ワークスペース特徴量ストア(レガシー)
このドキュメントでは、ワークスペース Feature Store について説明します。 ワークスペース Feature Store は、2024 年 8 月 19 日 4:00:00 PM (UTC) より前に作成されたワークスペースでのみ使用できます。
Databricks での特徴量エンジニアリングUnity Catalogの使用を推奨しています。ワークスペース Feature Store は今後廃止される予定です。
ワークスペース Feature Store を使用する理由
ワークスペース Feature Store は、 Databricksの他のコンポーネントと完全に統合されています。
- 発見性:Databricks ワークスペースからアクセスできる Feature Store UI では、既存の特徴量を参照および検索できます。
- リネージ。Databricks で特徴量テーブルを作成すると、特徴量テーブルの作成に使用されたデータソースが保存され、アクセスできるようになります。 特徴量テーブルの各機能について、その機能を使用するモデル、ノートブック、ジョブ、エンドポイントにアクセスすることもできます。
- モデルのスコアリングやサービングとの統合:Feature Storeの特徴量を使用してモデルをトレーニングする場合、モデルは特徴量メタデータと一緒にパッケージ化されます。モデルをバッチスコアリングまたはオンライン推論に使用すると、Feature Storeから自動的に特徴量が取得されます。呼び出し側はこれらの特徴量について知る必要はありませんし、特徴量を検索または結合して新しいデータをスコアリングするロジックを組み込む必要もありません。これにより、モデルのデプロイメントや更新が容易になります。
- ポイントインタイムのルックアップ:Feature Store は、特定の時点での正確性を必要とする時系列およびイベントベースのユースケースをサポートします。
ワークスペース Feature Store はどのように機能しますか?
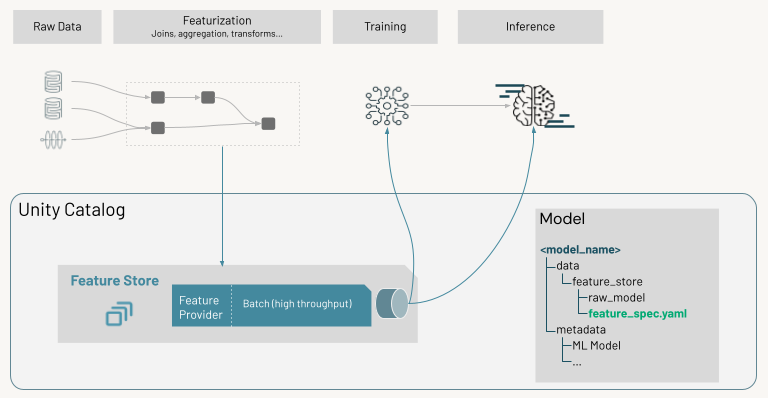
Feature Store を使用した一般的な機械学習ワークフローは、次のパスに従います。
- 生データを特徴に変換するコードを記述し、目的の特徴を含む Spark データフレーム を作成します。
- データフレームを特徴量テーブルとしてワークスペースFeature Storeに書き込みます。
- トレーニングする Feature Storeの特徴を使用するモデル . これを行うと、モデルはトレーニングに使用される特徴量の仕様を保存します。 モデルを推論に使用すると、適切な特徴量テーブルからの特徴量が自動的に結合されます。
- Model Registry年に登録する モデル .
これで、モデルを使用して新しいデータの予測を行うことができます。 バッチ使用の場合、モデルは必要な特徴量を Feature Store から自動的に取得します。
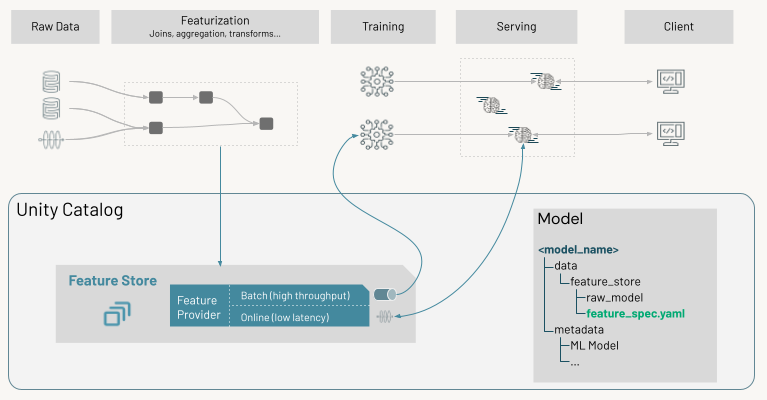
リアルタイム サービングの使用例では、機能をオンラインストアに公開します。 「Databricks Online Feature Stores」を参照してください。
推論時に、モデルはオンラインストアから 事前に計算された特徴量を読み取り、モデルサービング エンドポイントへのクライアント要求で提供されたデータと結合します。
ワークスペース Feature Store を使い始める
まず、これらのサンプルノートブックを試してください。 この基本的なコンピューター ステップでは、特徴量テーブルを作成し、それを使用してモデルをトレーニングし、自動特徴量検索を使用してバッチ スコアリングを実行する方法について説明します。 また、特徴量エンジニアリング UI を紹介し、それを使用して特徴量を検索する方法と、特徴量がどのように作成され使用されるかを理解する方法を示します。
基本的なワークスペース特徴量ストアのサンプルノートブック
タクシーのサンプルノートブックは、特徴量を作成し、それを更新し、モデルのトレーニングとバッチ推論に使用するプロセスを示しています。
ワークスペース Feature Store taxi example ノートブック
サポートされているデータ型
サポートされているデータ型については、「 サポートされているデータ型」を参照してください。