ポイントインタイム フィーチャ結合
ポイントインタイムの正確性は、各ラベル観測が記録された時点での特徴値を反映するトレーニング データセットを作成します。これは、ラベルが記録された時点では利用できなかったモデルトレーニングに特徴値を使用する場合に発生する データリーケージ を防ぐために重要です。このタイプのエラーは検出が難しく、モデルのパフォーマンスに悪影響を与える可能性があります。
時系列特徴量テーブルには、トレーニング データセットの各行が行のタイムスタンプの時点で最新の既知の特徴値を表すことを保証するタイムスタンプ キー列が含まれています。 時系列特徴量テーブルは、時系列データ、イベントベースのデータ、時間集計データなど、特徴値が時間の経過とともに変化する場合に使用する必要があります。
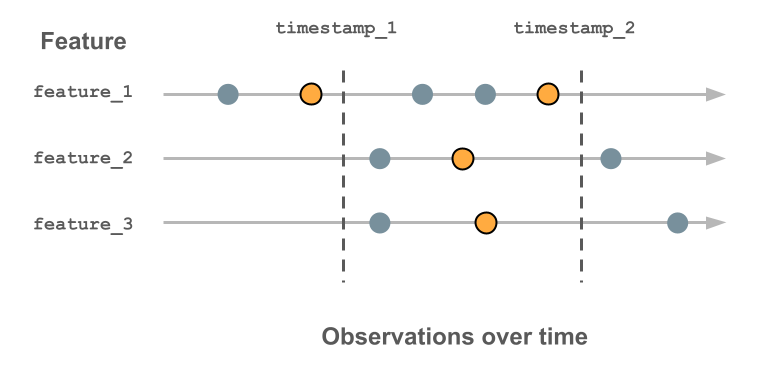
次の図は、タイムスタンプ キーの使用方法を示しています。 各タイムスタンプに記録された特徴値は、そのタイムスタンプより前の最新の値であり、枠線で囲まれたオレンジ色の円で示されています。 値が記録されていない場合、フィーチャ値は null です。 詳細については、 時系列 特徴量テーブルの仕組みを参照してください。
- Databricks Runtime13.3 LTS 以降では、プライマリキーとタイムスタンプキーを持つDelta の任意のUnity Catalog テーブルを時系列特徴量テーブルとして使用できます。
- 特定の時点の検索におけるパフォーマンスを向上させるため、Databricks は時系列テーブルに対してリキッドクラスタリング (
databricks-feature-engineering0.6.0 以降) の使用を推奨しています。テーブルに対するリキッドクラスタリングの使用とデータスキップを参照してください。 - ポイントインタイム ルックアップ機能は、「タイムトラベル」と呼ばれることもあります。 Databricks Feature Store のポイントインタイム機能は、 Delta Lake のタイムトラベルとは関係ありません。
時系列特徴量テーブルの仕組み
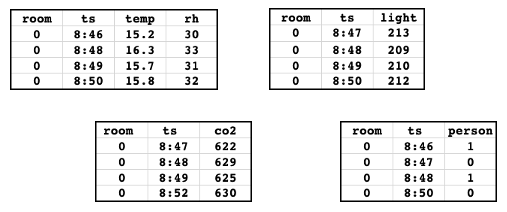
次の特徴量テーブルがあるとします。 このデータは、 サンプル ノートブックから取得されます。
テーブルには、部屋の温度、相対湿度、周囲光、二酸化炭素を測定するセンサーデータが含まれています。グラウンドトゥルーステーブルは、部屋に人がいたかどうかを示します。各テーブルには、プライマリキー('room')とタイムスタンプキー('ts')があります。わかりやすくするために、プライマリ・キー ('0') の 1 つの値のデータのみを示します。
次の図は、タイムスタンプキーを使用してトレーニングデータセットのポイントインタイムの正確性を確保する方法を示しています。 機能の値は、主キー (図には示されていません) とタイムスタンプ・キーに基づいて、AS OF ジョインを使用して照合されます。 AS OF 結合により、タイムスタンプの時点での特徴の最新の値がトレーニングセットで使用されるようになります。
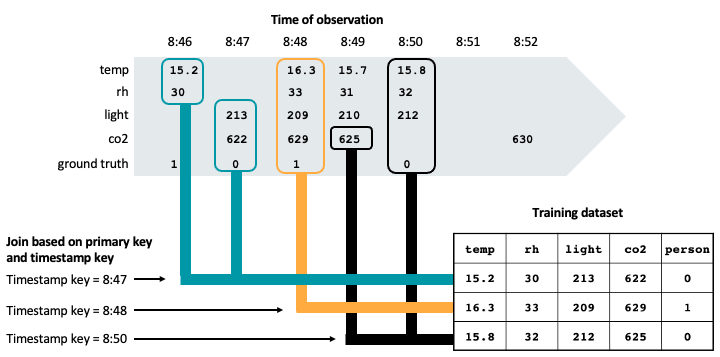
図に示すように、トレーニングデータセットには、観測されたグラウンドトゥルースのタイムスタンプより前の各センサーの最新の特徴値が含まれています。
タイムスタンプ キーをアカウントに取り込まずにトレーニング データセットを作成した場合、次の特徴値と観測されたグラウンド トゥルースを含む行が存在する可能性があります。
temp | rh | light | co2 | ground truth |
|---|---|---|---|---|
15.8 | 32 | 212 | 630 | 0 |
ただし、630 の co2 読み取り値は 8:52 に取得され、8:50 のグラウンド トゥルースの観測後であるため、これはトレーニングに有効な観測値ではありません。将来のデータはトレーニングセットに「漏れ」、モデルのパフォーマンスが損なわれます。
必要条件
- Unity Catalogでの特徴量エンジニアリング: Unity Catalogでの特徴量エンジニアリングクライアント(任意のバージョン)。
- ワークスペース特徴量ストア (レガシー): Feature Store クライアント v0.3.7 以降。
時間関連のキーを指定する方法
ポイントインタイム特徴量テーブルを使用するには、timeseries_columns引数( Unity Catalogでの特徴量エンジニアリングの場合)またはtimestamp_keys引数(ワークスペース Feature Storeの場合)を使用して、時間関連のキーを指定する必要があります。 これは、特徴量テーブルの行は、正確な時刻一致に基づいて結合するのではなく、 timestamps_keys 列の値より後の特定の主キーの最新の値を照合することによって結合する必要があることを示します。
timeseries_columns または timestamp_keysを使用せず、時系列列を主キー列として指定するだけの場合、Feature Store は結合中に時系列列にポイントインタイムロジックを適用しません。代わりに、タイムスタンプより前のすべての行に一致するのではなく、時刻が完全に一致する行のみに一致します。
Unity Catalog で時系列 特徴量テーブルを作成する
Unity Catalogでは、主キー がTIMESERIESテーブルであるテーブルは時系列特徴量テーブルです。時系列の特徴量テーブルを作成するには、「 Unity Catalogで特徴量テーブルを作成する」を参照してください。次の例は、さまざまなタイプの時系列テーブルを示しています。
時系列テーブルをオンライン ストアに公開する
タイムスタンプデータを含む特徴量テーブルを使用する場合は、オンライン配信の要件に応じて、タイムスタンプ列を timeseries_column として指定するか、通常の列として扱うかを検討する必要があります。
時系列指定 でマークされた タイムスタンプ列
timeseries_columnは、トレーニングデータセットの特定の時点の正確性が必要で、オンラインアプリケーションの特定のタイムスタンプの時点で最新の特徴値を検索する場合に使用します。時系列特徴量テーブルには 1 つのタイムスタンプキーが必要であり、パーティション列を含めることはできません。 タイムスタンプキー列は、 TimestampType または DateTypeである必要があります。
Databricks では、パフォーマンスの高い書き込みと参照を確保するために、時系列特徴量テーブルには 2 つ以下の主キー列を含めることをお勧めします。
- FeatureEngineeringClient API
- SQL API
fe = FeatureEngineeringClient()
# Create a time series table for point-in-time joins
fe.create_table(
name="catalog.schema.user_behavior_features",
primary_keys=["user_id", "event_timestamp"],
timeseries_columns="event_timestamp", # Enables point-in-time logic
df=features_df # DataFrame must contain primary keys and time series columns
)
-- Create table with time series constraint for point-in-time joins
CREATE TABLE catalog.schema.user_behavior_features (
user_id STRING NOT NULL,
event_timestamp TIMESTAMP NOT NULL, -- part of primary key and designated as TIMESERIES
purchase_amount DOUBLE,
page_views_last_hour INT,
CONSTRAINT pk_user_behavior PRIMARY KEY (user_id, event_timestamp TIMESERIES)
) USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true'
);
特徴量テーブルに、 timeseries_columnsを使用して時系列列として宣言されていないDATEまたはTIMESTAMP列が主キーとしてある場合、そのテーブルをcreate_feature_spec() 、 create_training_set() 、またはpublish_table()で使用することはできません。 これらのAPIs 、 DATEおよびTIMESTAMPすべての主キー列が時系列列として宣言されている必要があります。
使用例で日付またはタイムスタンプ値を単純な検索キーとして使用する必要がある場合(完全一致のセマンティクス、時点ロジックなし)、列の型をSTRINGに変更してください。
時系列 特徴量テーブルの更新
特徴量テーブルに特徴を書き込む場合、通常の特徴量テーブルとは異なり、 データフレーム は特徴量テーブルのすべての特徴量の値を指定する必要があります。 この制約により、時系列特徴量テーブル内のタイムスタンプ間での特徴値のスパース性が減少します。
- Feature Engineering in Unity Catalog
- Workspace Feature Store client v0.13.4 and above
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
時系列 特徴量テーブルへのストリーミング書き込みがサポートされています。
時系列 特徴量テーブルを持つトレーニングセットの作成
時系列特徴量テーブルから特徴量のポイントインタイムルックアップを実行するには、特徴量のFeatureLookupにtimestamp_lookup_keyを指定する必要があります。これは、時系列特徴量を検索するタイムスタンプを含むDataFrame列の名前を示します。Databricks Feature Store は、DataFrame の timestamp_lookup_key 列で指定されたタイムスタンプより前の最新の機能値を取得し、その主キー (タイムスタンプ キーを除く) が DataFrame の lookup_key 列の値と一致するか、そのような機能値が存在しない場合は null します。
- Feature Engineering in Unity Catalog
- Workspace Feature Store
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Photonが有効な場合にルックアップパフォーマンスを高速化するには、use_spark_native_join=TrueをFeatureEngineeringClient.create_training_setに渡します。これには databricks-feature-engineering バージョン0.6.0以降が必要です。
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
時系列 特徴量テーブル上のFeatureLookupはポイントインタイムルックアップである必要があるため、 データフレームで使用するtimestamp_lookup_key列を指定する必要があります。 ポイントインタイムルックアップでは、時系列特徴量テーブルに格納されている null 特徴値を持つ行はスキップされません。
過去の特徴値の時間制限を設定してください
Feature Store クライアント v0.13.0 以降、または Unity Catalogでの特徴量エンジニアリングの任意のバージョンでは、古いタイムスタンプを持つ特徴値をトレーニング セットから除外できます。 これを行うには、FeatureLookupのパラメーター lookback_window を使用します。
lookback_window のデータ タイプは datetime.timedeltaである必要があり、デフォルト値は None です (経過時間に関係なく、すべてのフィーチャ値が使用されます)。
たとえば、次のコードでは、7 日以上経過した機能値を除外します。
- Feature Engineering in Unity Catalog
- Workspace Feature Store
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
上記のFeatureLookupで create_training_set を呼び出すと、ポイントインタイム結合が自動的に実行され、7 日以上経過したフィーチャ値は除外されます。
ルックバック ウィンドウは、トレーニング中とバッチ推論中に適用されます。 オンライン推論では、ルックバック ウィンドウに関係なく、常に最新の特徴値が使用されます。
時系列特徴量テーブルによるモデルのスコアリング
時系列特徴量テーブルの特徴でトレーニングされたモデルをスコア付けすると、Databricks Feature Store は、トレーニング中にモデルと共にパッケージ化されたメタデータを使用して、ポイントインタイム ルックアップを使用して適切な特徴を取得します。 データフレームFeatureEngineeringClient.score_batchUnity CatalogFeatureStoreClient.score_batchFeature Store( Unity Catalogでの特徴量エンジニアリング) または (ワークスペース DataTypeのtimestamp_lookup_key場FeatureLookup合) に提供する には、 または に提供される の と同じ名前と のタイムスタンプ列が含まれている必要があFeatureEngineeringClient.create_training_setりFeatureStoreClient.create_training_setます。
Photonが有効な場合にルックアップパフォーマンスを高速化するには、use_spark_native_join=TrueをFeatureEngineeringClient.score_batchに渡します。これには databricks-feature-engineering バージョン0.6.0以降が必要です。
時系列特徴量をオンラインストアに公開する
FeatureEngineeringClient.publish_table ( Unity Catalogでの特徴量エンジニアリング) や FeatureStoreClient.publish_table (ワークスペース Feature Store) を使用して、時系列特徴量テーブルをオンラインストアに公開できます。 Databricks Feature Store には、オンラインストアのプロバイダーに応じて、スナップショットまたは時系列データのウィンドウをオンラインストアに公開する機能があります。 次の表に、各プロバイダーでサポートされているモードを示します。
オンラインストアプロバイダー | スナップショットモード | ウィンドウモード |
|---|---|---|
Amazon DynamoDB (v0.3.8 以降) | X | X |
Amazon Aurora (MySQL 互換) | X | |
Amazon RDS MySQL | X |
時系列スナップショットの公開
スナップショット・モードでは、 publish_table は特徴量テーブル内の各主キーの最新のフィーチャー値をパブリッシュします。 オンラインストアは主キー検索をサポートしていますが、ポイントインタイム検索はサポートしていません。
有効期限をサポートしていないオンラインストアの場合、Databricks Feature Store はスナップショット公開モードのみをサポートします。 有効期限をサポートするオンラインストアの場合、作成時にOnlineStoreSpecで有効期限(ttl)が指定されていない限り、デフォルトの公開モードはスナップショットです。
時系列ウィンドウの公開
ウィンドウ モードでは、 publish_table は特徴量テーブルの各主キーのすべての特徴値をオンラインストアに公開し、期限切れのレコードを自動的に削除します。 レコードのタイムスタンプ (UTC) が過去の指定された有効期限よりも長い場合、レコードは期限切れと見なされます。Time-to-Live の詳細については、クラウド固有のドキュメントを参照してください。
オンラインストアは主キー検索をサポートしており、最新のタイムスタンプで機能値を自動的に取得します。
ウィンドウ モードでは、オンライン ストアを作成するときに、OnlineStoreSpecで有効期限 (ttl) の値を指定する必要があります。一度設定した ttl は変更できません。 後続のすべてのパブリッシュ呼び出しは ttl を継承し、 OnlineStoreSpecで明示的に定義する必要はありません。
サンプルノートブック: 時系列特徴量テーブル
これらのノートブックの例は、時系列特徴量テーブルのポイントインタイムルックアップを示しています。
このノートブックは、Unity Catalog が有効になっているワークスペースで使用します。
時系列 特徴量テーブル サンプル ノートブック (Unity Catalog)
次のノートブックは、Unity Catalog が有効になっていないワークスペース用に設計されています。 ワークスペース Feature Store を使用します。