 推論テーブルを有効にする」 をクリックしてください。
-
「更新」 をクリックし、エンドポイントの状態が 「準備 完了」になるまで待ちます。
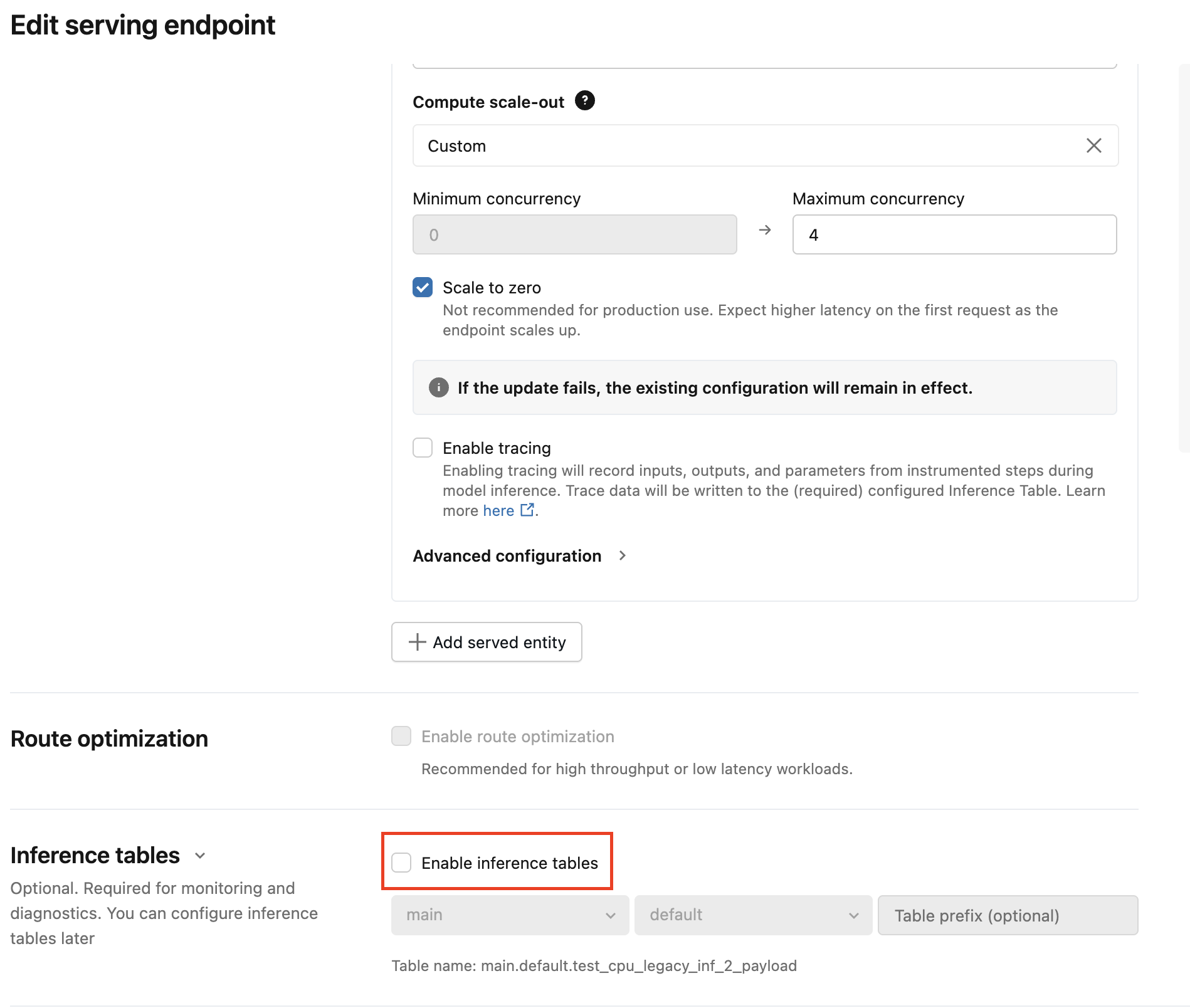
AI Gatewayの推論テーブルを有効にするには、以下の手順に従ってください。
-
DatabricksのUIで 「Serving」 をクリックし、エンドポイントページに移動します。
-
AI Gatewayの編集 をクリックします。
-
「推論テーブルを有効にする」 をクリックします。
-
ドロップダウンメニューから、テーブルを配置したいカタログとスキーマを選択してください。
-
デフォルトのテーブル名は
<catalog>.<schema>.<endpoint-name>_payloadです。必要に応じて、カスタムテーブル接頭辞を入力してください。 -
更新 をクリックします。
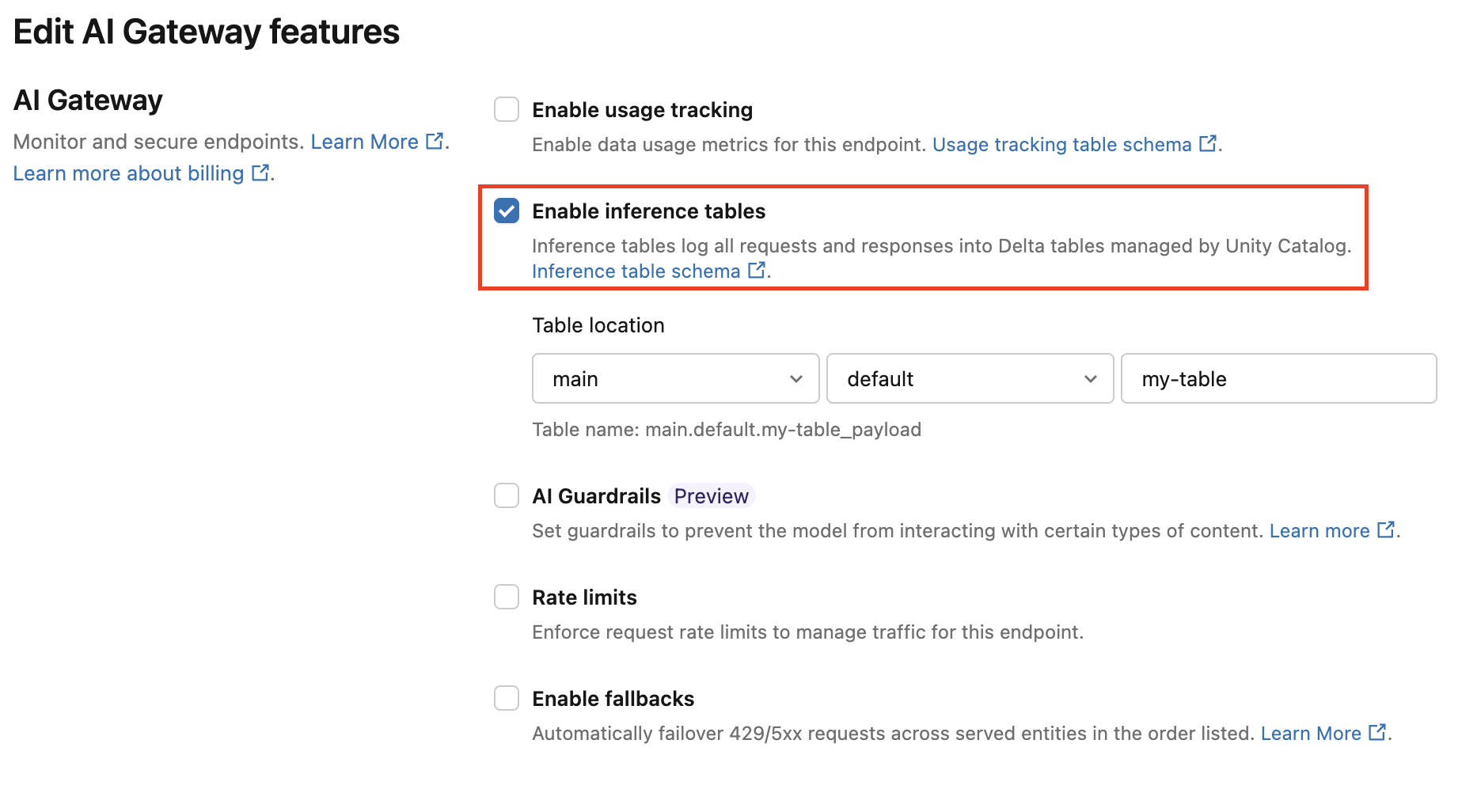
ノートブックを使用して推論テーブル構成を移行します
多くのエンドポイントでは、APIを使用して移行プロセスを自動化できます。Databricks 、サービング エンドポイントを一括移行するノートブックの例と、既存のデータをレガシー推論テーブルからAI Gateway 推論テーブルに移行する方法の例を提供します。
AI Gateway推論テーブルノートブックへの移行
ワークフロー:推論テーブルを使用してモデルのパフォーマンスを監視する
推論テーブルを使用してモデルのパフォーマンスを監視するには、次のステップに従います。
- エンドポイントの作成時、または作成後に更新することで、エンドポイント上で推論テーブルを有効にしてください。
- エンドポイントのスキーマに従ってJSONペイロードを解凍し、推論テーブル内のJSONペイロードを処理するワークフローをスケジュールします。
- (オプション)モデルの品質メトリクスを計算できるように、展開されたリクエストとレスポンスをグラウンドトゥルースラベルと結合します。
- 結果として得られるDeltaテーブルに対してモニターを作成し、メトリクスを更新します。
スターターノートブックには、このワークフローが実装されています。
推論テーブル監視のスターターノートブック
次のノートブックは、データプロファイリング推論テーブルからのリクエストをアンパックするために、上で概説したステップを実装します。 ノートブックは、オンデマンドで実行することも、 Lakeflowジョブを使用して定期的なスケジュールで実行することもできます。
推論テーブルデータプロファイリング入門ノートブック
LLM を提供するエンドポイントからのテキスト品質をモニタリングするためのスターター ノートブック
次のノートブックは、推論テーブルからの要求をアンパックし、テキスト評価メトリクスのセット (可読性や毒性など) をコンピュートし、これらのメトリクスに対するモニタリングを有効にします。 ノートブックは、オンデマンドで実行することも、 Lakeflowジョブを使用して定期的なスケジュールで実行することもできます。
LLM推論テーブルデータプロファイリング入門ノートブック
推論テーブルで結果を照会および分析する
提供されたモデルの準備が整うと、モデルに対して行われたすべてのリクエストは、レスポンスとともに推論テーブルに自動的に記録されます。テーブルはUIで表示したり、DBSQLやノートブックからクエリを実行したり、REST APIを使用してクエリを実行したりできます。
UI でテーブルを表示するには: エンドポイントページで、推論テーブルの名前をクリックして、カタログエクスプローラーでテーブルを開きます。

DBSQL またはDatabricksノートブックからテーブルをクエリするには: 推論テーブルを照会するには、以下のようなコードを実行できます。
SELECT * FROM <catalog>.<schema>.<payload_table>
UI を使用して推論テーブルを有効にした場合、 payload_tableエンドポイントを作成した際に割り当てたテーブル名です。API を使用して推論テーブルを有効にした場合、 payload_tableはauto_capture_configレスポンスのstateセクションに報告されます。例については、 「 APIを使用してモデルサービング エンドポイントで推論テーブルを有効にする」を参照してください。
パフォーマンスノート
エンドポイントを呼び出した後、スコアリングリクエストを送信してから1時間以内に、その呼び出しが推論テーブルにログとして記録されます。さらに、Databricksはログ配信が少なくとも1回行われることを保証しているため、重複したログが送信される可能性は低いものの、ゼロではありません。
Unity Catalog推論テーブルスキーマ
推論テーブルにログ記録される各リクエストとレスポンスは、以下のスキーマを持つDeltaテーブルに書き込まれます。
入力のバッチを使用してエンドポイントを呼び出すと、バッチ全体が 1 行として記録されます。
列名 | 説明 | Type |
|---|---|---|
| すべてのモデルサービング要求にアタッチされる Databricksが生成するリクエストの識別子。 | STRING |
| オプションのクライアント生成リクエスト識別子。モデルサービング リクエスト本文で指定できます。 詳細については、 | STRING |
| モデルサービングリクエストが受信された UTC 日付。 | DATE |
| モデルサービングリクエストが受信されたときのタイムスタンプ (エポックミリ秒単位)。 | LONG |
| モデルから返されたHTTPステータスコード。 | INT |
| リクエストがダウンサンプリングされた場合に使用されるサンプリング比率。この値は0から1の間であり、1は受信したリクエストの100%が含まれたことを示します。 | DOUBLE |
| モデルが推論を実行した実行時間(ミリ秒)。これはネットワークのオーバーヘッド遅延を含まず、モデルが予測を生成するのにかかった時間のみを表しています。 | LONG |
| モデルビングサーエンドポイントに送信された生のリクエストJSON本文。 | STRING |
| モデルビングサーエンドポイントから返された生の応答JSON本文。 | STRING |
| リクエストに関連付けられたモデルサービング エンドポイントに関連するメタデータのマップ。 このマップには、エンドポイント名、モデル名、およびエンドポイントに使用されているモデルバージョンが含まれています。 | MAP<STRING, STRING> |
指定: client_request_id
client_request_id フィールドは、ユーザーがモデルサービングリクエスト本文で指定できるオプションの値です。これにより、ユーザーは、 client_request_id の下の最終的な推論テーブルに表示されるリクエストに独自の識別子を指定でき、グラウンドトゥルースラベルの結合など、 client_request_idを使用する他のテーブルとリクエストを結合するために使用できます。 client_request_idを指定するには、そのを要求ペイロードの最上位キーとして含めます。client_request_idが指定されていない場合、値は要求に対応する行に null として表示されます。
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_idは、 client_request_idに関連付けられたラベルを持つ他のテーブルがある場合、後でグラウンドトゥルースラベル結合に使用できます。
制限事項
- 顧客管理キーはサポートされていません。
- 基盤モデルをホストするエンドポイントの場合、推論テーブルはプロビジョニングされたスループットワークロードでのみサポートされます。
- AWS PrivateLinkはデフォルトではサポートされていません。この機能を有効にするには、Databricksのアカウントチームにお問い合わせください。
- 推論テーブルが有効になっている場合、単一のエンドポイントで提供されるすべてのモデルの合計最大同時実行数の制限は128です。この制限の引き上げをご希望の場合は、Databricksのアカウントチームまでお問い合わせください。
- 推論テーブルに50万個を超えるファイルが含まれている場合、追加のデータはログに記録されません。この制限を超えないようにするには、 OPTIMIZEを実行するか、古いデータを削除してテーブルの保持期間を設定してください。テーブル内のファイル数を確認するには、
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>を実行します。 - 推論テーブルのログ配信は現在ベストエフォート型ですが、リクエストから1時間以内にログが利用可能になる見込みです。詳細については、 Databricksアカウント チームにお問い合わせください。
一般的なモデルサービング エンドポイントの制限については、 「モデルサービングの制限とリージョン」を参照してください。