Lakeflowジョブでのdbt変換の使用
dbt Core プロジェクトをジョブのタスクとして実行できます。dbt Core プロジェクトをジョブ タスクとして実行すると、次の Lakeflow ジョブ機能を利用できます。
- dbt タスクを自動化し、dbt タスクを含むワークフローをスケジュールします。
- dbt 変換を監視し、変換のステータスに関する通知を送信します。
- dbt プロジェクトを他のタスクと共にワークフローに含めます。 たとえば、ワークフローでは、 Auto Loaderを使用してデータを取り込み、 dbtを使用してデータを変換し、ノートブック タスクを使用してデータを分析できます。
- ジョブ実行からのアーティファクト (ログ、結果、マニフェスト、構成など) の自動アーカイブ。
dbt Core の詳細については、 dbt のドキュメントを参照してください。
ワークフローの開発と本番運用
Databricks では、Databricks SQL ウェアハウスに対して dbt プロジェクトを開発することをお勧めします。 Databricks SQLウェアハウスを使用すると、SQL によって生成されたdbt をテストし、SQL ウェアハウスのクエリ履歴 を使用してdbt によって生成されたクエリをデバッグできます。
本番運用でdbt 変換を実行するには、Databricksジョブでdbtタスクを使用することをお勧めします。デフォルトにより、dbt タスクはDatabricksコンピュートを用いてPython処理を実行し、選択したSQLウェアハウスに対してdbtが生成したSQLを実行します。
dbt変換は、サーバレス SQLウェアハウスまたはプロ SQLウェアハウス、Databricks コンピュート、またはその他のdbt対応ウェアハウスで実行できます。この記事では、最初の 2 つのオプションについて例を挙げて説明します。
ワークスペースが Unity Catalog に対応しており、 サーバレス ジョブ が有効になっている場合、デフォルトによって、サーバレス コンピュートでジョブが実行されます。
SQLウェアハウスでdbtモデルを開発し、それをDatabricks コンピュートの本番運用で実行すると、パフォーマンスやSQL 言語サポートに微妙な違いが生じることがあります。Databricksでは、コンピュートのDatabricksランタイムとSQL ウェアハウスに同じ バージョンを使用することをお勧めします。
必要条件
-
dbt Core と
dbt-databricksパッケージを使用して開発環境で dbt プロジェクトを作成および実行する方法については、「 dbt Core への接続」を参照してください。Databricks では、dbt-spark パッケージではなく、 dbt-databricks パッケージをお勧めします。 dbt-databricks パッケージは、Databricks 用に最適化された dbt-spark のフォークです。
-
Databricks ジョブで dbt プロジェクトを使用するには、 Databricks Git フォルダーを設定する必要があります。DBFS から dbt プロジェクトを実行することはできません。
-
サーバレスまたはプロ SQLウェアハウスを有効にする必要があります。
-
Databricks SQLのエンタイトルメントが必要です。
最初の dbt ジョブを作成して実行する
次の例では、dbt のコア概念を示すサンプル プロジェクトである jaffle_shop プロジェクトを使用しています。 ジャッフルショッププロジェクトを実行するジョブを作成するには、次の手順を実行します。
-
ワークスペースで、サイドバーの
 ジョブ & パイプライン をクリックします。
ジョブ & パイプライン をクリックします。 -
作成 をクリックし、 ジョブ をクリックします。
-
最初のタスクを構成するには、 dbt タイルをクリックします。 dbt タイルが利用できない場合は、 [別のタスク タイプを追加] をクリックし、 dbt を検索します。
-
オプションで、ジョブの名前 (デフォルトは
New Job <date-time>) をジョブ名に置き換えます。 -
タスク名 に、タスクの名前を入力します。
-
[ ソース ] ドロップダウンメニューで、[ Git プロバイダー ] を選択するのは、この例では Git リポジトリにあるジャッフルショッププロジェクトを使用しているためです。
-
[プロジェクト ディレクトリ ] に、Git リポジトリの URL を入力します:
https://github.com/dbt-labs/jaffle_shop.git。
-
dbt コマンド テキスト ボックスで、実行するコマンド ( deps 、 seed 、 および実行 ) dbtを指定します。これらがデフォルトである必要があります。すべてのコマンドの前に
dbtを付ける必要があります。コマンドは、指定された順序で実行されます。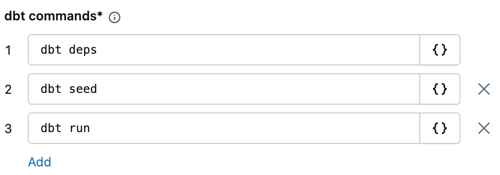
-
SQLウェアハウス で、dbtによって生成されたSQL を実行するSQLウェアハウスを選択します。 SQLウェアハウス のドロップダウンメニューには、サーバレスとプロSQLウェアハウスのみが表示されます。
-
(オプション)タスク出力のカタログとスキーマを指定できます。デフォルトでは、
defaultカタログとスキーマが使用されます。 -
(オプション)実行dbt Coreコンピュート構成を変更したい場合は、 コンピュートdbt CLI をクリックします。既存のコンピュート オプションを選択するか、[ 新しいジョブ クラスターを追加 ] をクリックして新しいジョブ クラスターを作成します。
-
[ 環境とライブラリ ] ドロップダウンで、
dbt-defaultを選択したままにします。 -
「 タスクを作成 」をクリックします。
-
ジョブを今すぐ実行するには、[
 ] をクリックします。
] をクリックします。
dbt ジョブ タスクの結果を表示する
ジョブが完了したら、ノートブックからSQLクエリを実行するか、SQLウェアハウスでクエリを実行することで、結果をテストできます。たとえば、次のサンプル クエリを参照してください。
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
<schema> をタスク設定で設定されたスキーマ名に置き換えます。
API の例
また、Jobs API を使用して、dbt タスクを含むジョブを作成および管理することもできます。次の例では、1 つの dbt タスクを持つジョブを作成します。
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": ["dbt deps", "dbt seed", "dbt run"],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(上級者向け)カスタムプロファイルで dbt を実行する
SQLウェアハウス (推奨) または汎用コンピュートを使用してdbtタスクを実行するには、接続先のウェアハウスまたはDatabricks コンピュートを定義するカスタムprofiles.ymlを使用します。ウェアハウスまたは汎用コンピュートを使用してjaffle shopプロジェクトを実行するジョブを作成するには、次の手順を実行します。
タスクの対象として使用できるのは、 SQLウェアハウスまたは汎用コンピュートのみです。dbtジョブ コンピュートを dbtの対象にすることはできません。
-
jaffle_shopリポジトリのフォークを作成します。
-
フォークしたリポジトリをデスクトップにクローンします。 たとえば、次のようなコマンドを実行できます。
Bashgit clone https://github.com/<username>/jaffle_shop.git<username>を GitHub ハンドルに置き換えます。 -
次の内容で、
jaffle_shopディレクトリにprofiles.ymlという新しいファイルを作成します。YAMLjaffle_shop:
target: databricks_job
outputs:
databricks_job:
type: databricks
method: http
schema: '<schema>'
host: '<http-host>'
http_path: '<http-path>'
token: "{{ env_var('DBT_ACCESS_TOKEN') }}"<schema>をプロジェクトテーブルのスキーマ名に置き換えてください。- SQLウェアハウスで dbtタスクを実行するには、
<http-host>をお使いのSQLウェアハウスの接続詳細タブの Server Hostname の値に置き換えます。汎用コンピュートでdbtタスクを実行するには、<http-host>をお使いのDatabricksコンピュートの詳細オプションのJDBC/ODBC タブの Server Hostname の値で置き換えます。 - SQLウェアハウスで dbtタスクを実行するには、
<http-path>をお使いのSQLウェアハウスの接続詳細の HTTP Path の値で置き換えます。汎用コンピュートでdbtタスクを実行するには、<http-path>をお使いのDatabricksコンピュートの 詳細オプションの JDBC/ODBCの HTTP Path の値で置き換えます。
このファイルはソース管理にチェックインするため、ファイル内にアクセストークンなどのシークレットを指定しません。 代わりに、このファイルは dbt テンプレート機能を使用して、ランタイム時に資格情報を動的に挿入します。
生成された認証情報は、実行期間中 (最大 30 日間) 有効で、完了後に自動的に取り消されます。
-
このファイルを Git にチェックインし、フォークしたリポジトリにプッシュします。 たとえば、次のようなコマンドを実行できます。
Bashgit add profiles.yml
git commit -m "adding profiles.yml for my Databricks job"
git push -
Databricks UI
のサイドバーで [ジョブ とパイプライン] をクリックします。 -
dbt ジョブを選択し、 タスク タブをクリックします。
-
ソース で 編集 をクリックし、フォークした jaffle shop GitHub リポジトリの詳細を入力します。
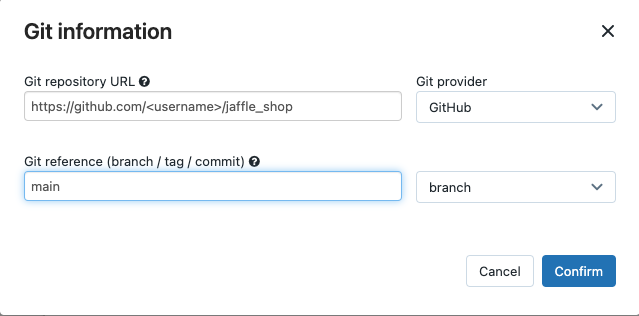
-
SQLウェアハウス で、 なし (手動) を選択します。
-
プロファイル・ディレクトリ に、
profiles.ymlファイルを含むディレクトリへの相対パスを入力します。パス値を空白のままにして、リポジトリ ルートのデフォルトを使用します。
(上級者向け)ワークフローでの dbt Python モデルの使用
Python モデルの dbt サポートはベータ版であり、dbt 1.3 以上が必要です。
dbtではDatabricksを含む特定のデータウェアハウスでのPythonモデルをサポートしています。dbt Python モデルでは、Python エコシステムのツールを使用して、SQL では実装が困難な変換を実装できます。 Databricksジョブを作成して、dbt Pythonモデルで 1 つのタスクを実行することも、複数のタスクを含むワークフローの一部としてdbtタスクを含めることもできます。
SQLウェアハウスを使用して、 dbtタスクで Pythonモデルを実行することはできません。Databricksでのdbt Pythonモデルの使用の詳細については、dbtドキュメントの 特定のデータウェアハウスを参照してください。
エラーとトラブルシューティング
プロファイル ファイルが存在しません エラー
エラーメッセージ :
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
考えられる原因 :
指定された$PATHに profiles.yml ファイルが見つかりませんでした。 dbt プロジェクトのルートに profiles.yml ファイルが含まれていることを確認します。