SQL Server からデータを取り込む
このページでは、 Lakeflow Connect使用してSQL Serverからデータを取り込み、 Databricksにロードする方法について説明します。 SQL Server コネクタは、Azure SQL Database、Azure SQL Managed Instance、Amazon RDS SQL データベースをサポートします。これには、Azure 仮想マシン (VM) および Amazon EC2 上で実行される SQL Server が含まれます。このコネクタは、Azure ExpressRoute および AWS Direct Connect ネットワークを使用したオンプレミスの SQL Server もサポートします。
始める前に
インジェスト ゲートウェイとインジェスト パイプラインを作成するには、次の要件を満たす必要があります。
-
ワークスペースが Unity Catalog に対して有効になっています。
-
サーバレス コンピュートがワークスペースで有効になっています。 サーバレス コンピュートの要件を参照してください。
-
接続を作成する予定の場合: メタストアに対する
CREATE CONNECTION権限があります。コネクタが UI ベースのパイプラインオーサリングをサポートしている場合は、このページの手順を完了することで、接続とパイプラインを同時に作成できます。ただし、API ベースのパイプラインオーサリングを使用する場合は、このページの手順を完了する前に、Catalog Explorer で接続を作成する必要があります。「管理された取り込みソースに接続する」を参照してください。
-
既存の接続を使用する予定の場合: 接続に対する
USE CONNECTION権限またはALL PRIVILEGESがあります。 -
ターゲット・カタログに対する
USE CATALOG権限があります。 -
既存のスキーマに対する
USE SCHEMA、CREATE TABLE、CREATE VOLUME権限、またはターゲットカタログに対するCREATE SCHEMA権限を持っている。 -
プライマリ SQL Server インスタンスにアクセスできる。変更追跡機能とチェンジデータキャプチャ機能は、リードレプリカまたはセカンダリインスタンスではサポートされていません。
-
クラスターを作成するための無制限の権限、またはカスタム ポリシー (API のみ)。ゲートウェイのカスタム ポリシーは、次の要件を満たす必要があります。
-
ファミリー: ジョブ コンピュート
-
ポリシー ファミリを上書きします:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
} -
Databricks では、ゲートウェイのパフォーマンスに影響を与えないため、インジェスト ゲートウェイに可能な限り最小のワーカー ノードを指定することをお勧めします。次のコンピュート ポリシーを使用すると、 Databricks ワークロードのニーズに合わせてインジェスト ゲートウェイをスケーリングできます。 ソース データベースから効率的かつパフォーマンスの高いデータ抽出を可能にするための最小要件は 8 コアです。
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "r5n.16xlarge"
},
"node_type_id": {
"type": "fixed",
"value": "m5n.large"
}
}
詳細については、 情報 クラスターポリシーについては、「 コンピュートポリシーの選択」を参照してください。
-
SQL Server から取り込むには、 ソースのセットアップも完了する必要があります。
オプション 1: Databricks UI
管理者ユーザーは、UI で接続とパイプラインを同時に作成できます。これは、管理インジェスト パイプラインを作成する最も簡単な方法です。
-
Databricksワークスペースのサイドバーで、 データ取り込み をクリックします。
-
[ データの追加 ] ページの [Databricks コネクタ ] で、[ SQL Server ] をクリックします。
インジェスト ウィザードが開きます。
-
ウィザードの [インジェスト ゲートウェイ ] ページで、ゲートウェイの一意の名前を入力します。
-
ステージング取り込みデータのカタログとスキーマを選択し、[ 次へ ] をクリックします。
-
[ インジェスト パイプライン ] ページで、パイプラインの一意の名前を入力します。
-
[宛先カタログ] で、取り込んだデータを保存するカタログを選択します。
-
ソース データへのアクセスに必要な資格情報を格納する Unity Catalog 接続を選択します。
ソースへの既存の接続がない場合は、[ 接続の作成 ] をクリックし、 ソース設定から取得した認証の詳細を入力します。メタストアに対する
CREATE CONNECTION権限が必要です。 -
パイプラインの作成および続行 をクリックします。
-
[ ソース ] ページで、取り込むテーブルを選択します。
-
必要に応じて、デフォルトの履歴追跡設定を変更します。詳細については、 情報 「履歴追跡を有効にする (SCD タイプ 2)」を参照してください。
-
次へ をクリックします。
-
宛先 ページで、書き込む Unity Catalog カタログとスキーマを選択します。
既存のスキーマを使用しない場合は、[ スキーマの作成 ] をクリックします。親カタログに対する
USE CATALOG権限とCREATE SCHEMA権限が必要です。 -
保存して続行 をクリックします。
-
(オプション) 設定 ページで、 スケジュールの作成 をクリックします。宛先テーブルを更新する頻度を設定します。
-
(オプション)パイプライン操作の成功または失敗のEメール 通知を設定します。
-
パイプラインの保存と実行 をクリックします。
オプション 2: その他のインターフェイス
Databricks Asset Bundles、Databricks APIs、Databricks SDK、または Databricks CLIを使用して取り込む前に、既存の Unity Catalog 接続にアクセスできる必要があります。手順については、「 管理されたインジェスト ソースに接続する」を参照してください。
ステージング カタログとスキーマを作成する
ステージング カタログとスキーマは、宛先カタログとスキーマと同じにすることができます。ステージング カタログをフォーリンカタログにすることはできません。
- CLI
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
ゲートウェイと取り込み パイプラインを作成する
インジェスト ゲートウェイは、ソース データベースからスナップショットと変更データを抽出し、それを Unity Catalog ステージング ボリュームに格納します。ゲートウェイは、連続パイプラインとして実行する必要があります。これにより、ソース・データベースにある変更ログの保持ポリシーに対応できます。
取り込み パイプラインは、スナップショットと変更データをステージング ボリュームから宛先ストリーミングテーブルに適用します。
- Databricks Asset Bundles
- Notebook
- CLI
このタブでは、Databricks Asset Bundle を使用して取り込み パイプラインをデプロイする方法について説明します。バンドルには、ジョブとタスクの YAML 定義を含めることができ、 Databricks CLIを使用して管理され、異なるターゲット ワークスペース (開発、ステージング、本番運用など) で共有および実行できます。 詳細については、「Databricksアセットバンドル」を参照してください。
-
Databricks CLI を使用して新しいバンドルを作成します。
Bashdatabricks bundle init -
バンドルに 2 つの新しいリソース ファイルを追加します。
- パイプライン定義ファイル (
resources/sqlserver_pipeline.yml)。 - データ取り込みの頻度を制御するワークフロー ファイル (
resources/sqlserver.yml)。
次に、
resources/sqlserver_pipeline.ymlファイルの例を示します。YAMLvariables:
# Common variables used multiple places in the DAB definition.
gateway_name:
default: sqlserver-gateway
dest_catalog:
default: main
dest_schema:
default: ingest-destination-schema
resources:
pipelines:
gateway:
name: ${var.gateway_name}
gateway_definition:
connection_name: <sqlserver-connection>
gateway_storage_catalog: main
gateway_storage_schema: ${var.dest_schema}
gateway_storage_name: ${var.gateway_name}
target: ${var.dest_schema}
catalog: ${var.dest_catalog}
pipeline_sqlserver:
name: sqlserver-ingestion-pipeline
ingestion_definition:
ingestion_gateway_id: ${resources.pipelines.gateway.id}
objects:
# Modify this with your tables!
- table:
# Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item.
source_catalog: test
source_schema: ingestion_demo
source_table: lineitem
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
- schema:
# Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination
# table name will be the same as it is on the source.
source_catalog: test
source_schema: ingestion_whole_schema
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
target: ${var.dest_schema}
catalog: ${var.dest_catalog}次に、
resources/sqlserver_job.ymlファイルの例を示します。YAMLresources:
jobs:
sqlserver_dab_job:
name: sqlserver_dab_job
trigger:
# Run this job every day, exactly one day from the last run
# See https://docs.databricks.com/api/workspace/jobs/create#trigger
periodic:
interval: 1
unit: DAYS
email_notifications:
on_failure:
- <email-address>
tasks:
- task_key: refresh_pipeline
pipeline_task:
pipeline_id: ${resources.pipelines.pipeline_sqlserver.id} - パイプライン定義ファイル (
-
Databricks CLI を使用してパイプラインをデプロイします。
Bashdatabricks bundle deploy
次のノートブックの Configuration セルを、ソースから取り込むソース接続、ターゲット カタログ、ターゲット スキーマ、およびテーブルで更新します。
ゲートウェイと取り込み パイプラインを作成する
ゲートウェイを作成するには:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
取り込みパイプラインを作成するには:
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
パイプラインの開始、スケジュール設定、アラートの設定
パイプラインの詳細ページでパイプラインのスケジュールを作成できます。
-
パイプラインが作成されたら、 Databricks ワークスペースに再度アクセスし、[ パイプライン ] をクリックします。
新しいパイプラインがパイプライン リストに表示されます。
-
パイプラインの詳細を表示するには、パイプライン名をクリックします。
-
パイプラインの詳細ページで、 スケジュール をクリックしてパイプラインをスケジュールできます。
-
パイプラインに通知を設定するには、[ 設定 ] をクリックし、通知を追加します。
パイプラインに追加するスケジュールごとに、 Lakeflowコネクト によってそのジョブが自動的に作成されます。 インジェスト パイプラインは、ジョブ内のタスクです。オプションで、ジョブにタスクを追加できます。
データ取り込みが成功したことを確認する
パイプラインの詳細ページのリストビューには、データの取り込み時に処理されたレコードの数が表示されます。これらの番号は自動的に更新されます。
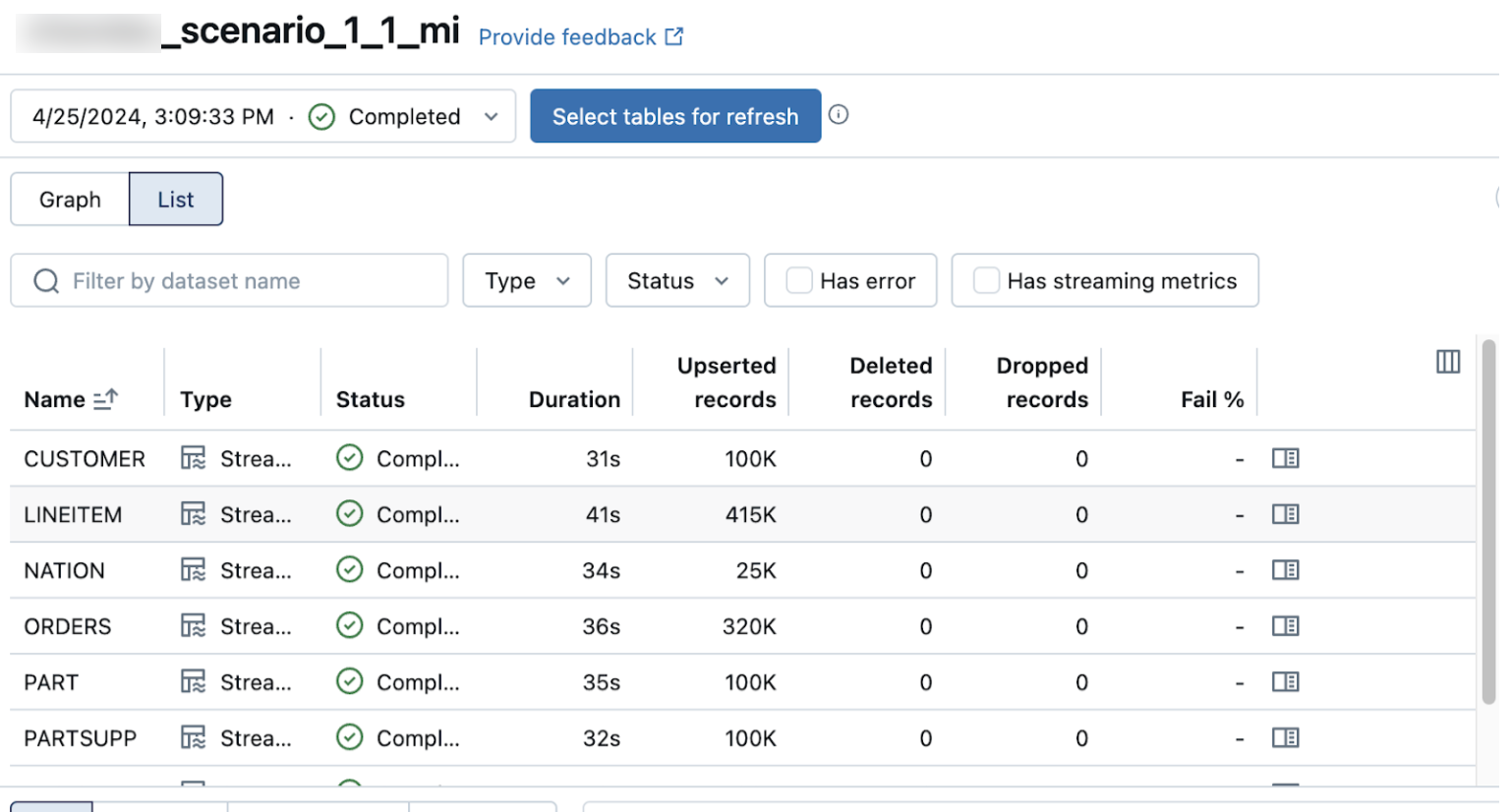
Upserted records列とDeleted records列は、デフォルトでは表示されません。これらを有効にするには、列の設定 ![]() ボタンをクリックして選択します。
ボタンをクリックして選択します。