Databricks AI Search
Databricks AI Search (旧 Databricks ベクトル検索) は、Databricks Data Intelligence Platform に組み込まれており、そのガバナンスおよび生産性向上ツールと統合された検索ソリューションです。クエリに最も類似する埋め込みを見つけることで、RAGシステム、レコメンダーシステム、画像およびビデオ認識などの生成AIアプリケーションの検索機能を強化します。
ベクトル検索は、埋め込みの取得に最適化された検索です。エンベディングは、データ (通常はテキストまたは画像データ) の意味内容を数学的に表現したものです。埋め込みは大規模言語モデルによって生成され、互いに類似した文書や画像を検索することに依存する多くの生成AIアプリケーションの主要なコンポーネントです。
Databricks AI Searchを使用すると、DeltaテーブルからAI Searchインデックスを作成できます。インデックスにはメタデータを含む埋め込みデータが含まれます。その後、REST APIを使用してインデックスをクエリーし、最も類似したベクトルを特定し、関連するドキュメントを返すことができます。基礎となるDeltaテーブルが更新されると、自動的に同期するようにインデックスを構成することができます。
AI Searchでは、以下がサポートされています。
- ハイブリッド キーワード類似検索。
- 任意のエンドポイントにおける全文キーワード検索(ベータ版)、またはストレージ最適化エンドポイントにおける専用全文インデックス(ベータ版)
- フィルタリング。
- リランキング。
- AI Searchエンドポイントを管理するためのアクセス制御リスト(ACL)
- 選択した列のみを同期
- 「生成されたエンべディングを保存して同期する」
AI Searchはどのように機能しますか?
AI Search は、近似最近傍 (ANN) 検索に階層型ナビゲーション可能スモールワールド (HNSW) アルゴリズムを使用し、埋め込みベクトルの類似性を測定するためにL2距離メトリクスを使用します。コサイン類似度を使用する場合は、データポイントの埋め込みをベクトル検索アルゴリズムに入力する前に正規化する必要があります。データポイントが正規化されると、L2距離によって生成されるランキングは、コサイン類似度によって生成されるランキングと同じになります。
AI Searchは、ベクトルベースの埋め込み検索と従来のキーワードベースの検索技術を組み合わせた、ハイブリッドキーワード類似検索もサポートしています。このアプローチでは、クエリー内の単語を正確に一致させると同時に、ベクトルベースの類似性検索を使用してクエリーのセマンティック関係とコンテキストを取得します。
これら2つの技術を統合することで、ハイブリッドキーワード類似検索は、正確なキーワードだけでなく、概念的に類似したキーワードを含むドキュメントも検索し、より包括的で関連性の高い検索結果を提供します。このメソッドは、ソースデータにSKUや識別子のような一意のキーワードがあり、純粋な類似検索に適していないRAGアプリケーションで特に有効です。
APIの詳細については、Python SDKリファレンスおよびAI Search インデックスのクエリを参照してください。
類似性検索の計算
類似性検索の計算では、次の式を使用します。

ここで、 distはクエリーqとインデックスエントリx間のユークリッド距離です。

キーワード検索アルゴリズム
関連性スコアはOkapi BM25を使用して計算されます。ソーステキストの埋め込み列や、テキストまたは文字列形式のメタデータ列を含む、すべてのテキストまたは文字列列が検索されます。トークン化機能は、単語の境界で分割し、句読点を削除し、すべてのテキストを小文字に変換します。
類似検索とキーワード検索を組み合わせる方法
類似検索とキーワード検索の結果は、Reciprocal Rank Fusion(RRF)機能を使用して結合されます。
RRFは、まずスコアを使用して各メソッドからの各ドキュメントを再スコアリングします。


rrf_param 上位ランクのドキュメントと下位ランクのドキュメントの相対的な重要度を制御します。文献に基づいて、 rrf_paramは60に設定されています。
スコアは、以下の正規化係数を用いて最高のスコアが1となるように正規化されます。

各ドキュメントの最終スコアは、以下のように算出されます。

最も最終スコアの高いドキュメントが返されます。
ベクトルエンべディングを提供するためのオプション
DatabricksでAI Searchインデックスを作成するには、まずベクトルの埋め込みをどのように提供するかを決定する必要があります。Databricksは次の3つのオプションをサポートしています。
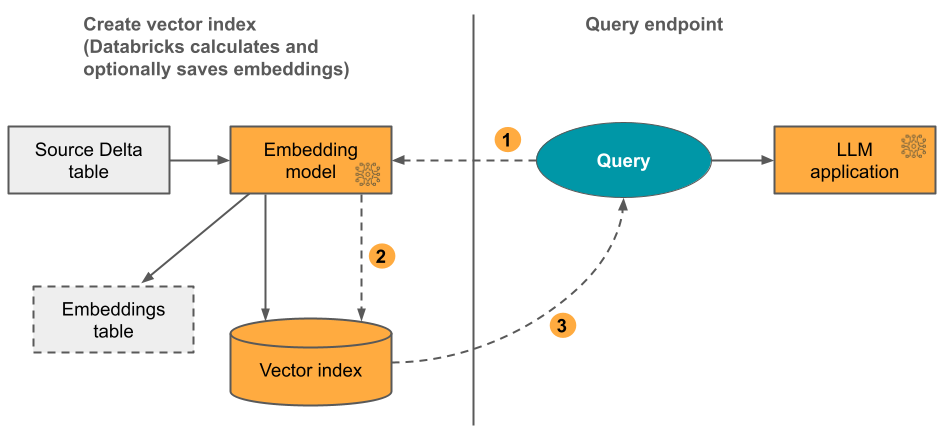
Option 1:Databricksによるエンべディングコンピュートを使用したDelta同期インデックス
このオプションでは、テキスト形式のデータを含むソースのDeltaテーブルを指定します。Databricks は、指定したモデルを使用してエンベディングを計算し、オプションで Unity Catalog のテーブルにエンベディングを保存します。Delta テーブルが更新されても、インデックスは Delta テーブルと同期されたままになります。
次の図は、このプロセスを示しています。
- クエリーの埋め込みを計算します。クエリーにはメタデータフィルターを含めることができます。
- 最も関連性の高い文書を特定するために類似検索を実行します。
- 最も関連性の高いドキュメントを返し、クエリーに追加します。
オプション2:自己管理型の埋め込みを使用したDelta同期インデックス
このオプションでは、事前に計算された埋め込みを含むソース Delta テーブルを指定します。Delta テーブルが更新されても、インデックスは Delta テーブルと同期されたままになります。
セルフマネージド埋め込みインデックスをDatabricks管理のインデックスに変換することはできません。後から管理された埋め込みを使用することに決定した場合は、新しいインデックスを作成し、埋め込みを再計算する必要があります。
次の図は、このプロセスを示しています。
- クエリーはエンベディングで構成され、メタデータフィルターを含めることができます。
- 類似性検索を実行して、最も関連性の高いドキュメントを特定します。最も関連性の高いドキュメントを返し、クエリーに追加します。

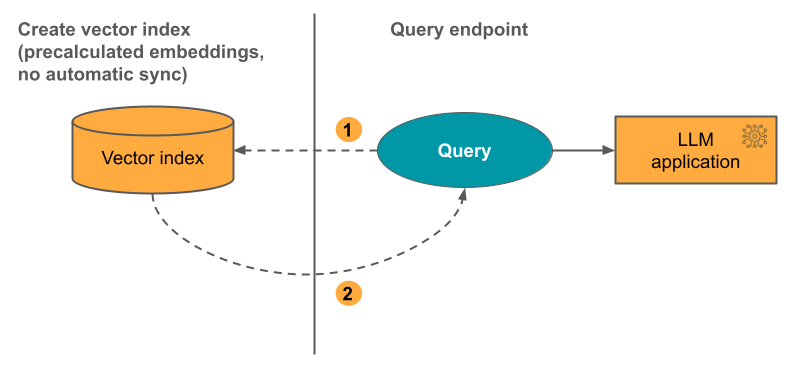
オプション 3: Direct Vector Access Index
このオプションでは、埋め込みテーブルが変更されたら、REST APIを使用してインデックスを手動で更新する必要があります。
次の図は、このプロセスを示しています。
オプション4:ストレージ最適化エンドポイントの全文検索インデックス(ベータ)
このオプションを使用すると、埋め込み列なしでストレージ最適化されたエンドポイント上にDelta Sync インデックスを作成できます。インデックスは、BM25スコアリングを使用したキーワードベースの全文検索をサポートしており、ベクトル埋め込みを必要としません。テキストデータ内で厳密な用語、識別子、またはキーワードの検索に役立ちます。
query_type="FULL_TEXT" も使用して、標準およびストレージ最適化された両方のエンドポイントで、既存の AI Searchインデックスに対してキーワード検索を実行できます。このオプションは、埋め込みを一切含まない専用のインデックスを作成するためのものです。
専用の全文検索インデックスは、ストレージ最適化エンドポイントでのみ利用可能で、トリガー同期モードが必要です。手順については、全文検索インデックスの作成(ベータ)を参照してください。
エンドポイントのオプション
AI Searchは、アプリケーションのニーズに合ったエンドポイント構成を選択できるよう、以下のオプションを提供します。
高QPSは標準のEndpointのみで利用可能です。
-
標準 エンドポイントは、次元768で3億2000万ベクトルの容量があります。
- 標準エンドポイントを使用すると、高QPSで高い持続スループットをサポートできます。高 QPS で AI Search エンドポイントのスループットをスケーリングするを参照してください。
-
ストレージ最適化 エンドポイントは容量が大きく(次元 768 で 10 億を超えるベクトル)、インデックス作成速度が 10~20 倍速くなります。ストレージ最適化エンドポイントでのクエリでは、レイテンシが約 250 ミリ秒とわずかに増加します。このオプションの価格は、ベクターの数が多いほど最適化されます。価格の詳細については、AI Search 価格ページを参照してください。AI Searchコストの管理に関する情報については、AI Searchコスト管理ガイドを参照してください。
エンドポイントを作成する際に、エンドポイントタイプを指定します。
ストレージ最適化エンドポイントの制限事項を参照してください。
AI Searchの設定方法
AI Search を使用するには、以下を作成する必要があります。
-
AI Searchエンドポイントです。このエンドポイントは、AI Searchインデックスを提供します。REST APIまたはSDKを使用してエンドポイントをクエリーおよび更新できます。手順については、AI Search エンドポイントを作成を参照してください。
エンドポイントは、インデックスのサイズまたは並列リクエストの数に対応するように自動的にスケールアップします。インデックスが削除された場合、エンドポイントは自動的にスケールダウンされます。
-
AI Searchインデックスです。AI SearchインデックスはDeltaテーブルから作成され、リアルタイムの近似最近傍 (ANN) 検索を提供するように最適化されています。検索の目的は、クエリに類似したドキュメントを特定することです。AI Search インデックスは Unity Catalog に表示され、Unity Catalog によって管理されます。手順については、AI Searchインデックスの作成を参照してください。
さらに、エンベディングをDatabricksに計算させることを選択した場合は、事前に構成された基盤モデル API エンドポイントを使用するか、モデルサービング エンドポイントを作成して、選択したエンベディングモデルを提供できます。 手順については、トークン単位の従量課金 基盤モデル API または 基盤モデルをサービングするエンドポイントの作成を参照してください。
モデルサービング エンドポイントをクエリするには、 REST API または Python SDKを使用します。 クエリでは、Delta テーブル内の任意の列に基づいてフィルターを定義できます。 詳細については、 クエリでフィルターを使用する、API リファレンス、または Python SDK リファレンスを参照してください。
要件
- Unity Catalog対応ワークスペースであること。
- サーバレス コンピュートが有効になっていること。 手順については、 サーバレス コンピュートへの接続を参照してください。
- 標準エンドポイントの場合、ソース テーブルでチェンジデータフィードが有効になっている必要があります。Databricksでのチェンジデータフィードの使用 を参照してください。
- AI Searchインデックスを作成するには、インデックスを作成するカタログスキーマに対するCREATE TABLE権限が必要です。
AI Searchエンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。AI Searchエンドポイント ACLを参照してください。
データ保護と認証
Databricksでは、データを保護するために次のセキュリティ制御機能を実装しています。
- AI Searchに対するすべての顧客のリクエストは、論理的に分離され、認証され、承認されます。
- AI Search は、保存中(AES-256)と転送中(TLS 1.2+)のすべてのデータを暗号化します。
AI Search は 2 つの認証モード、サービスプリンシパルと個人用アクセス トークン (PAT) をサポートしています。本番運用アプリケーションの場合、Databricksは、パーソナルアクセストークンと比較して、クエリごとのパフォーマンスが最大100ミリ秒高速になるサービスプリンシパルを使用することをお勧めします。
-
サービスプリンシパル トークン. 管理者は、サービスプリンシパル トークンを生成し、それを SDK または APIに渡すことができます。 サービスプリンシパルを使用するを参照してください。本番運用のユースケースでは、 Databricks はサービスプリンシパル トークンを使用することをお勧めします。
Python# Pass in a service principal
vsc = AISearchClient(workspace_url="...",
service_principal_client_id="...",
service_principal_client_secret="..."
) -
個人用アクセストークン。個人用アクセストークンを使用して、AI Searchで認証できます。パーソナルアクセス認証トークンを参照してください。ノートブック環境で SDK を使用する場合、SDK は認証用の PAT トークンを自動的に生成します。
Python# Pass in the PAT token
client = AISearchClient(workspace_url="...", personal_access_token="...")
顧客管理キー (CMK) は、2024 年 5 月 8 日以降に作成されたエンドポイントでサポートされています。
使用状況とコストを監視する
AI Searchインデックスとエンドポイントに関連する使用量とコストのモニタリングについては、「AI Search コスト管理ガイド」を参照してください。
使用ポリシーごとに使用量をクエリすることもできます。AI Search使用ポリシーをご覧ください。
リソースとデータサイズの上限
次の表は、AI Searchのエンドポイントとインデックスに対するリソースとデータサイズの上限をまとめたものです。
リソース | 粒度 | 上限 |
|---|---|---|
AI Searchエンドポイント | ワークスペースごと | 500 |
埋め込み(Delta Syncインデックス) | 標準エンドポイントごと | 768の埋め込みサイズで約320,000,000 〜160,000,000(埋め込み次元1536) 3072の埋め込みサイズで約80,000,000 (ほぼ線形にスケールします) |
エンべディング(Direct Vector Accessインデックス) | 標準エンドポイントごと | 約2,000,000(768埋め込みサイズ) |
埋め込み (ストレージ最適化エンドポイント) | ストレージ最適化エンドポイントごと | ~ 1,000,000,000を768の埋め込みサイズで |
エンベディングの次元 | インデックスごと | 4096 |
インデックス | エンドポイントごと | 50 |
列 | インデックスごと | 50 |
列 | サポートされているタイプ:バイト、ショート、整数、ロング、フロート、ダブル、Boolean、文字列、タイムスタンプ、日付、配列 | |
メタデータフィールド | インデックスごと | 50 |
インデックス名 | インデックスごと | 128文字 |
AI Searchのインデックスの作成と更新には、次の上限が適用されます。
リソース | 粒度 | 上限 |
|---|---|---|
Delta Syncインデックスの行サイズ | インデックスごと | 100KB |
Delta Syncインデックスの埋め込みソース列サイズ | インデックスごと | 32764バイト |
Direct Vectorインデックスの一括アップサートリクエストのサイズ | インデックスごと | 10MB |
Direct Vectorインデックスの一括削除リクエストのサイズ | インデックスごと | 10MB |
クエリーAPIには、次の制限が適用されます。
リソース | 粒度 | 上限 |
|---|---|---|
クエリテキストの長さ | クエリごと | 32764文字 |
ハイブリッド検索を使用する際のトークン | クエリごと | 1024単語または2バイト文字 |
フィルター条件 | フィルター句ごと | 1,024個の要素です |
返される結果の最大数(近似最近傍探索) | クエリごと | 10,000 |
返される結果の最大数(ハイブリッド キーワード類似性検索) | クエリごと | 200 |
返される結果の最大数 (全文検索) | クエリごと | 200 |
応答サイズ | クエリごと | 10MB |
制限事項:
- 列名
_idは予約されています。ソーステーブルに_idという名前の列がある場合、AI Searchインデックスを作成する前に名前を変更してください。 - 行および列レベルの権限はサポートされていません。ただし、フィルターAPI 使用してアプリケーションレベルのACLを独自に実装することは可能です。
- 別のワークスペースにインデックスのクローンを作成できません。Databricks SDK または REST API を使用して、クロスワークスペースリクエストを作成できます。
- インデックス容量は、インデックス作成時のソーステーブルサイズに基づいてプロビジョニングされます。小さいソーステーブルから開始すると、インデックスの成長が制限され、容量不足エラーが発生する可能性があります。そのため、インデックス作成前に、予期されるデータ量に合わせてソーステーブルのサイズを決定してください。
ストレージ最適化エンドポイントの制限事項
このセクションの制限事項は、ストレージ最適化エンドポイントにのみ適用されます。
-
連続同期モードはサポートされていません。
-
同期する列はサポートされていません。
-
埋め込みディメンションは 16 で均等に割り切れる必要があります。
-
段階的な更新は部分的にサポートされています。同期ごとに、AI Searchインデックスの一部を再構築する必要があります。
- ソース行が変更されていない場合、管理対象インデックスでは、以前にコンピュートされた埋め込みは再利用されます。
- 標準のエンドポイントと比較して、同期にかかるエンドツーエンドの時間の著しい短縮が予想されます。10億個の埋め込みを持つデータセットは、8時間以内に同期を完了する必要があります。サイズの小さいデータセットほど、同期にかかる時間は短くなります。
-
FedRAMP 準拠のワークスペースはサポートされていません。
-
カスタマーマネージドキー(CMK)はサポートされていません。
-
マネージド Delta Sync インデックスにカスタム埋め込みモデルを使用するには、「AI Query for Custom Models and External Models」プレビューを有効にする必要があります。プレビューを有効にする方法については、「Databricks プレビューの管理」を参照してください。
-
ストレージ最適化エンドポイントは、768次元のベクトル埋め込みを最大10億個までサポートしています。より大規模なユースケースをお持ちの場合は、アカウントチームにお問い合わせください。