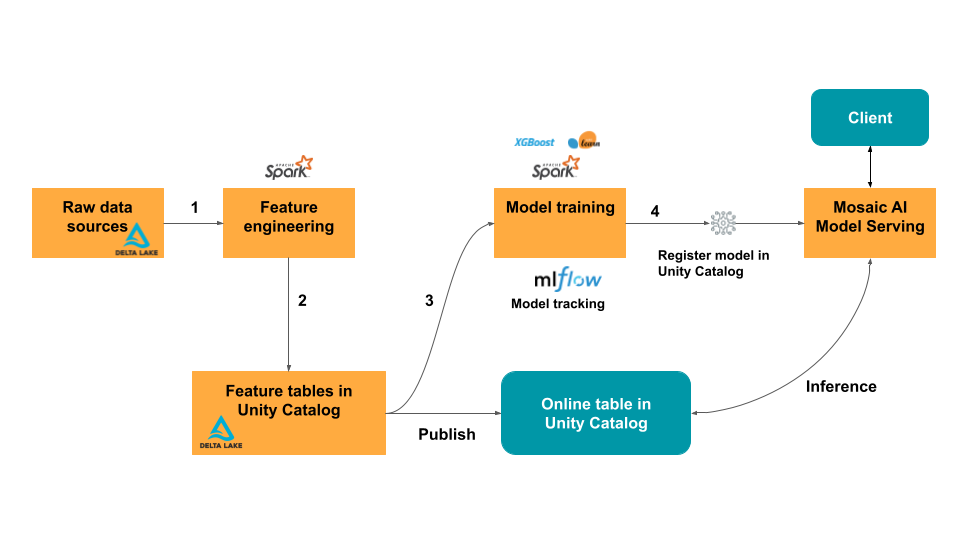
オンラインワークフローで機能を使用する
Unity Catalog で特徴量エンジニアリングを使用すると、モデル開発プロセスのすべてのステップが Databricks Data Intelligence Platform に統合されます。 つまり、自動化されたデータパイプラインをコンピュートに構築し、 Databricks インフラストラクチャを処理しながら機能値を提供できます。 Databricks プラットフォームは、特徴値のオンデマンド計算など、特徴とモデルの両方に対してリアルタイムのサービスを提供します。
自動フィーチャ検索
Databricks機能エンジニアリング クライアントを使用してモデルをトレーニングし、それをDatabricksモデルサービングで提供すると、モデルはDatabricksオンラインFeature Storeまたはサードパーティのオンライン ストアから機能値を自動的に検索します。 これはセットアップを必要とせず自動的に行われます。
Databricks オンライン テーブルはサポートされなくなりました。既存のオンライン テーブルがある場合、Databricks ではそれらをDatabricks Online Feature Storeに移行することをお勧めします。「レガシーおよびサードパーティのオンライン テーブルからの移行」を参照してください。
スコアリング要求がモデルに届くと、モデルサービングはモデルに必要な公開された特徴値を自動的に取得します。 このように、最新の特徴値が常に予測に使用されます。詳細とノートブックの例については、「 モデルサービングと自動機能検索」を参照してください。
次の図は、リアルタイム サービングのプラットフォーム コンポーネント間の関係を示しています。
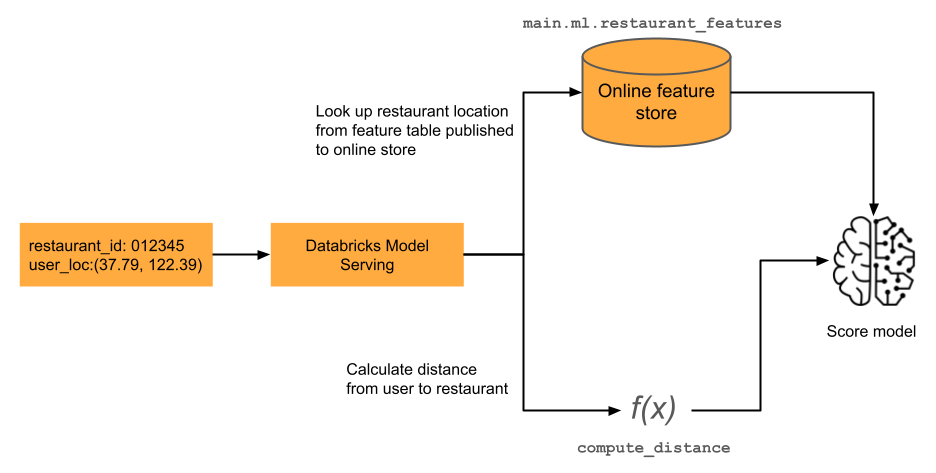
オンデマンド機能
リアルタイム アプリケーションの機械学習モデルでは、多くの場合、最新の特徴値が必要です。図に示されている例では、レストランのレコメンデーション モデルの 1 つの特徴は、ユーザーのレストランからの現在の距離です。この機能は、「オンデマンド」、つまりスコアリング要求時に計算する必要があります。スコアリング要求を受け取ると、モデルはレストランの場所を検索し、事前定義された関数を適用して、ユーザーの現在地とレストランの間の距離を計算します。その距離は、フィーチャ ストアから事前に計算された他のフィーチャとともに、モデルへの入力として渡されます。詳細については、「 コンピュート オンデマンド機能」を参照してください。